copulafit
データへのコピュラの当てはめ
構文
説明
___ = copulafit(___, は、1 つ以上の Name,Value)Name,Value ペア引数で指定された追加オプションを使用して、前の構文のいずれかを返します。たとえば、計算する信頼区間を指定したり、オプションの構造体を使用して反復パラメーター推定アルゴリズムの制御パラメーターを指定できます。
例
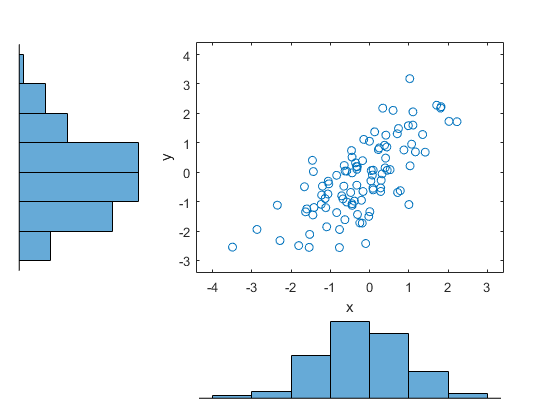
シミュレートされた株式収益データを読み込み、プロットします。
load stockreturns
x = stocks(:,1);
y = stocks(:,2);
figure;
scatterhist(x,y)
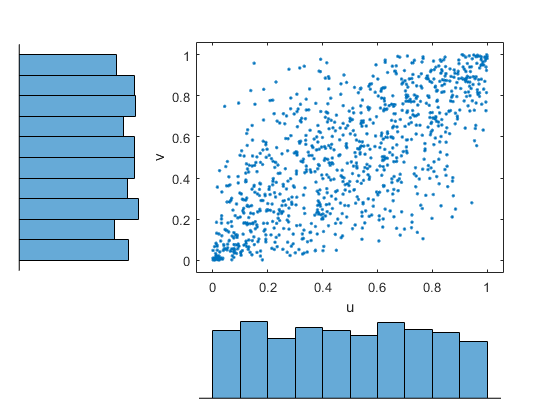
累積分布関数のカーネル推定器を使って、データをコピュラ スケール (単位正方形) に変換します。
u = ksdensity(x,x,'function','cdf'); v = ksdensity(y,y,'function','cdf'); figure; scatterhist(u,v) xlabel('u') ylabel('v')

データに t コピュラを当てはめます。
rng default % For reproducibility [Rho,nu] = copulafit('t',[u v],'Method','ApproximateML')
Rho =
1.0000 0.7220
0.7220 1.0000
nu =
2.7290e+06
t コピュラから無作為標本を生成します。
r = copularnd('t',Rho,nu,1000); u1 = r(:,1); v1 = r(:,2); figure; scatterhist(u1,v1) xlabel('u') ylabel('v') set(get(gca,'children'),'marker','.')
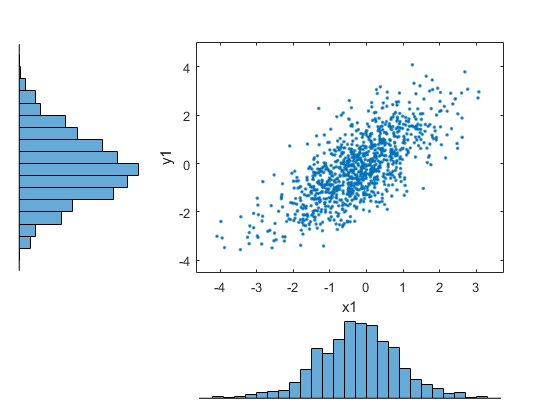
無作為標本を変換して、データのオリジナルのスケールに戻します。
x1 = ksdensity(x,u1,'function','icdf'); y1 = ksdensity(y,v1,'function','icdf'); figure; scatterhist(x1,y1) set(get(gca,'children'),'marker','.')
入力引数
名前と値の引数
出力引数
アルゴリズム
既定の設定では、copulafit は最尤法を使用してコピュラを u に当てはめます。周辺累積分布関数のパラメトリック推定によって単位超立方体に変換したデータが u に含まれている場合、これは "Inference Functions for Margins (IFM)" 法と呼ばれます。経験累積分布関数 (ecdf 参照) によって変換されたデータが u に含まれている場合、これは "正準最尤法" と呼ばれます。
参照
[1] Bouyé, E., V. Durrleman, A. Nikeghbali, G. Riboulet, and T. Roncalli. “Copulas for Finance: A Reading Guide and Some Applications.” Working Paper. Groupe de Recherche Opérationnelle, Crédit Lyonnais, Paris, 2000.
バージョン履歴
R2007b で導入