gpuPerformanceAnalyzer
説明
gpuPerformanceAnalyzer( は、MATLAB® エントリポイント関数 fcn, fcn_inputs)fcn 用の GPU コードを生成し、コード実行のプロファイリング プロットとレポートを通じてパフォーマンスを分析します。fcn_inputs は、コード生成および実行プロファイリングの際に使用される fcn に対するサンプル値から成る cell 配列です。
gpuPerformanceAnalyzer(___, は GPU コードを生成し、1 つ以上の Name=Value)Name=Value ペアの引数で指定されたオプションを使用し、コード実行のプロファイリング プロットとレポートを通じてパフォーマンスを解析します。
例
この例では、gpuPerformanceAnalyzer を使用して、マンデルブロ アルゴリズム用に生成された CUDA® コードのパフォーマンスを解析する方法を示します。
マンデルブロ集合とは、下記の方程式で定義された軌跡が k→∞ のときに有限の範囲内にとどまる値 z0 で構成された複素平面の領域です。
マンデルブロ集合の全体的な幾何形状を図に示しています。この図には、集合の境界の外側周辺における詳しい構造を十分に示すための解像度がありません。拡大率を上げていくと、マンデルブロ集合の詳細な境界が示され、そこでは徐々に細かくなりながら細部が繰り返されていることがわかります。
この例では、メインのカージオイドとその左側にある p/q 球状部との谷間にある、マンデルブロ集合の大きく拡大された部分を指定する一連の範囲を選択します。これらの 2 つの範囲間に、実数部 (x) と虚数部 (y) の 1000 x 1000 のグリッドを作成します。次に、マンデルブロ アルゴリズムを各グリッド位置で反復します。500 回の反復回数で、完全な解像度のイメージがレンダリングされます。
maxIterations = 500; gridSize = 1000; xlim = [-0.748766713922161,-0.748766707771757]; ylim = [0.123640844894862,0.123640851045266]; x = linspace( xlim(1), xlim(2), gridSize ); y = linspace( ylim(1), ylim(2), gridSize ); [xGrid,yGrid] = meshgrid( x, y );
エントリポイント関数 mandelbrot_count.m には、マンデルブロ集合のベクトル化済みの実装が含まれています。
function count = mandelbrot_count(maxIterations, xGrid, yGrid) %#codegen z0 = complex(xGrid,yGrid); count = ones(size(z0)); % Map computation to GPU. coder.gpu.kernelfun; z = z0; for n = 0:maxIterations z = z.*z + z0; inside = abs(z)<=2; count = count + inside; end count = log(count);
mandelbrot_count の CUDA コードを生成し、そのパフォーマンスを分析するには、関数 gpuPerformanceAnalyzer を使用します。
cfg = coder.gpuConfig('dll'); cfg.GpuConfig.CompilerFlags = '--fmad=false'; cfg.GpuConfig.EnableMemoryManager = true; gpuPerformanceAnalyzer('mandelbrot_count', ... {maxIterations,xGrid,yGrid},Config=cfg, ... NumIterations=2,OutFolder="PerfTest");
### Starting GPU code generation
Code generation successful: View report
### GPU code generation finished
### Starting SIL execution for 'mandelbrot_count'
To terminate execution: clear mandelbrot_count_sil
### Stopping SIL execution for 'mandelbrot_count'
### Starting profiling data processing
### Profiling data processing finished
### Showing profiling data
プロファイリング データを収集した後、gpuPerformanceAnalyzer は GPU パフォーマンス アナライザー レポート ウィンドウを起動します。
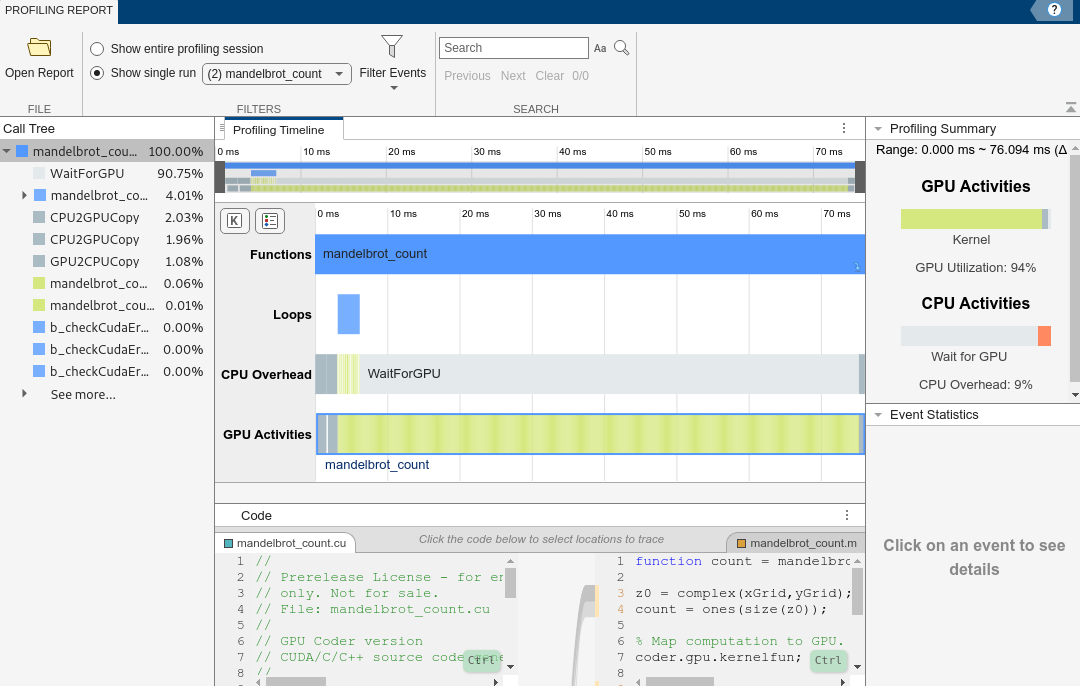
入力引数
名前と値の引数
制限
NVIDIA® のプロファイリング ツールは、Kepler ファミリ デバイスなどのレガシ GPU ハードウェアをサポートしていません。サポートされている GPU デバイスについては、NVIDIA のドキュメンテーションを参照してください。
バージョン履歴
R2023a で導入