モデル関数を使用したネットワークの学習
この例では、層グラフまたは dlnetwork ではなく関数を使用して深層学習ネットワークを作成し、学習させる方法を説明します。関数の使用には、幅広いネットワークを記述する柔軟性が得られるという利点があります。欠点は、より多くのステップを実行し、データを慎重に準備しなければならないことです。この例では、手書き数字のイメージと、数字を分類して垂直位置からの各数字の角度を判定する双対目的関数を使用します。
学習データの読み込み
関数 digitTrain4DArrayData はイメージとその数字ラベル、および垂直方向からの回転角度を読み込みます。イメージ、ラベル、角度について arrayDatastore オブジェクトを作成してから、関数 combine を使用して、すべての学習データを含む単一のデータストアを作成します。クラス名と、離散でない応答の数を抽出します。
[XTrain,T1Train,T2Train] = digitTrain4DArrayData; dsXTrain = arrayDatastore(XTrain,IterationDimension=4); dsT1Train = arrayDatastore(T1Train); dsT2Train = arrayDatastore(T2Train); dsTrain = combine(dsXTrain,dsT1Train,dsT2Train); classNames = categories(T1Train); numClasses = numel(classNames); numResponses = size(T2Train,2); numObservations = numel(T1Train);
学習データからの一部のイメージを表示します。
idx = randperm(numObservations,64); I = imtile(XTrain(:,:,:,idx)); figure imshow(I)
深層学習モデルの定義
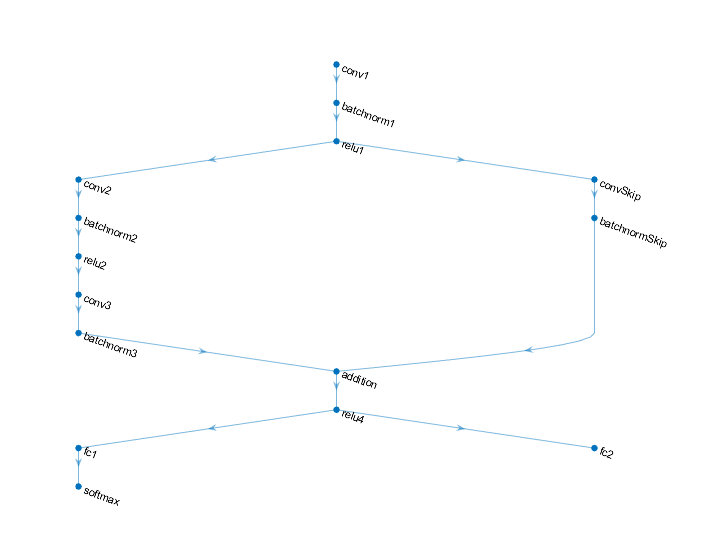
ラベルと回転角度の両方を予測する次のネットワークを定義します。
16 個の 5 x 5 フィルターをもつ convolution-batchnorm-ReLU ブロック
各ブロックに 32 個の 3 x 3 フィルターがあり、間に ReLU 演算をもつ、2 個の convolution-batchnorm ブロックの分岐
32 個の 1 x 1 の畳み込みをもつ convolution-batchnorm ブロックのあるスキップ接続
加算とそれに続く ReLU 演算を使用した両方の分岐の組み合わせ
回帰出力用に、サイズが 1 (応答数) の全結合演算をもつ分岐
分類出力用に、サイズが 10 (クラス数) の全結合演算とソフトマックス演算をもつ分岐
モデルのパラメーターと状態の定義および初期化
各演算のパラメーターを定義して struct に含めます。parameters.OperationName.ParameterName の形式で使用します。ここで、parameters は struct、OperationName は演算名 ("conv1" など)、ParameterName はパラメーター名 ("Weights" など) です。
モデル パラメーターを含む構造体 parameters を作成します。サンプル関数 initializeGlorot および initializeZeros を使用して、学習可能なパラメーターの重みとバイアスをそれぞれ初期化します。サンプル関数 initializeZeros および initializeOnes を使用して、バッチ正規化オフセットとスケール パラメーターをそれぞれ初期化します。
バッチ正規化演算を使用して学習や推論を実行するには、ネットワークの状態も管理しなければなりません。予測の前に、学習データから派生するデータセットの平均と分散を指定しなければなりません。状態パラメーターを含む構造体 state を作成します。バッチ正規化の統計値は、dlarray オブジェクトにしないでください。関数 zeros および ones を使用して、バッチ正規化の学習済み平均と学習済み分散の状態をそれぞれ初期化します。
この初期化サンプル関数は、この例にサポート ファイルとして添付されています。
最初の畳み込み演算 "conv1" のパラメーターを初期化します。
filterSize = [5 5]; numChannels = 1; numFilters = 16; sz = [filterSize numChannels numFilters]; numOut = prod(filterSize) * numFilters; numIn = prod(filterSize) * numFilters; parameters.conv1.Weights = initializeGlorot(sz,numOut,numIn); parameters.conv1.Bias = initializeZeros([numFilters 1]);
最初のバッチ正規化演算 "batchnorm1" のパラメーターと状態を初期化します。
parameters.batchnorm1.Offset = initializeZeros([numFilters 1]); parameters.batchnorm1.Scale = initializeOnes([numFilters 1]); state.batchnorm1.TrainedMean = initializeZeros([numFilters 1]); state.batchnorm1.TrainedVariance = initializeOnes([numFilters 1]);
2 番目の畳み込み演算 "conv2" のパラメーターを初期化します。
filterSize = [3 3]; numChannels = 16; numFilters = 32; sz = [filterSize numChannels numFilters]; numOut = prod(filterSize) * numFilters; numIn = prod(filterSize) * numFilters; parameters.conv2.Weights = initializeGlorot(sz,numOut,numIn); parameters.conv2.Bias = initializeZeros([numFilters 1]);
2 番目のバッチ正規化演算 "batchnorm2" のパラメーターと状態を初期化します。
parameters.batchnorm2.Offset = initializeZeros([numFilters 1]); parameters.batchnorm2.Scale = initializeOnes([numFilters 1]); state.batchnorm2.TrainedMean = initializeZeros([numFilters 1]); state.batchnorm2.TrainedVariance = initializeOnes([numFilters 1]);
3 番目の畳み込み演算 "conv3" のパラメーターを初期化します。
filterSize = [3 3]; numChannels = 32; numFilters = 32; sz = [filterSize numChannels numFilters]; numOut = prod(filterSize) * numFilters; numIn = prod(filterSize) * numFilters; parameters.conv3.Weights = initializeGlorot(sz,numOut,numIn); parameters.conv3.Bias = initializeZeros([numFilters 1]);
3 番目のバッチ正規化演算 "batchnorm3" のパラメーターと状態を初期化します。
parameters.batchnorm3.Offset = initializeZeros([numFilters 1]); parameters.batchnorm3.Scale = initializeOnes([numFilters 1]); state.batchnorm3.TrainedMean = initializeZeros([numFilters 1]); state.batchnorm3.TrainedVariance = initializeOnes([numFilters 1]);
スキップ接続 "convSkip" における畳み込み演算のパラメーターを初期化します。
filterSize = [1 1]; numChannels = 16; numFilters = 32; sz = [filterSize numChannels numFilters]; numOut = prod(filterSize) * numFilters; numIn = prod(filterSize) * numFilters; parameters.convSkip.Weights = initializeGlorot(sz,numOut,numIn); parameters.convSkip.Bias = initializeZeros([numFilters 1]);
スキップ接続 "batchnormSkip" におけるバッチ正規化演算のパラメーターと状態を初期化します。
parameters.batchnormSkip.Offset = initializeZeros([numFilters 1]); parameters.batchnormSkip.Scale = initializeOnes([numFilters 1]); state.batchnormSkip.TrainedMean = initializeZeros([numFilters 1]); state.batchnormSkip.TrainedVariance = initializeOnes([numFilters 1]);
分類出力 "fc1" に対応する全結合演算のパラメーターを初期化します。
sz = [numClasses 6272]; numOut = numClasses; numIn = 6272; parameters.fc1.Weights = initializeGlorot(sz,numOut,numIn); parameters.fc1.Bias = initializeZeros([numClasses 1]);
回帰出力 "fc2" に対応する全結合演算のパラメーターを初期化します。
sz = [numResponses 6272]; numOut = numResponses; numIn = 6272; parameters.fc2.Weights = initializeGlorot(sz,numOut,numIn); parameters.fc2.Bias = initializeZeros([numResponses 1]);
パラメーターの構造を表示します。
parameters
parameters = struct with fields:
conv1: [1×1 struct]
batchnorm1: [1×1 struct]
conv2: [1×1 struct]
batchnorm2: [1×1 struct]
conv3: [1×1 struct]
batchnorm3: [1×1 struct]
convSkip: [1×1 struct]
batchnormSkip: [1×1 struct]
fc1: [1×1 struct]
fc2: [1×1 struct]
"conv1" 演算のパラメーターを表示します。
parameters.conv1
ans = struct with fields:
Weights: [5×5×1×16 dlarray]
Bias: [16×1 dlarray]
状態パラメーターの構造を表示します。
state
state = struct with fields:
batchnorm1: [1×1 struct]
batchnorm2: [1×1 struct]
batchnorm3: [1×1 struct]
batchnormSkip: [1×1 struct]
"batchnorm1" 演算の状態パラメーターを表示します。
state.batchnorm1
ans = struct with fields:
TrainedMean: [16×1 dlarray]
TrainedVariance: [16×1 dlarray]
モデルの関数の定義
この例の最後にリストされている、前に説明した深層学習モデルの出力を計算する関数 model を作成します。
関数 model は、モデル パラメーター parameters、入力データ、モデルが学習と予測のどちらの出力を返すべきかを指定するフラグ doTraining、およびネットワークの状態を受け取ります。ネットワークはラベルの予測、角度の予測、および更新されたネットワークの状態を出力します。
モデル損失関数の定義
例の最後にリストされている関数 modelLoss を作成します。この関数は、モデル パラメーター、ならびに入力データのミニバッチとそれに対応するターゲット (ラベルと角度を含む) を受け取り、学習可能なパラメーターについての損失と損失の勾配、および更新されたネットワークの状態を返します。
学習オプションの指定
学習オプションを指定します。ミニバッチ サイズを 128 として 20 エポック学習させます。
numEpochs = 20; miniBatchSize = 128;
モデルの学習
minibatchqueueを使用して、イメージのミニバッチを処理および管理します。各ミニバッチで次を行います。
カスタム ミニバッチ前処理関数
preprocessMiniBatch(この例の最後に定義) を使用して、クラス ラベルを one-hot 符号化します。イメージ データを次元ラベル
"SSCB"(spatial、spatial、channel、batch) で形式を整えます。既定では、minibatchqueueオブジェクトは、基となる型がsingleのdlarrayオブジェクトにデータを変換します。形式をクラス ラベルまたは角度に追加しないでください。GPU が利用できる場合、GPU で学習を行います。既定では、
minibatchqueueオブジェクトは、GPU が利用可能な場合、各出力をgpuArrayに変換します。GPU を使用するには、Parallel Computing Toolbox™ とサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox)を参照してください。
mbq = minibatchqueue(dsTrain,... MiniBatchSize=miniBatchSize,... MiniBatchFcn=@preprocessMiniBatch,... MiniBatchFormat=["SSCB" "" ""]);
各エポックについて、データをシャッフルしてデータのミニバッチをループで回します。反復が終了するたびに、学習の進行状況を表示します。各ミニバッチで次を行います。
関数
dlfevalおよびmodelLossを使用してモデルの損失と勾配を評価します。関数
adamupdateを使用してネットワーク パラメーターを更新します。
Adam 用にパラメーターを初期化します。
trailingAvg = []; trailingAvgSq = [];
学習の進行状況モニターの進行状況バーを更新するには、学習の合計反復回数を計算します。
numIterationsPerEpoch = ceil(numObservations/miniBatchSize); numIterations = numIterationsPerEpoch * numEpochs;
TrainingProgressMonitor オブジェクトを初期化します。監視オブジェクトを作成するとタイマーが開始されるため、学習ループに近いところでオブジェクトを作成するようにしてください。
monitor = trainingProgressMonitor(Metrics="Loss",Info="Epoch",XLabel="Iteration");
モデルに学習させます。
epoch = 0; iteration = 0; % Loop over epochs. while epoch < numEpochs && ~monitor.Stop epoch = epoch + 1; % Shuffle data. shuffle(mbq) % Loop over mini-batches while hasdata(mbq) && ~monitor.Stop iteration = iteration + 1; [X,T1,T2] = next(mbq); % Evaluate the model loss, gradients, and state, using dlfeval and the % modelLoss function. [loss,gradients,state] = dlfeval(@modelLoss,parameters,X,T1,T2,state); % Update the network parameters using the Adam optimizer. [parameters,trailingAvg,trailingAvgSq] = adamupdate(parameters,gradients, ... trailingAvg,trailingAvgSq,iteration); % Update the training progress monitor. recordMetrics(monitor,iteration,Loss=loss); updateInfo(monitor,Epoch=(epoch+" of "+numEpochs)); monitor.Progress = 100 * iteration/numIterations; end end

モデルのテスト
真のラベルと角度をもつテスト セットで予測を比較して、モデルの分類精度をテストします。学習データと同じ設定の minibatchqueue オブジェクトを使用して、テスト データ セットを管理します。
[XTest,T1Test,T2Test] = digitTest4DArrayData; dsXTest = arrayDatastore(XTest,IterationDimension=4); dsT1Test = arrayDatastore(T1Test); dsT2Test = arrayDatastore(T2Test); dsTest = combine(dsXTest,dsT1Test,dsT2Test); mbqTest = minibatchqueue(dsTest,... MiniBatchSize=miniBatchSize,... MiniBatchFcn=@preprocessMiniBatch,... MiniBatchFormat=["SSCB" "" ""]);
検証データのラベルと角度を予測するために、ミニバッチをループ処理し、doTraining オプションを false に設定したモデル関数を使用します。予測されたクラスと角度を保存します。予測されたクラスおよび角度を真のクラスおよび角度と比較し、その結果を保存します。
doTraining = false; classesPredictions = []; anglesPredictions = []; classCorr = []; angleDiff = []; % Loop over mini-batches. while hasdata(mbqTest) % Read mini-batch of data. [X,T1,T2] = next(mbqTest); % Make predictions using the predict function. [Y1,Y2] = model(parameters,X,doTraining,state); % Determine predicted classes. Y1 = onehotdecode(Y1,classNames,1); classesPredictions = [classesPredictions Y1]; % Dermine predicted angles Y2 = extractdata(Y2); anglesPredictions = [anglesPredictions Y2]; % Compare predicted and true classes Y1Test = onehotdecode(T1,classNames,1); classCorr = [classCorr Y1 == Y1Test]; % Compare predicted and true angles angleDiffBatch = Y2 - T2; angleDiff = [angleDiff extractdata(gather(angleDiffBatch))]; end
分類精度を評価します。
accuracy = mean(classCorr)
accuracy = 0.9848
回帰精度を評価します。
angleRMSE = sqrt(mean(angleDiff.^2))
angleRMSE = single
6.5363
一部のイメージと、その予測を表示します。予測角度を赤、正解ラベルを緑で表示します。
idx = randperm(size(XTest,4),9); figure for i = 1:9 subplot(3,3,i) I = XTest(:,:,:,idx(i)); imshow(I) hold on sz = size(I,1); offset = sz/2; thetaPred = anglesPredictions(idx(i)); plot(offset*[1-tand(thetaPred) 1+tand(thetaPred)],[sz 0],"r--") thetaValidation = T2Test(idx(i)); plot(offset*[1-tand(thetaValidation) 1+tand(thetaValidation)],[sz 0],"g--") hold off label = string(classesPredictions(idx(i))); title("Label: " + label) end
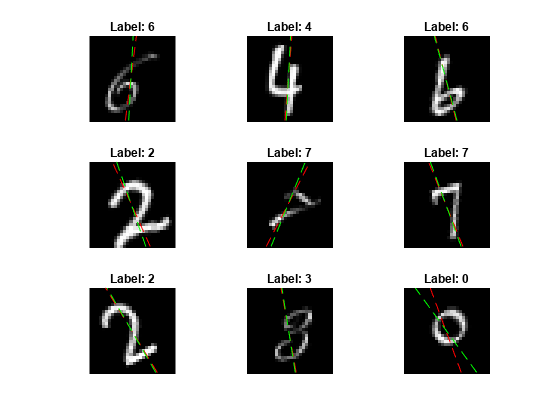
モデル関数
関数 model は、モデル パラメーター parameters、入力データ X、モデルが学習と予測のどちらの出力を返すべきかを指定するフラグ doTraining、およびネットワークの状態 state を受け取ります。ネットワークはラベルの予測、角度の予測、および更新されたネットワークの状態を出力します。

function [Y1,Y2,state] = model(parameters,X,doTraining,state) % Initial operations % Convolution - conv1 weights = parameters.conv1.Weights; bias = parameters.conv1.Bias; Y = dlconv(X,weights,bias,Padding="same"); % Batch normalization, ReLU - batchnorm1, relu1 offset = parameters.batchnorm1.Offset; scale = parameters.batchnorm1.Scale; trainedMean = state.batchnorm1.TrainedMean; trainedVariance = state.batchnorm1.TrainedVariance; if doTraining [Y,trainedMean,trainedVariance] = batchnorm(Y,offset,scale,trainedMean,trainedVariance); % Update state state.batchnorm1.TrainedMean = trainedMean; state.batchnorm1.TrainedVariance = trainedVariance; else Y = batchnorm(Y,offset,scale,trainedMean,trainedVariance); end Y = relu(Y); % Main branch operations % Convolution - conv2 weights = parameters.conv2.Weights; bias = parameters.conv2.Bias; YnoSkip = dlconv(Y,weights,bias,Padding="same",Stride=2); % Batch normalization, ReLU - batchnorm2, relu2 offset = parameters.batchnorm2.Offset; scale = parameters.batchnorm2.Scale; trainedMean = state.batchnorm2.TrainedMean; trainedVariance = state.batchnorm2.TrainedVariance; if doTraining [YnoSkip,trainedMean,trainedVariance] = batchnorm(YnoSkip,offset,scale,trainedMean,trainedVariance); % Update state state.batchnorm2.TrainedMean = trainedMean; state.batchnorm2.TrainedVariance = trainedVariance; else YnoSkip = batchnorm(YnoSkip,offset,scale,trainedMean,trainedVariance); end YnoSkip = relu(YnoSkip); % Convolution - conv3 weights = parameters.conv3.Weights; bias = parameters.conv3.Bias; YnoSkip = dlconv(YnoSkip,weights,bias,Padding="same"); % Batch normalization - batchnorm3 offset = parameters.batchnorm3.Offset; scale = parameters.batchnorm3.Scale; trainedMean = state.batchnorm3.TrainedMean; trainedVariance = state.batchnorm3.TrainedVariance; if doTraining [YnoSkip,trainedMean,trainedVariance] = batchnorm(YnoSkip,offset,scale,trainedMean,trainedVariance); % Update state state.batchnorm3.TrainedMean = trainedMean; state.batchnorm3.TrainedVariance = trainedVariance; else YnoSkip = batchnorm(YnoSkip,offset,scale,trainedMean,trainedVariance); end % Skip connection operations % Convolution, batch normalization (Skip connection) - convSkip, batchnormSkip weights = parameters.convSkip.Weights; bias = parameters.convSkip.Bias; YSkip = dlconv(Y,weights,bias,Stride=2); offset = parameters.batchnormSkip.Offset; scale = parameters.batchnormSkip.Scale; trainedMean = state.batchnormSkip.TrainedMean; trainedVariance = state.batchnormSkip.TrainedVariance; if doTraining [YSkip,trainedMean,trainedVariance] = batchnorm(YSkip,offset,scale,trainedMean,trainedVariance); % Update state state.batchnormSkip.TrainedMean = trainedMean; state.batchnormSkip.TrainedVariance = trainedVariance; else YSkip = batchnorm(YSkip,offset,scale,trainedMean,trainedVariance); end % Final operations % Addition, ReLU - addition, relu4 Y = YSkip + YnoSkip; Y = relu(Y); % Fully connect, softmax (labels) - fc1, softmax weights = parameters.fc1.Weights; bias = parameters.fc1.Bias; Y1 = fullyconnect(Y,weights,bias); Y1 = softmax(Y1); % Fully connect (angles) - fc2 weights = parameters.fc2.Weights; bias = parameters.fc2.Bias; Y2 = fullyconnect(Y,weights,bias); end
モデル損失関数
関数 modelLoss は、モデル パラメーター、入力データのミニバッチ X とそれに対応するターゲット T1 および T2 (それぞれラベルと角度を含む) を受け取り、学習可能なパラメーターについての損失と損失の勾配、および更新されたネットワークの状態を返します。
function [loss,gradients,state] = modelLoss(parameters,X,T1,T2,state) doTraining = true; [Y1,Y2,state] = model(parameters,X,doTraining,state); lossLabels = crossentropy(Y1,T1); lossAngles = mse(Y2,T2); loss = lossLabels + 0.1*lossAngles; gradients = dlgradient(loss,parameters); end
ミニバッチ前処理関数
関数 preprocessMiniBatch は、次の手順でデータを前処理します。
入力 cell 配列からイメージ データを抽出して数値配列に連結します。4 番目の次元でイメージ データを連結することにより、3 番目の次元が各イメージに追加されます。この次元は、シングルトン チャネル次元として使用されます。
入力 cell 配列からラベルと角度データを抽出して、それを 2 番目の次元と共に、categorical 配列および数値配列にそれぞれ連結します。
カテゴリカル ラベルを数値配列に one-hot 符号化します。最初の次元への符号化は、ネットワーク出力の形状と一致する符号化された配列を生成します。
function [X,T1,T2] = preprocessMiniBatch(dataX,dataT1,dataT2) % Extract image data from cell and concatenate X = cat(4,dataX{:}); % Extract label data from cell and concatenate T1 = cat(2,dataT1{:}); % Extract angle data from cell and concatenate T2 = cat(2,dataT2{:}); % One-hot encode labels T1 = onehotencode(T1,1); end
参考
dlarray | sgdmupdate | dlfeval | dlgradient | fullyconnect | dlconv | softmax | relu | batchnorm | crossentropy | minibatchqueue | onehotencode | onehotdecode