このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
深層学習ネットワーク用の生成コードのパフォーマンス解析
この例では、gpuPerformanceAnalyzer 関数を使用して、深層学習ネットワーク用に生成された CUDA® コードのパフォーマンスを解析して最適化する方法を示します。
gpuPerformanceAnalyzer 関数はコードを生成し、生成されたコード内の CPU と GPU のアクティビティに関するメトリクスを収集します。関数は、CUDA 生成コードのパフォーマンス ボトルネックを可視化し、特定し、緩和するために使用できる時系列のタイムライン プロットを含むレポートを生成します。
この例では、深層学習変分自己符号化器 (VAE) を使用して数字イメージを生成する関数について、パフォーマンス解析レポートを生成します。詳細については、変分自己符号化器を使用した NVIDIA GPU での数字イメージの生成を参照してください。
サードパーティの前提条件
CUDA 対応 NVIDIA® GPU。
NVIDIA CUDA Toolkit およびドライバー。サポートされているコンパイラおよびライブラリのバージョンの詳細については、サードパーティ ハードウェアを参照してください。
コンパイラおよびライブラリの環境変数。環境変数の設定は、前提条件となる製品の設定を参照してください。
GPU パフォーマンス カウンターにアクセスする権限。CUDA Toolkit v10.1 以降では、NVIDIA はパフォーマンス カウンターへのアクセスを管理者ユーザーのみに制限します。GPU パフォーマンス カウンターをすべてのユーザーに対して有効にするには、Permission issue with Performance Counters (NVIDIA) を参照してください。
GPU 環境の検証
この例のためにコンパイラおよびライブラリが正しく設定されていることを確認するために、関数coder.checkGpuInstallを使用します。
envCfg = coder.gpuEnvConfig("host"); envCfg.DeepLibTarget = "cudnn"; envCfg.DeepCodegen = 1; envCfg.Quiet = 1; coder.checkGpuInstall(envCfg);
coder.gpuEnvConfig オブジェクトの Quiet プロパティが true に設定されている場合、coder.checkGpuInstall 関数は警告またはエラー メッセージのみを返します。
事前学習済みの変分自己符号化器ネットワークの解析
自己符号化器には、符号化器と復号化器の 2 つの部分があります。符号化器はイメージ入力を受け取り、圧縮表現を出力します。復号化器はこの圧縮表現を受け取り、復号化して元のイメージを再作成します。
VAE は入力の再構成に符号化と復号化の処理を行わないという点で、通常の自己符号化器と異なります。代わりに、潜在空間上に確率分布を適用してその分布を学習することで、復号化器からの出力の分布と観測データの分布を一致させます。その後、この分布からサンプリングして新しいデータを生成します。
この例では、変分自己符号化器 (VAE) の学習によるイメージ生成 (Deep Learning Toolbox)の例で学習させた復号化器ネットワークを使用します。符号化器は、サイズ latent_dim のベクトルである圧縮表現を出力します。この例では、latent_dim の値は 20 に等しくなります。
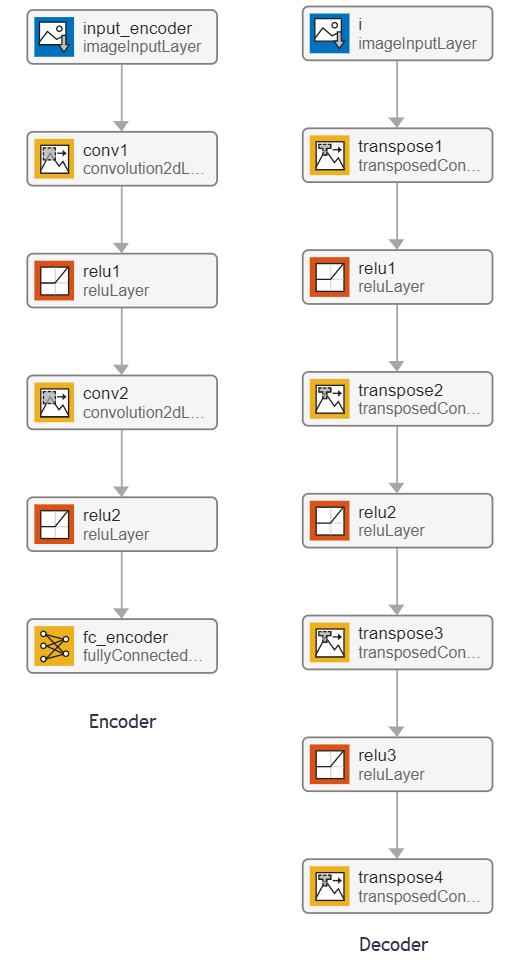
エントリポイント関数の確認
エントリポイント関数 generateVAE は、dlnetwork オブジェクトを trainedDecoderVAENet MAT ファイルから永続変数に読み込み、以降の予測呼び出し時にその永続オブジェクトを再利用します。ランダムに生成された 25 個の符号化を含む dlarray オブジェクトを初期化し、それらを復号化器ネットワークに渡し、生成されたイメージの数値データを深層学習配列オブジェクトから抽出します。
type("generateVAE.m")function generatedImage = generateVAE(decoderNetFileName,latentDim,Environment) %#codegen
% Copyright 2020-2021 The MathWorks, Inc.
persistent decoderNet;
if isempty(decoderNet)
decoderNet = coder.loadDeepLearningNetwork(decoderNetFileName);
end
% Generate random noise
randomNoise = dlarray(randn(1,1,latentDim,25,'single'),'SSCB');
if coder.target('MATLAB') && strcmp(Environment,'gpu')
randomNoise = gpuArray(randomNoise);
end
% Generate new image from noise
generatedImage = sigmoid(predict(decoderNet,randomNoise));
% Extract numeric data from dlarray
generatedImage = extractdata(generatedImage);
end
GPU パフォーマンス アナライザー レポートの生成
生成されたコードのパフォーマンスを解析するには、gpuPerformanceAnalyzer 関数を使用します。まず、dll 入力引数を使用し、ダイナミック ライブラリ ビルド タイプでコード構成オブジェクトを作成します。coder.EmbeddedCodeConfig 構成オブジェクトを作成するオプションを有効にします。
cfg = coder.gpuConfig("dll","ecoder",true);
関数coder.DeepLearningConfigを使用して CuDNN 深層学習構成オブジェクトを作成し、それを GPU コード構成オブジェクトの DeepLearningConfig プロパティに割り当てます。
cfg.TargetLang = "C++"; cfg.GpuConfig.EnableMemoryManager = true; cfg.DeepLearningConfig = coder.DeepLearningConfig("cudnn");
既定の反復回数 2 で gpuPerformanceAnalyzer を実行します。GPU パフォーマンス アナライザーは、両方の反復とプロファイリング セッション全体に関するパフォーマンス データを収集します。
latentDim = 20; Env = "gpu"; matfile = "trainedDecoderVAENet.mat"; inputs = {coder.Constant(matfile), coder.Constant(latentDim), coder.Constant(Env)}; designFileName = "generateVAE"; gpuPerformanceAnalyzer(designFileName, inputs, ... "Config", cfg, "NumIterations", 2);
### Starting GPU code generation
Code generation successful: View report
### GPU code generation finished
### Starting application profiling
### Starting SIL execution for 'generateVAE'
To terminate execution: clear generateVAE_sil
### Application stopped
### Stopping SIL execution for 'generateVAE'
### Application profiling finished
### Starting profiling data processing
### Profiling data processing finished
### Showing profiling data
codegen を使用したパフォーマンス アナライザー レポートの生成
codegen コマンドの -gpuprofile オプションを使用すると、GPU プロファイリングを有効にして、GPU パフォーマンス アナライザー レポートを作成することができます。次に例を示します。
codegen -config cfg -gpuprofile generateVAE.m -args inputs
コード生成が完了すると、ソフトウェアは実行可能ファイル generateVAE_sil を生成します。これは、生成されたコード内の CPU と GPU のアクティビティを測定するソフトウェアインザループ (SIL) 実行可能ファイルです。SIL 実行可能ファイルを実行します。
generateVAE_sil(matFile,latentDim,Env);
MATLAB® コマンド ウィンドウで clear generateVAE_sil のリンクをクリックします。GPU パフォーマンス アナライザー レポートは、SIL 実行可能ファイルを終了した後、コマンド ウィンドウのリンクとして利用可能になります。次に例を示します。
### Application stopped
### Stopping SIL execution for 'fog_rectification'
### Starting profiling data processing
### Profiling data processing finished
Open GPU Performance Analyzer report: open('/home/test/gpucoder-ex87489778/codegen/dll/fog_rectification/html/gpuProfiler.mldatx')
GPU パフォーマンス アナライザー
GPU パフォーマンス アナライザー レポートには、GPU と CPU のアクティビティ、イベント、パフォーマンス メトリクスが時系列のタイムライン プロットで一覧表示されます。これらは、CUDA 生成コードのパフォーマンス ボトルネックを可視化し、特定し、対処するために使用できます。
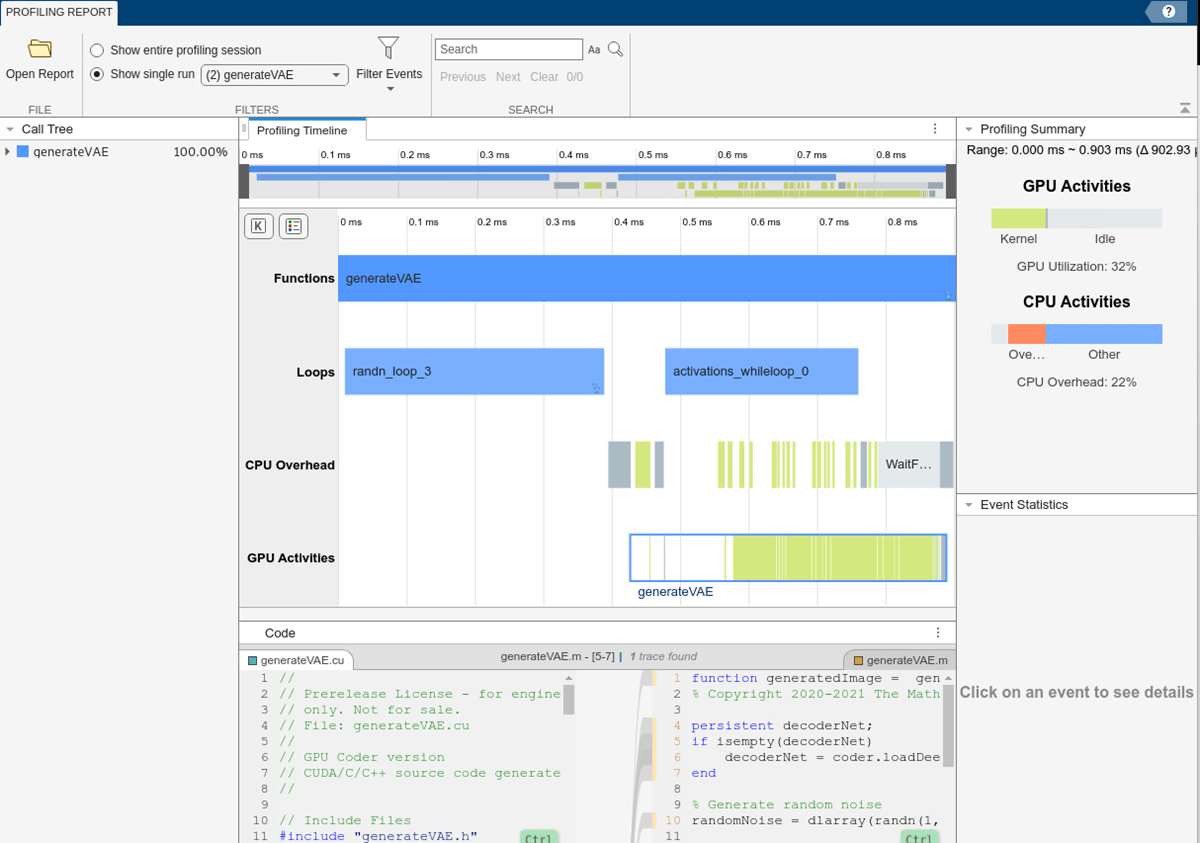
これらの数値は代表的なものです。実際の値はハードウェア設定によって異なります。この例のプロファイリングは、12 コアの 3.6GHz Intel® Xeon® CPU および NVIDIA Quadro RTX 6000 GPU を搭載したマシンで MATLAB® R2024b を使用して行われました。
プロファイリング タイムライン
プロファイリング タイムラインには、実行時間がしきい値を上回るすべてのイベントの完全なトレースが表示されます。次のイメージは、しきい値が 0.0 ms に設定されている場合のプロファイリング トレースのスニペットを示しています。
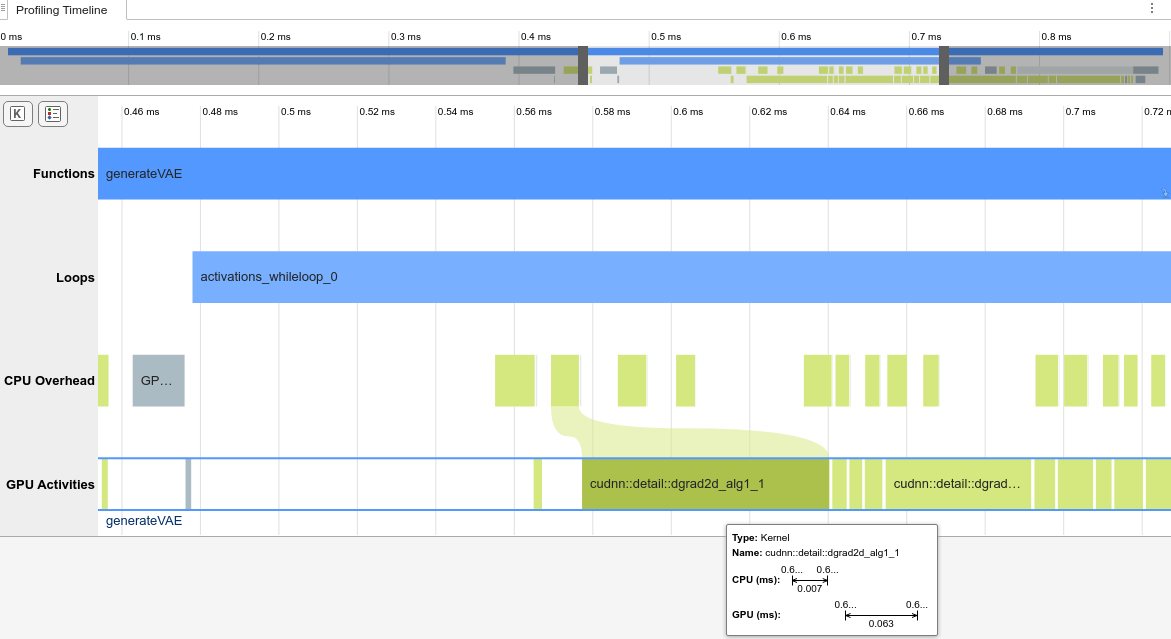
マウス ホイールまたは同等のタッチパッド オプションを使用して、タイムラインのズーム レベルを制御できます。あるいは、パネル上部にあるタイムラインの概要を使用して、ズーム レベルを制御したり、タイムライン プロットを操作したりすることもできます。
各イベントのツールヒントは、CPU と GPU 上での選択されたイベントの開始時間、終了時間、および持続時間を示します。ツールヒントは、CPU でカーネルが起動されてから GPU で実際にカーネルが実行されるまでの経過時間も示します。

イベントを右クリックしてコンテキスト メニューを開き、CPU イベントと対応する GPU イベントの間でトレースを追加します。コンテキスト メニューを使用して、コード ペイン上のイベントに対応する CUDA 生成コードを表示することもできます。
イベント統計
[イベント統計] ペインには、選択したイベントの追加情報が表示されます。たとえば、Crop2dImpl カーネルを選択すると、Crop2dImpl の開始時間、終了時間、持続時間、起動パラメーター、共有メモリ、スレッドあたりのレジスタ数などの統計情報が表示されます。

プロファイリングの概要
[プロファイリングの概要] ペインには、GPU と CPU のアクティビティの概要を示す棒グラフが含まれます。棒グラフは、プロファイリング タイムラインのズーム レベルに応じて変化します。次のイメージは、プロファイリングの概要のスニペットを示しています。タイムラインで選択された領域内で、GPU 使用率が 54% であることを示しています。
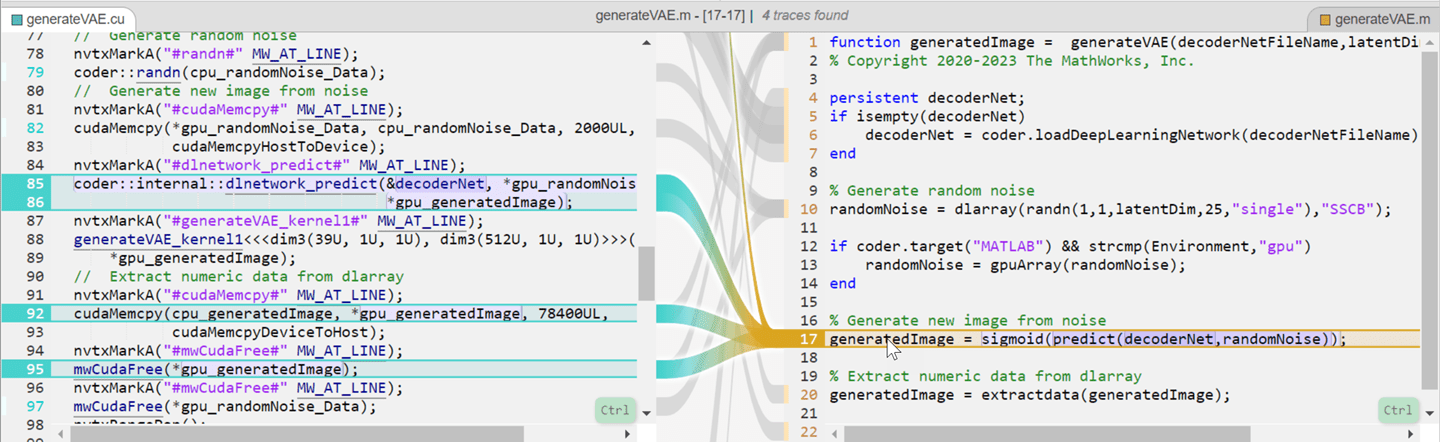
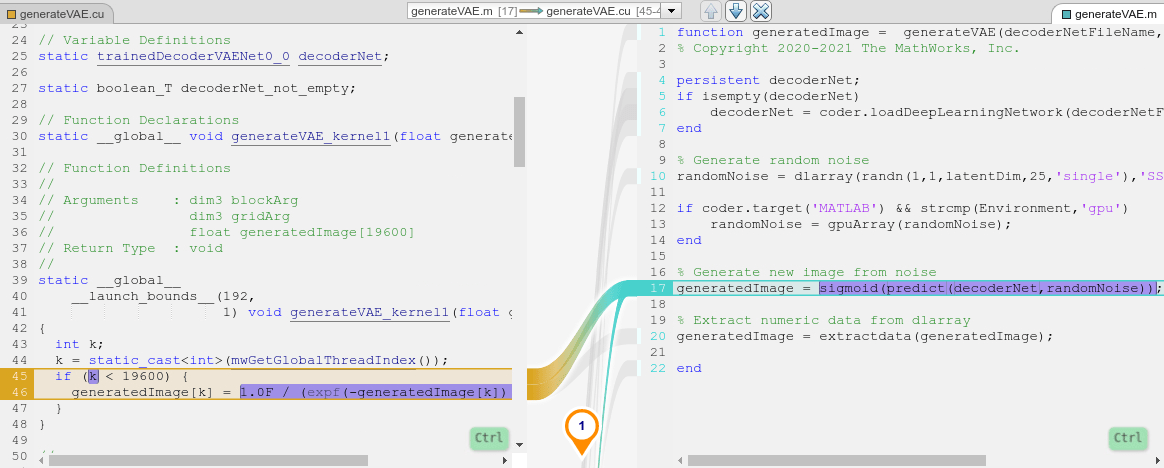
コードのトレース
[コード] ペインを使用して、MATLAB® コードから CUDA コードへのトレース、または CUDA コードから MATLAB コードへのトレースを行うことができます。追跡可能なコードは、トレース元の側で青色、トレース先の側でオレンジ色になります。トレース可能なコードをポイントすると、ペインでそのコードが紫色で強調表示され、対応するもう一方のコードがトレースされます。コード セクションを選択すると、ペインではコードが黄色で強調表示されます。コードは、"Esc" を押すか、別のコードを選択するまで、選択されたままになります。トレース元を変更するには、もう一方のコードを選択します。
呼び出しツリー
このセクションでは、CPU から呼び出される GPU イベントを一覧表示します。呼び出しツリーの各イベントには、呼び出し元関数の実行時間が割合として一覧表示されます。このメトリクスは、生成されたコードのパフォーマンス ボトルネックを特定するのに役立ちます。呼び出しツリーで対応するイベントをクリックして、プロファイリング タイムラインの特定のイベントに移動することもできます。
フィルター
このセクションでは、レポートのフィルター処理オプションを提供します。[プロファイリング セッション全体を表示] を選択して、初期化と終了を含むアプリケーション全体のプロファイリング結果を表示します。あるいは、[1 回の実行を表示] を選択して、設計関数の個々の実行からの結果を表示します。
[イベントのフィルター処理] では、以下を指定できます。
イベントしきい値 — 指定されたしきい値より短いイベントをスキップします。
メモリの割り当て/解放 — GPU デバイスのメモリ割り当てと割り当て解除に関連するイベントを CPU アクティビティ バーに表示します。
メモリ転送 — ホストからデバイス、およびデバイスからホストへのメモリ転送を表示します。
カーネル — CPU カーネルの起動と GPU カーネルのアクティビティを表示します。
その他 — 同期や GPU の待機など、その他の GPU 関連イベントを表示します。