lassoglm
Lasso or elastic net regularization for generalized linear models
Syntax
Description
B = lassoglm(X,y)X and the response
y, where the values in y are assumed
to have a normal probability distribution. Each column of B
corresponds to a particular regularization coefficient in
Lambda. By default, lassoglm performs
lasso regularization using a geometric sequence of Lambda
values.
B = lassoglm(X,y,distr,Name,Value)'Alpha',0.5
sets elastic net as the regularization method, with the parameter
Alpha equal to 0.5.
Examples
Remove Redundant Predictors Using Lasso Regularization
Construct a data set with redundant predictors and identify those predictors by using lassoglm.
Create a random matrix X with 100 observations and 10 predictors. Create the normally distributed response y using only four of the predictors and a small amount of noise.
rng default X = randn(100,10); weights = [0.6;0.5;0.7;0.4]; y = X(:,[2 4 5 7])*weights + randn(100,1)*0.1; % Small added noise
Perform lasso regularization.
B = lassoglm(X,y);
Find the coefficient vector for the 75th Lambda value in B.
B(:,75)
ans = 10×1
0
0.5431
0
0.3944
0.6173
0
0.3473
0
0
0
lassoglm identifies and removes the redundant predictors.
Cross-Validated Lasso Regularization of Generalized Linear Model
Construct data from a Poisson model, and identify the important predictors by using lassoglm.
Create data with 20 predictors. Create a Poisson response variable using only three of the predictors plus a constant.
rng default % For reproducibility X = randn(100,20); weights = [.4;.2;.3]; mu = exp(X(:,[5 10 15])*weights + 1); y = poissrnd(mu);
Construct a cross-validated lasso regularization of a Poisson regression model of the data.
[B,FitInfo] = lassoglm(X,y,'poisson','CV',10);
Examine the cross-validation plot to see the effect of the Lambda regularization parameter.
lassoPlot(B,FitInfo,'plottype','CV'); legend('show') % Show legend
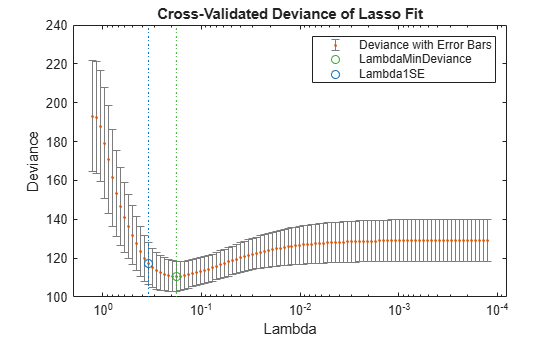
The green circle and dotted line locate the Lambda with minimum cross-validation error. The blue circle and dotted line locate the point with minimum cross-validation error plus one standard deviation.
Find the nonzero model coefficients corresponding to the two identified points.
idxLambdaMinDeviance = FitInfo.IndexMinDeviance; mincoefs = find(B(:,idxLambdaMinDeviance))
mincoefs = 7×1
3
5
6
10
11
15
16
idxLambda1SE = FitInfo.Index1SE; min1coefs = find(B(:,idxLambda1SE))
min1coefs = 3×1
5
10
15
The coefficients from the minimum-plus-one standard error point are exactly those coefficients used to create the data.
Predict Values Using Lasso Regularization
Predict whether students got a B or above on their last exam by using lassoglm.
Load the examgrades data set. Convert the last exam grades to a logical vector, where 1 represents a grade of 80 or above and 0 represents a grade below 80.
load examgrades
X = grades(:,1:4);
y = grades(:,5);
yBinom = (y>=80);Partition the data into training and test sets.
rng default % Set the seed for reproducibility c = cvpartition(yBinom,'HoldOut',0.3); idxTrain = training(c,1); idxTest = ~idxTrain; XTrain = X(idxTrain,:); yTrain = yBinom(idxTrain); XTest = X(idxTest,:); yTest = yBinom(idxTest);
Perform lasso regularization for generalized linear model regression with 3-fold cross-validation on the training data. Assume the values in y are binomially distributed. Choose model coefficients corresponding to the Lambda with minimum expected deviance.
[B,FitInfo] = lassoglm(XTrain,yTrain,'binomial','CV',3); idxLambdaMinDeviance = FitInfo.IndexMinDeviance; B0 = FitInfo.Intercept(idxLambdaMinDeviance); coef = [B0; B(:,idxLambdaMinDeviance)]
coef = 5×1
-21.1911
0.0235
0.0670
0.0693
0.0949
Predict exam grades for the test data using the model coefficients found in the previous step. Specify the link function for a binomial response using 'logit'. Convert the prediction values to a logical vector.
yhat = glmval(coef,XTest,'logit');
yhatBinom = (yhat>=0.5);Determine the accuracy of the predictions using a confusion matrix.
c = confusionchart(yTest,yhatBinom);

The function correctly predicts 31 exam grades. However, the function incorrectly predicts that 1 student receives a B or above and 4 students receive a grade below a B.
Use Correlation Matrix for Fitting lassoglm
Create a matrix X of N p-dimensional normal variables, where N is large and p = 1000. Create a response vector y from the model y = X*beta + noise, where beta is a vector of coefficients with 50% nonzero values.
rng default % For reproducibility N = 1e4; % Number of samples p = 1e3; % Number of features X = randn(N,p); beta = 1 + 3*rand(p,1); % Multiplicative coefficients activep = randperm(p,p/2); % 50% nonzero coefficients y = X(:,activep)*beta(activep) + randn(N,1)*0.1; % Add noise
Construct the lasso fit without using the covariance matrix. Time the creation.
B = lassoglm(X,y,"normal",UseCovariance=false); % Warm up lasso for reliable timing data tic B = lassoglm(X,y,"normal",UseCovariance=false); timefalse = toc
timefalse = 4.8752
Construct the lasso fit using the covariance matrix. Time the creation.
B2 = lassoglm(X,y,"normal",UseCovariance=true); % Warm up lasso for reliable timing data tic B2 = lassoglm(X,y,"normal",UseCovariance=true); timetrue = toc
timetrue = 1.6029
The fitting time with the covariance matrix is less than the time without it. View the speedup factor that results from using the covariance matrix.
speedup = timefalse/timetrue
speedup = 3.0415
Check that the returned coefficients B and B2 are similar.
norm(B-B2)/norm(B)
ans = 4.8056e-16
The results are virtually identical.
Input Arguments
Output Arguments
More About
Algorithms
References
[1] Tibshirani, R. “Regression Shrinkage and Selection via the Lasso.” Journal of the Royal Statistical Society. Series B, Vol. 58, No. 1, 1996, pp. 267–288.
[2] Zou, H., and T. Hastie. “Regularization and Variable Selection via the Elastic Net.” Journal of the Royal Statistical Society. Series B, Vol. 67, No. 2, 2005, pp. 301–320.
[3] Friedman, J., R. Tibshirani, and T. Hastie.
“Regularization Paths for Generalized Linear Models via Coordinate
Descent.” Journal of Statistical Software. Vol. 33, No. 1,
2010. https://www.jstatsoft.org/v33/i01
[4] Hastie, T., R. Tibshirani, and J. Friedman. The Elements of Statistical Learning. 2nd edition. New York: Springer, 2008.
[5] Dobson, A. J. An Introduction to Generalized Linear Models. 2nd edition. New York: Chapman & Hall/CRC Press, 2002.
[6] McCullagh, P., and J. A. Nelder. Generalized Linear Models. 2nd edition. New York: Chapman & Hall/CRC Press, 1989.
[7] Collett, D. Modelling Binary Data. 2nd edition. New York: Chapman & Hall/CRC Press, 2003.
Extended Capabilities
Version History
Introduced in R2012a
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)