このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
CUDA 生成コードのパフォーマンス解析
この例では、関数 gpuPerformanceAnalyzer を使用して、CUDA® 生成コードのパフォーマンスを解析して最適化する方法を示します。
gpuPerformanceAnalyzer 関数はコードを生成し、生成されたコード内の CPU と GPU のアクティビティに関するメトリクスを収集します。関数は、CUDA 生成コードのパフォーマンス ボトルネックを可視化し、特定し、緩和するために使用できる時系列のタイムライン プロットを含むレポートを生成します。
この例では、霧修正アルゴリズムのパフォーマンス アナライザー レポートを生成します。詳細については、霧修正アルゴリズム用の GPU コードの生成を参照してください。
サードパーティの前提条件
CUDA 対応 NVIDIA® GPU。
NVIDIA CUDA Toolkit およびドライバー。サポートされているコンパイラおよびライブラリのバージョンの詳細については、サードパーティ ハードウェアを参照してください。
コンパイラおよびライブラリの環境変数。環境変数の設定については、前提条件となる製品の設定を参照してください。
GPU パフォーマンス カウンターにアクセスする権限。CUDA Toolkit v10.1 以降では、NVIDIA はパフォーマンス カウンターへのアクセスを管理者ユーザーのみに制限します。GPU パフォーマンス カウンターをすべてのユーザーに対して有効にするには、Permission issue with Performance Counters (NVIDIA) を参照してください。
GPU 環境の検証
この例に必要なコンパイラおよびライブラリが正しく設定されていることを検証するために、関数coder.checkGpuInstallを使用します。
envCfg = coder.gpuEnvConfig("host");
envCfg.BasicCodegen = 1;
envCfg.Quiet = 1;
coder.checkGpuInstall(envCfg);coder.gpuEnvConfig オブジェクトの Quiet プロパティが true の場合、coder.checkGpuInstall 関数は警告メッセージまたはエラー メッセージのみを返します。
霧修正アルゴリズムの確認
この例では、霧のかかった RGB イメージを入力として受け取ります。霧のかかった入力イメージを改善するために、アルゴリズムでは霧の除去とコントラストの強調を実行します。図は、これら両方の演算手順を示しています。

霧の除去を実行するために、アルゴリズムではイメージのダーク チャネルを推定し、ダーク チャネルに基づいて大気光マップを計算し、フィルターを使用して大気光マップを調整します。復元段階で、入力イメージから調整済みの大気光マップを差し引くことにより、霧が取り除かれたイメージを作成します。
コントラストを強調するために、アルゴリズムは復元されたイメージをグレースケールに変換し、イメージ内の強度値のヒストグラムを作成します。ヒストグラムを正規化した後、強度値の累積密度関数 (CDF) を計算します。このアルゴリズムはコントラスト ストレッチを使用して値の範囲を拡大し、出力イメージで特徴をより明確に際立たせます。
type fog_rectification.mfunction [out] = fog_rectification(input) %#codegen
%
% Copyright 2017-2023 The MathWorks, Inc.
coder.gpu.kernelfun;
% restoreOut is used to store the output of restoration
restoreOut = zeros(size(input),"double");
% Changing the precision level of input image to double
input = double(input)./255;
%% Dark channel Estimation from input
darkChannel = min(input,[],3);
% diff_im is used as input and output variable for anisotropic
% diffusion
diff_im = 0.9*darkChannel;
num_iter = 3;
% 2D convolution mask for Anisotropic diffusion
hN = [0.0625 0.1250 0.0625; 0.1250 0.2500 0.1250;
0.0625 0.1250 0.0625];
hN = double(hN);
%% Refine dark channel using Anisotropic diffusion.
for t = 1:num_iter
diff_im = conv2(diff_im,hN,"same");
end
%% Reduction with min
diff_im = min(darkChannel,diff_im);
diff_im = 0.6*diff_im ;
%% Parallel element-wise math to compute
% Restoration with inverse Koschmieder's law
factor = 1.0./(1.0-(diff_im));
restoreOut(:,:,1) = (input(:,:,1)-diff_im).*factor;
restoreOut(:,:,2) = (input(:,:,2)-diff_im).*factor;
restoreOut(:,:,3) = (input(:,:,3)-diff_im).*factor;
restoreOut = uint8(255.*restoreOut);
%%
% Stretching performs the histogram stretching of the image.
% im is the input color image and p is cdf limit.
% out is the contrast stretched image and cdf is the cumulative
% prob. density function and T is the stretching function.
% RGB to grayscale conversion
im_gray = im2gray(restoreOut);
[row,col] = size(im_gray);
% histogram calculation
[count,~] = imhist(im_gray);
prob = count'/(row*col);
% cumulative Sum calculation
cdf = cumsum(prob(:));
% Utilize gpucoder.reduce to find less than particular probability.
% This is equal to "i1 = length(find(cdf <= (p/100)));", but is
% more GPU friendly.
% lessThanP is the preprocess function that returns 1 if the input
% value from cdf is less than the defined threshold and returns 0
% otherwise. gpucoder.reduce then sums up the returned values to get
% the final count.
i1 = gpucoder.reduce(cdf,@plus,"preprocess", @lessThanP);
i2 = 255 - gpucoder.reduce(cdf,@plus,"preprocess", @greaterThanP);
o1 = floor(255*.10);
o2 = floor(255*.90);
t1 = (o1/i1)*[0:i1];
t2 = (((o2-o1)/(i2-i1))*[i1+1:i2])-(((o2-o1)/(i2-i1))*i1)+o1;
t3 = (((255-o2)/(255-i2))*[i2+1:255])-(((255-o2)/(255-i2))*i2)+o2;
T = (floor([t1 t2 t3]));
restoreOut(restoreOut == 0) = 1;
u1 = (restoreOut(:,:,1));
u2 = (restoreOut(:,:,2));
u3 = (restoreOut(:,:,3));
% replacing the value from look up table
out1 = T(u1);
out2 = T(u2);
out3 = T(u3);
out = zeros([size(out1),3], "uint8");
out(:,:,1) = uint8(out1);
out(:,:,2) = uint8(out2);
out(:,:,3) = uint8(out3);
end
function out = lessThanP(input)
p = 5/100;
out = uint32(0);
if input <= p
out = uint32(1);
end
end
function out = greaterThanP(input)
p = 5/100;
out = uint32(0);
if input >= 1 - p
out = uint32(1);
end
end
GPU パフォーマンス アナライザー レポートの生成
関数 gpuPerformanceAnalyzer を使用して生成コードのパフォーマンスを解析するには、入力引数 dll を使用し、ダイナミック ライブラリ ビルド タイプでコード構成オブジェクトを作成します。coder.EmbeddedCodeConfig 構成オブジェクトを作成するオプションを有効にします。
cfg = coder.gpuConfig("dll","ecoder",true);
既定の反復回数 2 で gpuPerformanceAnalyzer を実行します。
inputImage = imread("foggyInput.png"); inputs = {inputImage}; designFileName = "fog_rectification"; gpuPerformanceAnalyzer(designFileName,inputs, ... Config=cfg,NumIterations=2);
### Starting GPU code generation
Code generation successful: View report
### GPU code generation finished
### Starting application profiling
### Starting SIL execution for 'fog_rectification'
To terminate execution: clear fog_rectification_sil
### Application stopped
### Stopping SIL execution for 'fog_rectification'
### Application profiling finished
### Starting profiling data processing
### Profiling data processing finished
### Showing profiling data
あるいは、codegen コマンドの -gpuprofile オプションを使用すると、GPU プロファイリングを有効にして、GPU パフォーマンス アナライザー レポートを作成することができます。
codegen -config cfg -gpuprofile fog_rectification.m -args inputs
コード生成が完了すると、ソフトウェアはソフトウェアインザループ (SIL) 実行可能ファイル fog_rectification_sil を生成します。SIL 実行を実施するには、MATLAB® コマンド ウィンドウに次のコードを入力します。
fog_rectification_sil(inputImage);
SIL 実行を終了するには、MATLAB コマンド ウィンドウで clear fog_rectification_sil リンクをクリックします。GPU パフォーマンス アナライザー レポートは、SIL 実行可能ファイルを終了した後、利用可能になります。
### Application stopped
### Stopping SIL execution for 'fog_rectification'
### Starting profiling data processing
### Profiling data processing finished
Open GPU Performance Analyzer report: open('/home/test/gpucoder-ex87489778/codegen/dll/fog_rectification/html/gpuProfiler.mldatx')
GPU パフォーマンス アナライザー レポート
GPU パフォーマンス アナライザー レポートには、GPU と CPU のアクティビティ、イベント、パフォーマンス メトリクスが時系列のタイムライン プロットで一覧表示されます。これらは、CUDA 生成コードのパフォーマンス ボトルネックを可視化し、特定し、対処するために使用できます。
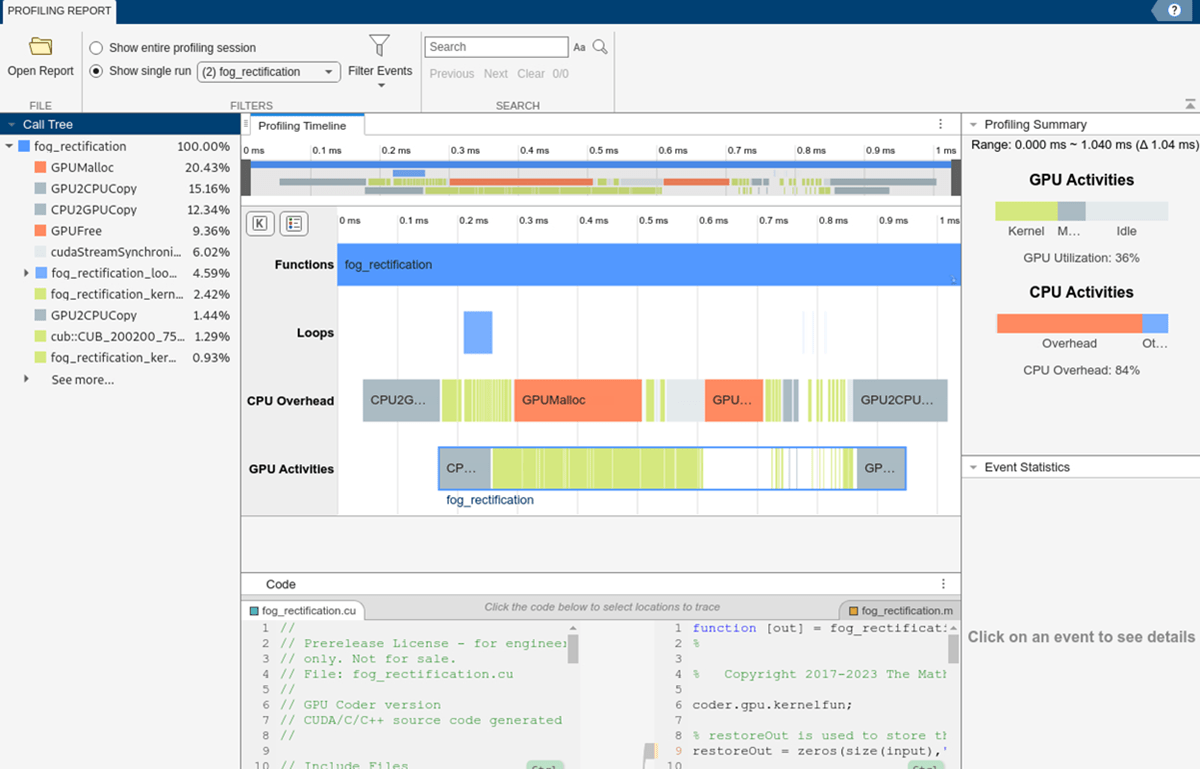
これらの数値は代表的なものです。実際の値はハードウェア設定によって異なります。この例のプロファイリングは、12 コアの 3.6GHz Intel® Xeon® CPU および NVIDIA Quadro RTX 6000 GPU を搭載したマシンで MATLAB R2024b を使用して行われました。
プロファイリング タイムライン
プロファイリング タイムラインには、実行時間がしきい値を上回るすべてのイベントの完全なトレースが表示されます。次のイメージは、しきい値が 0.0 ms の場合のプロファイリング トレースのスニペットを示しています。
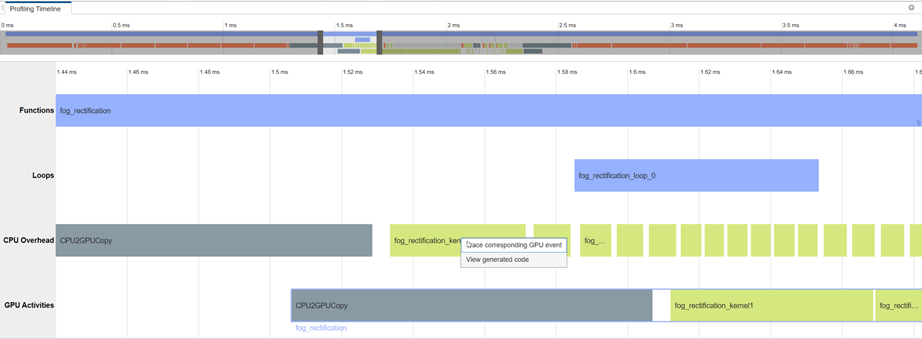
マウス ホイールまたは同等のタッチパッド オプションを使用して、タイムラインのズーム レベルを制御できます。あるいは、パネル上部にあるタイムラインの概要を使用して、ズーム レベルを制御したり、タイムライン プロットを操作したりすることもできます。
各イベントのツールヒントは、CPU と GPU 上での選択されたイベントの開始時間、終了時間、および持続時間を示します。ツールヒントは、CPU でカーネルが起動されてから GPU で実際にカーネルが実行されるまでの経過時間も示します。

イベントを右クリックしてコンテキスト メニューを開き、CPU イベントと対応する GPU イベントの間でトレースを追加します。コンテキスト メニューを使用して、コード ペイン上のイベントに対応する CUDA 生成コードを表示することもできます。
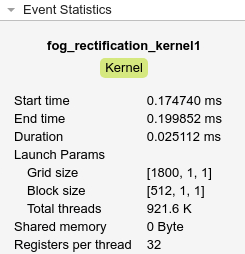
イベント統計
[イベント統計] ペインには、選択したイベントの追加情報が表示されます。たとえば、fog_rectification_kernel1 は、開始時間、終了時間、起動パラメーター、共有メモリ、スレッドあたりのレジスタ数など、カーネルに関する情報を表示します。
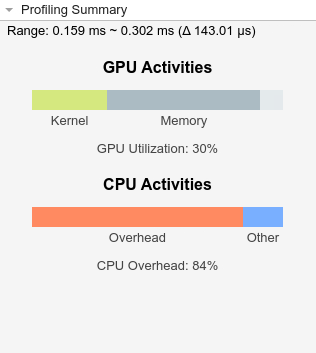
プロファイリングの概要
[プロファイリングの概要] ペインには、GPU と CPU のアクティビティの概要を示す棒グラフが含まれます。棒グラフは、プロファイリング タイムラインのズーム レベルに応じて変化します。次のイメージは、タイムラインで選択された領域のプロファイリングの概要のスニペットを示しています。
コードのトレース
[コード] ペインを使用して、MATLAB コードから CUDA コードへのトレース、または CUDA コードから MATLAB コードへのトレースを行うことができます。追跡可能なコードは、トレース元の側で青色、トレース先の側でオレンジ色になります。追跡可能なコードにポインターを移動すると、ペインでそのコードが紫色で強調表示され、対応するもう一方のコードがトレースされます。コード セクションを選択すると、ペインではコードが黄色で強調表示されます。コードは、"Esc" を押すか、別のコードを選択するまで、選択されたままになります。トレース元を変更するには、もう一方のコードを選択します。

トレースを調べるには、プロファイリング タイムラインの [ループ] 行で fog_rectification_loop0 イベントを右クリックし、[生成されたコードの表示] を選択します。このアクションにより、for ループとそれに対応する MATLAB コードが強調表示されます。
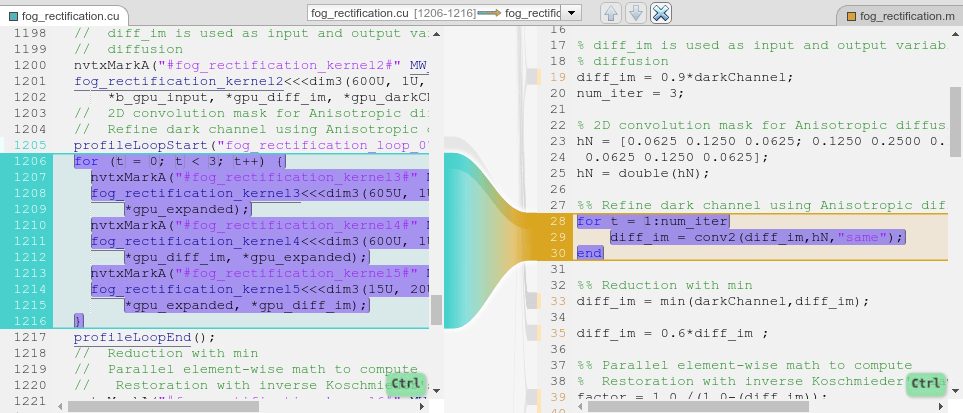
MATLAB コード ペインで、MATLAB 関数の先頭までスクロールして、トレースが表示されないようにします。トレース ビュー アイコン ![]() は、強調表示された CUDA コードに表示されていないトレースが 1 つあることを示しています。
は、強調表示された CUDA コードに表示されていないトレースが 1 つあることを示しています。

選択をクリアするには、"Esc" を押すか、別のコードを選択します。
対応するソース内または生成コード内の複数の場所をコードがトレースする場合:
トレースしているコードの上で一時停止すると、コード ペインの上部にトレースの数が表示されます。
一部のトレースが表示されていない場合は、トレース ビュー アイコンに、表示されていないトレースの数が示されます。
トレースするコードをコード ペインで選択した場合、表示するトレースをコード ペインの上部で選択することができます。

呼び出しツリー
このセクションでは、CPU から呼び出される GPU イベントを一覧表示します。呼び出しツリーの各イベントには、呼び出し元関数の実行時間が割合として一覧表示されます。このメトリクスは、生成されたコードのパフォーマンス ボトルネックを特定するのに役立ちます。呼び出しツリーで対応するイベントをクリックして、プロファイリング タイムラインの特定のイベントに移動することもできます。
フィルター
このセクションでは、レポートのフィルター処理オプションを提供します。[プロファイリング セッション全体を表示] を選択して、初期化と終了を含むアプリケーション全体のプロファイリング結果を表示します。または、[1 回の実行を表示] を選択して、設計関数の個々の実行からの結果を表示します。
[イベントのフィルター処理] では、次でフィルター処理することもできます。
イベントしきい値 — 指定されたしきい値より短いイベントをスキップします。
メモリの割り当て/解放 — GPU デバイスのメモリ割り当てと割り当て解除に関連するイベントを CPU アクティビティ バーに表示します。
メモリ転送 — ホストからデバイス、およびデバイスからホストへのメモリ転送を表示します。
カーネル — CPU カーネルの起動と GPU カーネルのアクティビティを表示します。
他のイベント — 同期や GPU の待機など、その他の GPU 関連イベントを表示します。