dlgradient
自動微分を使用したカスタム学習ループの勾配の計算
説明
dlgradient 関数は自動微分を使用して微分を計算します。
ヒント
ほとんどの深層学習タスクでは、事前学習済みのニューラル ネットワークを使用して独自のデータに適応させることができます。転移学習を使用して、畳み込みニューラル ネットワークの再学習を行い、新しい一連のイメージを分類する方法を示す例については、新しいイメージを分類するためのニューラル ネットワークの再学習を参照してください。または、関数 trainnet と関数 trainingOptions を使用してニューラル ネットワークを作成し、これにゼロから学習させることができます。
タスクに必要な学習オプションが関数 trainingOptions に用意されていない場合、自動微分を使用してカスタム学習ループを作成できます。詳細については、カスタム学習ループを使用したネットワークの学習を参照してください。
タスクに必要な損失関数が関数 trainnet に用意されていない場合、カスタム損失関数を関数ハンドルとして trainnet に指定できます。損失関数が予測とターゲットよりも多くの入力を必要とする場合 (たとえば、損失関数がニューラル ネットワークまたは追加の入力にアクセスする必要がある場合)、カスタム学習ループを使用してモデルに学習させます。詳細については、カスタム学習ループを使用したネットワークの学習を参照してください。
タスクに必要な層が Deep Learning Toolbox™ に用意されていない場合、カスタム層を作成できます。詳細については、カスタム深層学習層の定義を参照してください。層のネットワークとして指定できないモデルの場合は、モデルを関数として定義できます。詳細については、モデル関数を使用したネットワークの学習を参照してください。
どのタスクでどの学習手法を使用するかについての詳細は、MATLAB による深層学習モデルの学習を参照してください。
[ は、変数 dydx1,...,dydxk] = dlgradient(y,x1,...,xk)x1 ~ xk に対する y の勾配を返します。
dlfeval に渡された関数の内部から dlgradient を呼び出します。自動微分を使用した勾配の計算とDeep Learning Toolbox での自動微分の使用を参照してください。
[ は、勾配を返し、1 つ以上の名前と値のペアを使用して追加のオプションを指定します。たとえば、dydx1,...,dydxk] = dlgradient(y,x1,...,xk,Name,Value)dydx = dlgradient(y,x,'RetainData',true) は、後続の dlgradient の呼び出しで再利用できるように、勾配の中間値を保持します。この構文を使用すると時間を節約できますが、より多くのメモリが使用されます。詳細については、ヒントを参照してください。
例
Rosenbrock 関数は、最適化の標準的なテスト関数です。補助関数 rosenbrock.m は、関数の値を計算し、自動微分を使用してその勾配を計算します。
type rosenbrock.mfunction [y,dydx] = rosenbrock(x) y = 100*(x(2) - x(1).^2).^2 + (1 - x(1)).^2; dydx = dlgradient(y,x); end
点 [–1,2] における Rosenbrock 関数とその勾配を評価するには、その点の dlarray を作成してから、関数ハンドル @rosenbrock を指定して dlfeval を呼び出します。
x0 = dlarray([-1,2]); [fval,gradval] = dlfeval(@rosenbrock,x0)
fval = 1×1 dlarray 104
gradval = 1×2 dlarray 396 200
または、2 つの入力 x1 および x2 をもつ関数として Rosenbrock 関数を定義します。
type rosenbrock2.mfunction [y,dydx1,dydx2] = rosenbrock2(x1,x2) y = 100*(x2 - x1.^2).^2 + (1 - x1).^2; [dydx1,dydx2] = dlgradient(y,x1,x2); end
入力 –1 および 2 を表す 2 つの dlarray 引数を指定して dlfeval を呼び出し、rosenbrock2 を評価します。
x1 = dlarray(-1); x2 = dlarray(2); [fval,dydx1,dydx2] = dlfeval(@rosenbrock2,x1,x2)
fval = 1×1 dlarray 104
dydx1 = 1×1 dlarray 396
dydx2 = 1×1 dlarray 200
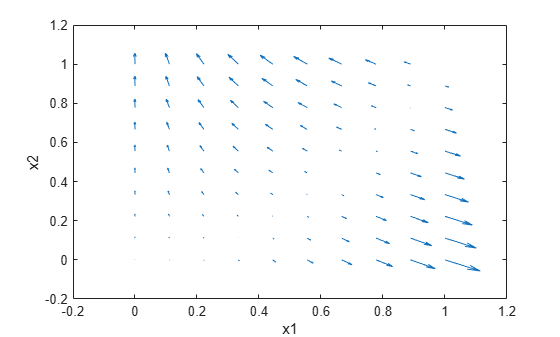
単位正方形内のいくつかの点について、Rosenbrock 関数の勾配をプロットします。まず、関数の評価点と出力を表す配列を初期化します。
[X1 X2] = meshgrid(linspace(0,1,10)); X1 = dlarray(X1(:)); X2 = dlarray(X2(:)); Y = dlarray(zeros(size(X1))); DYDX1 = Y; DYDX2 = Y;
ループ内で関数を評価します。quiver を使用して結果をプロットします。
for i = 1:length(X1) [Y(i),DYDX1(i),DYDX2(i)] = dlfeval(@rosenbrock2,X1(i),X2(i)); end quiver(extractdata(X1),extractdata(X2),extractdata(DYDX1),extractdata(DYDX2)) xlabel('x1') ylabel('x2')
dlgradient および dlfeval を使用して、複素数を含む関数の値と勾配を計算します。複素勾配を計算することも、勾配を実数のみに限定することもできます。
この例の最後にリストされている関数 complexFun を定義します。この関数は、以下の複素式を実装します。
この例の最後にリストされている関数 gradFun を定義します。この関数は、complexFun を呼び出し、dlgradient を使用して入力に対する結果の勾配を計算します。自動微分の場合、微分する値 (入力に基づいて計算される関数の値) は実数のスカラーでなければなりません。そのため、この関数は、勾配を計算する前に結果の実数部の合計を取ります。この関数は、関数値の実数部と勾配を返します。勾配は複素数となる場合があります。
範囲が -2 ~ 2 および -2 ~ 2 である複素平面上のサンプル点を定義し、dlarray に変換します。
functionRes = linspace(-2,2,100); x = functionRes + 1i*functionRes.'; x = dlarray(x);
各サンプル点について、関数値と勾配を計算します。
[y, grad] = dlfeval(@gradFun,x); y = extractdata(y);
勾配を表示するサンプル点を定義します。
gradientRes = linspace(-2,2,11); xGrad = gradientRes + 1i*gradientRes.';
これらのサンプル点の勾配値を抽出します。
[~,gradPlot] = dlfeval(@gradFun,dlarray(xGrad)); gradPlot = extractdata(gradPlot);
結果をプロットします。imagesc を使用して、複素平面上に関数の値を表示します。quiver を使用して、勾配の向きと大きさを表示します。
imagesc([-2,2],[-2,2],y); axis xy colorbar hold on quiver(real(xGrad),imag(xGrad),real(gradPlot),imag(gradPlot),"k"); xlabel("Real") ylabel("Imaginary") title("Real Value and Gradient","Re$(f(x)) = $ Re$((2+3i)x)$","interpreter","latex")

この関数の勾配は、複素平面全体で同じになっています。自動微分によって計算された勾配の値を抽出します。
grad(1,1)
ans = 1×1 dlarray 2.0000 - 3.0000i
検証すると、この関数の複素微分は次の値となることがわかります。
ただし、関数 Re() は解析的ではないため、複素微分は定義されません。MATLAB の自動微分の場合、微分する値は常に実数でなければならないため、複素解析関数を使用することはできません。代わりに、このプロットで示されているように、返された勾配が最急上昇方向を向くように微分が計算されます。これは、関数 Re:C R を関数 Re:R R R と解釈することで実現されます。
function y = complexFun(x) y = (2+3i)*x; end function [y,grad] = gradFun(x) y = complexFun(x); y = real(y); grad = dlgradient(sum(y,"all"),x); end
入力引数
名前と値の引数
出力引数
制限
カスタム逆方向関数をもつカスタム層が含まれる
dlnetworkオブジェクトを使用している場合、関数dlgradientは高次微分の計算をサポートしません。以下の層が含まれる
dlnetworkオブジェクトを使用している場合、関数dlgradientは高次微分の計算をサポートしません。gruLayerlstmLayerbilstmLayer
関数
dlgradientは、以下の関数に依存する高次微分の計算をサポートしません。grulstmembedprodinterp1
詳細
ヒント
dlgradientは関数の内部で呼び出さなければなりません。勾配の数値を取得するには、dlfevalを使用して関数を評価しなければなりません。また、関数の引数はdlarrayでなければなりません。Deep Learning Toolbox での自動微分の使用を参照してください。勾配を正しく評価するため、引数
yにはdlarrayをサポートしている関数のみを使用しなければなりません。dlarray をサポートする関数の一覧を参照してください。名前と値のペアの引数
'RetainData'をtrueに設定すると、微分の計算後、直ちにトレースが消去されず、関数dlfevalの呼び出し中はトレースが保持されます。この保持により、同じdlfeval呼び出し内の後続のdlgradient呼び出しが高速になりますが、より多くのメモリが使用されます。たとえば、敵対的ネットワークに学習させる場合、'RetainData'を設定すると、学習中に 2 つのネットワーク間でデータと関数が共有されるため、便利です。敵対的生成ネットワーク (GAN) の学習を参照してください。1 次微分のみを計算する必要がある場合は、
'EnableHigherDerivatives'オプションがfalseになっていることを確認してください。これにより、通常、処理時間が短縮され、メモリ使用量が節約されます。複素勾配はウィルティンガーの微分を使用して計算されます。勾配は、微分する関数の実数部が増加する向きで定義されます。これは、関数が複素数であっても微分する変数 (損失など) は実数でなければならないためです。
モデル関数やモデル損失関数などの深層学習関数の呼び出しを高速化するには、
dlaccelerate関数を使用できます。この関数は、トレースを自動的に最適化、キャッシュ、および再利用するAcceleratedFunctionオブジェクトを返します。
拡張機能
バージョン履歴
R2019b で導入