Wasserstein GAN with Gradient Penalty (WGAN-GP) の学習
この例では、Wasserstein generative adversarial network with a gradient penalty (WGAN-GP) に学習させてイメージを生成する方法を説明します。
敵対的生成ネットワーク (GAN) は深層学習ネットワークの一種で、入力された実データに類似した特性をもつデータを生成できます。
GAN は一緒に学習を行う 2 つのネットワークで構成されています。
ジェネレーター — このネットワークは、乱数値 (潜在入力) のベクトルを入力として与えられ、学習データと同じ構造のデータを生成します。
ディスクリミネーター — このネットワークは、学習データとジェネレーターにより生成されたデータの両方の観測値を含むデータのバッチについて、その観測値が "実データ" か "生成データ" かの分類を試みます。
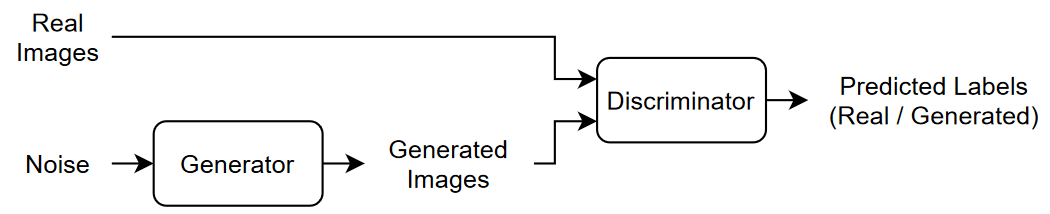
GAN に学習させる場合は、両方のネットワークの学習を同時に行うことで両者の性能を最大化します。
ジェネレーターに学習させて、ディスクリミネーターを "騙す" データを生成。
ディスクリミネーターに学習させて、実データと生成データを区別。
ジェネレーターの性能を最適化するために、生成データが与えられたときのディスクリミネーターの損失を最大化します。つまり、ジェネレーターの目的はディスクリミネーターが "実データ" と分類するようなデータを生成することです。ディスクリミネーターの性能を最適化するために、実データと生成データの両方のバッチが与えられたときのディスクリミネーターの損失を最小化します。つまり、ディスクリミネーターの目的はジェネレーターに "騙されない" ことです。
これらの方法によって、いかにも本物らしいデータを生成するジェネレーターと、学習データの特性である強い特徴表現を学習したディスクリミネーターを得ることが理想的な結果です。ただし、[2] では、一般的に GAN が最小化する発散はジェネレーターのパラメーターに対して不連続である可能性があるため学習が困難になるとして、学習の安定化のために Wasserstein 損失を使用する Wasserstein GAN (WGAN) モデルを紹介しています。WGAN モデルは、重み制約とコスト関数の間の交互作用によって勾配が消失または発散する可能性があるため、依然としてサンプルの生成が十分でなかったり収束しなかったりする可能性があります。これらの問題に対処するために、[3] では勾配ペナルティを導入しています。計算時間は長くなりますが、ノルムの値が大きい勾配にペナルティを課すことによって安定性を向上させます。このタイプのモデルは、WGAN-GP モデルと呼ばれます。
この例では、イメージの学習セットと類似した特性をもつイメージを生成できる WGAN-GP モデルに学習させる方法を説明します。
学習データの読み込み
Flowers データ セット [1] をダウンロードし、解凍します。
url = "http://download.tensorflow.org/example_images/flower_photos.tgz"; downloadFolder = tempdir; filename = fullfile(downloadFolder,"flower_dataset.tgz"); imageFolder = fullfile(downloadFolder,"flower_photos"); if ~datasetExists(imageFolder) disp("Downloading Flowers data set (218 MB)...") websave(filename,url); untar(filename,downloadFolder) end
花の写真のイメージ データストアを作成します。
datasetFolder = fullfile(imageFolder);
imds = imageDatastore(datasetFolder, ...
IncludeSubfolders=true);データを拡張して水平方向にランダムに反転させ、イメージのサイズを 64 x 64 に変更します。
augmenter = imageDataAugmenter(RandXReflection=true); augimds = augmentedImageDatastore([64 64],imds,DataAugmentation=augmenter);
ディスクリミネーター ネットワークの定義
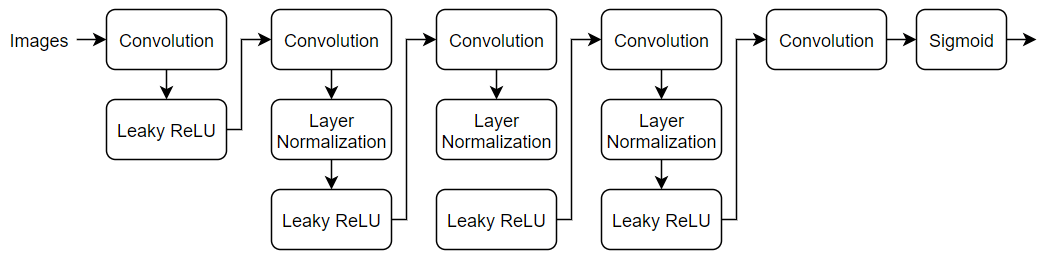
64 x 64 の実イメージと生成イメージを分類する、次のネットワークを定義します。
カスタム学習ループを使用してネットワークに学習させ、自動微分を有効にするために、dlnetwork オブジェクトを作成します。
netD = dlnetwork;
64×64×3 のイメージを受け取ってバッチ正規化のある一連の畳み込み層と leaky ReLU 層を使用してスカラーの予測スコアを返す層を指定し、それをネットワークに追加します。[0,1] の範囲の確率を出力するには、シグモイド層を使用します。
畳み込み層で、5 x 5 のフィルターを指定し、各層でフィルター数を増やす。また、ストライドを 2 に指定し、出力のパディングを指定します。
leaky ReLU 層で、スケールを 0.2 に設定。
最後の畳み込み層で、4 行 4 列のフィルターを 1 つ設定。
numFilters = 64;
scale = 0.2;
inputSize = [64 64 3];
filterSize = 5;
layersD = [
imageInputLayer(inputSize,Normalization="none")
convolution2dLayer(filterSize,numFilters,Stride=2,Padding="same")
leakyReluLayer(scale)
convolution2dLayer(filterSize,2*numFilters,Stride=2,Padding="same")
layerNormalizationLayer
leakyReluLayer(scale)
convolution2dLayer(filterSize,4*numFilters,Stride=2,Padding="same")
layerNormalizationLayer
leakyReluLayer(scale)
convolution2dLayer(filterSize,8*numFilters,Stride=2,Padding="same")
layerNormalizationLayer
leakyReluLayer(scale)
convolution2dLayer(4,1)
sigmoidLayer];
netD = addLayers(netD, layersD);ネットワークの学習可能なパラメーターと状態パラメーターを初期化します。
netD = initialize(netD);
ジェネレーター ネットワークの定義
1×1×100 の乱数値の配列からイメージを生成するネットワーク アーキテクチャを以下のように定義します。

カスタム学習ループを使用してネットワークに学習させ、自動微分を有効にするために、dlnetwork オブジェクトを作成します。
netG = dlnetwork;
このネットワークは、次を行います。
"投影および形状変更" 層を使用して、サイズ 100 のランダム ベクトルを 4×4×512 の配列に変換。
一連の転置畳み込み層と ReLU 層を使用して、結果の配列を 64×64×3 の配列にアップスケーリング。
このネットワーク アーキテクチャを層配列として定義し、ネットワークに追加します。次のネットワーク プロパティを指定します。
転置畳み込み層では、各層のフィルター数を減らして 5 x 5 のフィルターを指定し、ストライドを 2 に指定し、各エッジでの出力のトリミングを指定します。
最後の転置畳み込み層では、生成されたイメージの 3 つの RGB チャネルに対応する 3 つの 5 x 5 のフィルターと、前の層の出力サイズを設定。
ネットワークの最後に、tanh 層を追加。
ノイズ入力を投影して形状変更するには、この例にサポート ファイルとして添付されている、カスタム層 projectAndReshapeLayer を使用します。projectAndReshape 層は、全結合演算を使用して入力をアップスケールし、指定されたサイズに出力を形状変更します。
filterSize = 5;
numFilters = 64;
numLatentInputs = 100;
projectionSize = [4 4 512];
layersG = [
featureInputLayer(numLatentInputs,Normalization="none")
projectAndReshapeLayer(projectionSize);
transposedConv2dLayer(filterSize,4*numFilters)
reluLayer
transposedConv2dLayer(filterSize,2*numFilters,Stride=2,Cropping="same")
reluLayer
transposedConv2dLayer(filterSize,numFilters,Stride=2,Cropping="same")
reluLayer
transposedConv2dLayer(filterSize,3,Stride=2,Cropping="same")
tanhLayer];
netG = addLayers(netG, layersG);ネットワークの学習可能なパラメーターと状態パラメーターを初期化します。
netG = initialize(netG);
モデル損失関数の定義
この例のモデル損失関数セクションにリストされている関数 modelLossD および modelLossG を作成します。これらの関数はそれぞれ、ディスクリミネーター ネットワークとジェネレーター ネットワークの学習可能なパラメーターについて、ディスクリミネーターの損失の勾配とジェネレーターの損失の勾配を計算します。
関数 modelLossD は、ジェネレーター ネットワークとディスクリミネーター ネットワーク、入力データのミニバッチ、乱数値の配列、および勾配ペナルティに使用される lambda 値を入力として受け取り、ディスクリミネーターの学習可能なパラメーターについての損失とその損失の勾配を返します。
関数 modelLossG は、ジェネレーター ネットワークとディスクリミネーター ネットワーク、乱数値の配列を入力として受け取り、ジェネレーターの学習可能なパラメーターについての損失とその損失の勾配を返します。
学習オプションの指定
WGAN-GP モデルに学習させるには、ジェネレーターよりも多くの反復でディスクリミネーターに学習させなければなりません。つまり、ジェネレーターの各反復で、ディスクリミネーターには複数回反復して学習させなければなりません。
ミニバッチ サイズが 64、ジェネレーター反復回数が 10,000 回で学習を行います。大きなデータセットでは、学習の反復回数をさらに増やさなければならないことがあります。
miniBatchSize = 64; numIterationsG = 10000;
ジェネレーターの各反復で、ディスクリミネーターには 5 回反復して学習させます。
numIterationsDPerG = 5;
WGAN-GP 損失の場合、lambda 値に 10 を指定します。lambda 値は、ディスクリミネーターの損失に追加される勾配ペナルティの大きさを制御します。
lambda = 10;
ADAM 最適化のオプションを指定します。
ディスクリミネーター ネットワークには、0.0002 の学習率を指定。
ジェネレーター ネットワークには、0.001 の学習率を指定。
どちらのネットワークも、勾配の減衰係数に 0 を、2 乗勾配の減衰係数に 0.9 を指定。
learnRateD = 2e-4; learnRateG = 1e-3; gradientDecayFactor = 0; squaredGradientDecayFactor = 0.9;
生成された検証イメージを、ジェネレーターの反復回数 20 回ごとに表示します。
validationFrequency = 20;
モデルの学習
minibatchqueueを使用して、イメージのミニバッチを処理および管理します。各ミニバッチで次を行います。
カスタム ミニバッチ前処理関数
preprocessMiniBatch(この例の最後に定義) を使用して、イメージを範囲[-1,1]で再スケーリングします。部分的なミニバッチは破棄します。
イメージ データを次元ラベル
"SSCB"(spatial、spatial、channel、batch) で形式を整えます。GPU が利用できる場合、GPU で学習を行います。
minibatchqueueのOutputEnvironmentオプションが"auto"のとき、GPU が利用可能であれば、minibatchqueueは各出力をgpuArrayに変換します。GPU を使用するには、Parallel Computing Toolbox™ とサポートされている GPU デバイスが必要です。サポートされているデバイスの詳細については、GPU 計算の要件 (Parallel Computing Toolbox) (Parallel Computing Toolbox) を参照してください。
minibatchqueue オブジェクトは、既定では、基となる型が single の dlarray オブジェクトにデータを変換します。
augimds.MiniBatchSize = miniBatchSize; mbq = minibatchqueue(augimds,... MiniBatchSize=miniBatchSize,... PartialMiniBatch="discard",... MiniBatchFcn=@preprocessMiniBatch,... MiniBatchFormat="SSCB");
カスタム学習ループを使用してモデルに学習させます。学習データ全体をループ処理し、各反復でネットワーク パラメーターを更新します。学習の進行状況を監視するには、ホールドアウトされた乱数値の配列をジェネレーターに入力して得られた生成イメージのバッチと、スコアのプロットを表示します。
Adam のパラメーターを初期化します。
trailingAvgD = []; trailingAvgSqD = []; trailingAvgG = []; trailingAvgSqG = [];
学習の進行状況を監視するには、ホールドアウトされた乱数値の固定配列のバッチをジェネレーターに渡して得られた生成イメージのバッチを表示し、ネットワークのスコアをプロットします。
ホールドアウトされた乱数値の配列を作成します。
numValidationImages = 25;
ZValidation = randn(numLatentInputs,numValidationImages,"single");データを dlarray オブジェクトに変換し、次元ラベル "SSCB" (spatial、spatial、channel、batch) を指定します。
ZValidation = dlarray(ZValidation,"CB"); GPU での学習用に、データを gpuArray オブジェクトに変換します。
if canUseGPU ZValidation = gpuArray(ZValidation); end
学習の進行状況プロットを初期化します。Figure を作成して幅が 2 倍になるようサイズ変更します。
f = figure; f.Position(3) = 2*f.Position(3);
生成イメージとネットワーク スコアのサブプロットを作成します。
imageAxes = subplot(1,2,1); scoreAxes = subplot(1,2,2);
損失のプロット用にアニメーションの線を初期化します。
C = colororder; lineLossD = animatedline(scoreAxes,Color=C(1,:)); lineLossDUnregularized = animatedline(scoreAxes,Color=C(2,:)); legend("With Gradient Penalty","Unregularized") xlabel("Generator Iteration") ylabel("Discriminator Loss") grid on
データのミニバッチをループ処理して、WGAN-GP モデルに学習させます。
numIterationsDPerG 回の反復で、ディスクリミネーターにのみ学習させます。各ミニバッチで次を行います。
関数
dlfevalおよびmodelLossDを使用してディスクリミネーター モデルの損失と勾配を評価します。関数
adamupdateを使用してディスクリミネーターのネットワーク パラメーターを更新します。
numIterationsDPerG 回の反復でディスクリミネーターに学習させた後、単一のミニバッチでジェネレーターに学習させます。
関数
dlfevalおよびmodelLossGを使用してジェネレーター モデルの損失と勾配を評価します。関数
adamupdateを使用してジェネレーターのネットワーク パラメーターを更新します。
ジェネレーター ネットワークを更新した後、次を行います。
2 つのネットワークの損失をプロットします。
validationFrequency回のジェネレーターの反復が終わるごとに、ホールドアウトされた固定ジェネレーター入力の生成イメージのバッチを表示します。
データ セットを渡した後、ミニバッチ キューをシャッフルします。
学習には時間がかかる場合があり、良好なイメージを出力するために多数の反復が必要になる場合があります。
iterationG = 0; iterationD = 0; start = tic; % Loop over mini-batches while iterationG < numIterationsG iterationG = iterationG + 1; % Train discriminator only for n = 1:numIterationsDPerG iterationD = iterationD + 1; % Reset and shuffle mini-batch queue when there is no more data. if ~hasdata(mbq) shuffle(mbq); end % Read mini-batch of data. X = next(mbq); % Generate latent inputs for the generator network. Convert to % dlarray and specify the dimension labels "CB" (channel, batch). Z = randn([numLatentInputs size(X,4)],like=X); Z = dlarray(Z,"CB"); % Evaluate the discriminator model loss and gradients using dlfeval and the % modelLossD function listed at the end of the example. [lossD, lossDUnregularized, gradientsD] = dlfeval(@modelLossD, netD, netG, X, Z, lambda); % Update the discriminator network parameters. [netD,trailingAvgD,trailingAvgSqD] = adamupdate(netD, gradientsD, ... trailingAvgD, trailingAvgSqD, iterationD, ... learnRateD, gradientDecayFactor, squaredGradientDecayFactor); end % Generate latent inputs for the generator network. Convert to dlarray % and specify the dimension labels "CB" (channel, batch). Z = randn([numLatentInputs size(X,4)],like=X); Z = dlarray(Z,"CB"); % Evaluate the generator model loss and gradients using dlfeval and the % modelLossG function listed at the end of the example. [~,gradientsG] = dlfeval(@modelLossG, netG, netD, Z); % Update the generator network parameters. [netG,trailingAvgG,trailingAvgSqG] = adamupdate(netG, gradientsG, ... trailingAvgG, trailingAvgSqG, iterationG, ... learnRateG, gradientDecayFactor, squaredGradientDecayFactor); % Every validationFrequency generator iterations, display batch of % generated images using the held-out generator input if mod(iterationG,validationFrequency) == 0 || iterationG == 1 % Generate images using the held-out generator input. XGeneratedValidation = predict(netG,ZValidation); % Tile and rescale the images in the range [0 1]. I = imtile(extractdata(XGeneratedValidation)); I = rescale(I); % Display the images. subplot(1,2,1); image(imageAxes,I) xticklabels([]); yticklabels([]); title("Generated Images"); end % Update the scores plot subplot(1,2,2) lossD = double(lossD); lossDUnregularized = double(lossDUnregularized); addpoints(lineLossD,iterationG,lossD); addpoints(lineLossDUnregularized,iterationG,lossDUnregularized); D = duration(0,0,toc(start),Format="hh:mm:ss"); title( ... "Iteration: " + iterationG + ", " + ... "Elapsed: " + string(D)) drawnow end
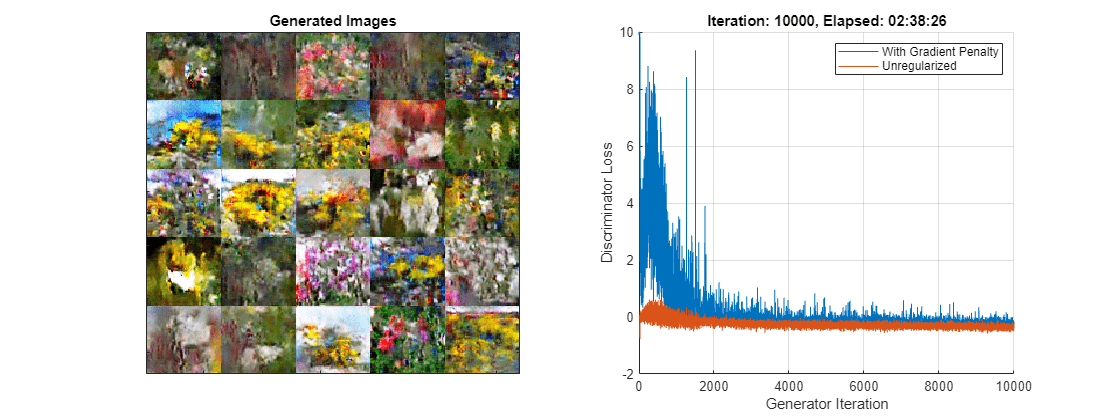
ここでは、ディスクリミネーターは生成イメージの中から実イメージを識別する強い特徴表現を学習しました。次に、ジェネレーターは、学習データと同様のイメージを生成できるように、同様に強い特徴表現を学習しました。
新しいイメージの生成
新しいイメージを生成するには、ジェネレーターに対して関数 predict を使用して、ランダム ベクトルのバッチを含む dlarray オブジェクトを指定します。イメージを並べて表示するには関数 imtile を使用し、関数 rescale を使ってイメージを再スケーリングします。
ジェネレーター ネットワークに入力するランダム ベクトル 25 個のバッチを含む dlarray オブジェクトを作成します。
ZNew = randn(numLatentInputs,25,"single"); ZNew = dlarray(ZNew,"CB");
GPU を使用してイメージを生成するには、データを gpuArray オブジェクトにも変換します。
if canUseGPU ZNew = gpuArray(ZNew); end
関数 predict をジェネレーターと入力データと共に使用して、新しいイメージを生成します。
XGeneratedNew = predict(netG,ZNew);
イメージを表示します。
I = imtile(extractdata(XGeneratedNew)); I = rescale(I); figure image(I) axis off title("Generated Images")

モデル損失関数
ディスクリミネーター モデル損失関数
関数 modelLossD は、dlnetwork オブジェクトのジェネレーター netG とディスクリミネーター netD、入力データのミニバッチ X、乱数値の配列 Z、および勾配ペナルティに使用される lambda 値を入力として受け取り、ディスクリミネーターの学習可能なパラメーターについての損失とその損失の勾配を返します。
イメージ と生成されたイメージ が与えられた場合について、ランダムな に関して と定義します。
WGAN-GP モデルでは、lambda 値 が与えられた場合、ディスクリミネーターの損失は次で求められます。
ここで、、、および は、それぞれ入力 、、および のディスクリミネーターの出力を表し、 は に対する出力 の勾配を表します。データのミニバッチについて、観測値ごとに異なる の値を使用し、平均損失を計算します。
勾配ペナルティ は、ノルムの値が大きい勾配にペナルティを課すことにより、安定性を向上させます。lambda 値は、ディスクリミネーターの損失に追加される勾配ペナルティの大きさを制御します。
function [lossD, lossDUnregularized, gradientsD] = modelLossD(netD, netG, X, Z, lambda) % Calculate the predictions for real data with the discriminator network. YPred = forward(netD, X); % Calculate the predictions for generated data with the discriminator % network. XGenerated = forward(netG,Z); YPredGenerated = forward(netD, XGenerated); % Calculate the loss. lossDUnregularized = mean(YPredGenerated - YPred); % Calculate and add the gradient penalty. epsilon = rand([1 1 1 size(X,4)],like=X); XHat = epsilon.*X + (1-epsilon).*XGenerated; YHat = forward(netD, XHat); % Calculate gradients. To enable computing higher-order derivatives, set % EnableHigherDerivatives to true. gradientsHat = dlgradient(sum(YHat),XHat,EnableHigherDerivatives=true); gradientsHatNorm = sqrt(sum(gradientsHat.^2,1:3) + 1e-10); gradientPenalty = lambda.*mean((gradientsHatNorm - 1).^2); % Penalize loss. lossD = lossDUnregularized + gradientPenalty; % Calculate the gradients of the penalized loss with respect to the % learnable parameters. gradientsD = dlgradient(lossD, netD.Learnables); end
ジェネレーター モデル損失関数
関数 modelLossG は、dlnetwork オブジェクトのジェネレーター netG とディスクリミネーター netD、乱数値の配列 Z を入力として受け取り、ジェネレーターの学習可能なパラメーターについての損失とその損失の勾配を返します。
生成されたイメージ が与えられた場合、ジェネレーター ネットワークの損失は次で求められます。
ここで、 は、生成されたイメージ に対するディスクリミネーターの出力を表します。生成されたイメージのミニバッチについて、平均損失を計算します。
function [lossG,gradientsG] = modelLossG(netG, netD, Z) % Calculate the predictions for generated data with the discriminator % network. XGenerated = forward(netG,Z); YPredGenerated = forward(netD, XGenerated); % Calculate the loss. lossG = -mean(YPredGenerated); % Calculate the gradients of the loss with respect to the learnable % parameters. gradientsG = dlgradient(lossG, netG.Learnables); end
ミニバッチ前処理関数
関数 preprocessMiniBatch は、次の手順でデータを前処理します。
入力 cell 配列からイメージ データを抽出して数値配列に連結します。
イメージの範囲が
[-1,1]となるように再スケーリングします。
function X = preprocessMiniBatch(data) % Concatenate mini-batch X = cat(4,data{:}); % Rescale the images in the range [-1 1]. X = rescale(X,-1,1,InputMin=0,InputMax=255); end
参考文献
The TensorFlow Team.Flowers http://download.tensorflow.org/example_images/flower_photos.tgz
Arjovsky, Martin, Soumith Chintala, and Léon Bottou. "Wasserstein GAN." arXiv preprint arXiv:1701.07875 (2017).
Gulrajani, Ishaan, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C. Courville. "Improved training of Wasserstein GANs." In Advances in neural information processing systems, pp. 5767-5777. 2017.
参考
dlnetwork | forward | predict | dlarray | dlgradient | dlfeval | adamupdate