PID コントローラーの制約の学習と適用
この例では、データから制約を学習させ、それらの制約を PID 制御アプリケーションに適用する方法を示します。最初に、深層ニューラル ネットワークを使用して制約関数に学習させます。これには Deep Learning Toolbox™ ソフトウェアが必要です。その後、Constraint Enforcement ブロックを使用して PID 制御動作に制約を適用します。
この例では、プラント ダイナミクスは次の方程式 [1] で記述されます。
プラントの目標は、次の軌跡を追跡することです。
同じ PID 制御アプリケーションに既知の制約関数を適用する例については、PID コントローラーに対する制約の適用を参照してください。
乱数シードを設定し、モデルのパラメーターと初期条件を構成します。
rng(0); % Random seed r = 1.5; % Radius for desired trajectory Ts = 0.1; % Sample time Tf = 22; % Duration x0_1 = -r; % Initial condition for x1 x0_2 = 0; % Initial condition for x2 maxSteps = Tf/Ts; % Simulation steps
PID コントローラーの設計
制約を学習させて適用する前に、基準軌跡を追跡するための PID コントローラーを設計します。trackingWithPIDs モデルには、PID 調整器アプリを使用して調整されたゲインをもつ 2 つの PID コントローラーが含まれています。Simulink® モデルにおける PID コントローラーの調整の詳細については、Simulink でのモデルベースの PID 調整の紹介を参照してください。
mdl = "trackingWithPIDs";
open_system(mdl)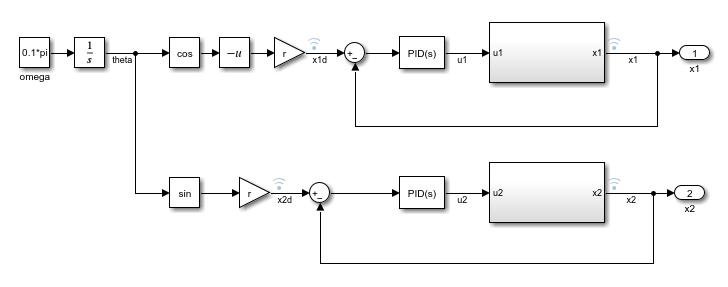
PID コントローラーをシミュレートし、追従性能をプロットします。
% Simulate the model. out = sim(mdl); % Extract trajectories. logData = out.logsout; x1_traj = logData{3}.Values.Data; x2_traj = logData{4}.Values.Data; x1_des = logData{1}.Values.Data; x2_des = logData{2}.Values.Data; % Plot trajectories. figure(Name="Tracking") xlim([-2,2]) ylim([-2,2]) plot(x1_des,x2_des,"r") xlabel("x1") ylabel("x2") hold on plot(x1_traj,x2_traj,"b:",LineWidth=2) hold on plot(x1_traj(1),x2_traj(1),"g*") hold on plot(x1_traj(end),x2_traj(end),"go") legend("Desired","Trajectory","Start","End", ... Location="best")

制約関数
この例では、アプリケーションの制約を学習させ、それらの制約を満たすように PID コントローラーの制御動作を変更します。
プラントの実行可能領域は、制約 で与えられます。したがって、軌跡 は を満たさなければなりません。
プラント ダイナミクスを次の方程式で近似できます。
制約をこの方程式に適用すると、以下の制約関数が生成されます。
Constraint Enforcement ブロックは、形式 の制約を受け入れます。このアプリケーションの場合、この制約関数の係数は以下のとおりです。
制約関数の学習
この例では、制約関数の係数が不明です。したがって、学習データから導出しなければなりません。学習データの収集には rlCollectDataPID モデルを使用します。このモデルでは、プラント モデルにゼロまたは乱数のいずれかの入力を渡し、結果のプラント出力を記録できます。
mdl = "rlCollectDataPID";
open_system(mdl)
不明な行列 を学習させるには、プラント入力をゼロに設定します。これを行うと、プラント ダイナミクスは となります。
blk = mdl + "/Manual Switch"; set_param(blk,"sw","1");
補助関数 collectDataPID を使用して学習データを収集します。この関数は、モデルを複数回シミュレートし、入出力データを抽出します。また、この関数は学習データの形式を整えて、、、、、、および の 6 列で構成される配列にします。
numSamples = 1000; data = collectDataPID(mdl,numSamples);
入出力データを使用して の最小二乗解を求めます。
inputData = data(:,1:2); outputData = data(:,5:6); A = inputData\outputData;
学習データを収集します。不明な関数 を学習させるには、正規分布する乱数の入力値を使用するようにモデルを構成します。
% Configure model to use random input data. set_param(blk,"sw","0"); % Collect data. data = collectDataPID(mdl,numSamples);
trainConstraintPID 補助関数を使用して、深層ニューラル ネットワークに学習させて 関数を近似します。この関数は、学習するデータの形式を整えてから、深層ニューラル ネットワークを作成して学習させます。深層ニューラル ネットワークの学習には Deep Learning Toolbox ソフトウェアが必要です。
深層ニューラル ネットワークへの入力はプラントの状態です。収集された状態情報を抽出して入力学習データを作成します。
inputData = data(:,1:2);
深層ニューラル ネットワークの出力は に対応するため、出力学習データは収集された入出力データと計算された 行列を使用して導出しなければなりません。
u = data(:,3:4); x_next = data(:,5:6); fx = (A*inputData')'; outputData = (x_next - fx)./u;
入出力データを使用してネットワークの学習を行います。
network = trainConstraintPID(inputData,outputData);
Iteration Epoch TimeElapsed LearnRate TrainingLoss ValidationLoss
_________ _____ ___________ _________ ____________ ______________
0 0 00:00:00 0.01 0.020006
1 1 00:00:02 0.01 0.017356
50 17 00:00:03 0.01 0.00045822 0.00054544
100 34 00:00:03 0.01 0.00070463 0.00026694
150 50 00:00:04 0.01 0.00028078 0.00021925
200 67 00:00:04 0.01 0.0020676 0.00020191
250 84 00:00:05 0.01 0.00043562 0.0001878
300 100 00:00:05 0.01 0.002279 0.00021469
Training stopped: Max epochs completed
結果のネットワークを MAT ファイルに保存します。
save("trainedNetworkPID","network")
制約の適用を使用した PID コントローラーのシミュレーション
制約の適用を使用した PID コントローラーのシミュレーションには trackingWithLearnedConstraintPID モデルを使用します。このモデルでは、コントローラーの出力をプラントへの適用前に制約します。
mdl = "trackingWithLearnedConstraintPID";
open_system(mdl)
制約の実装を表示するには、Constraint サブシステムを開きます。ここで、学習済みの深層ニューラル ネットワークによって現在のプラントの状態に基づいて が近似され、Constraint Enforcement ブロックによって制約関数が適用されます。

モデルをシミュレートし、結果をプロットします。
% Simulate the model. out = sim(mdl); % Extract trajectories. logData = out.logsout; x1_traj = zeros(size(out.tout)); x2_traj = zeros(size(out.tout)); for ct = 1:size(out.tout,1) x1_traj(ct) = logData{4}.Values.Data(:,:,ct); x2_traj(ct) = logData{5}.Values.Data(:,:,ct); end x1_des = logData{2}.Values.Data; x2_des = logData{3}.Values.Data; % Plot trajectories. figure("Name","Tracking with Constraint"); plot(x1_des,x2_des,"r") xlabel("x1") ylabel("x2") hold on plot(x1_traj,x2_traj,"b:",LineWidth=2) hold on plot(x1_traj(1),x2_traj(1),"g*") hold on plot(x1_traj(end),x2_traj(end),"go") legend("Desired","Trajectory","Start","End",... Location="best")
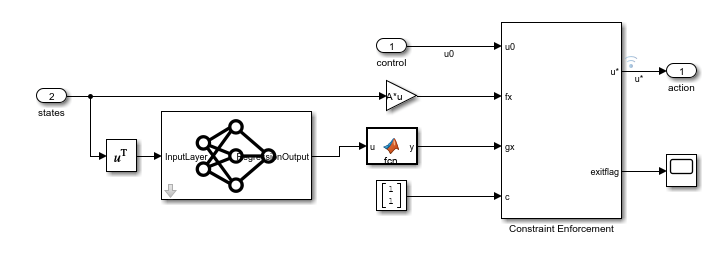
Constraint Enforcement ブロックによって、プラントが 1 より小さい状態を維持するように、正常に制御動作が制約されています。
参考文献
[1] Robey, Alexander, Haimin Hu, Lars Lindemann, Hanwen Zhang, Dimos V. Dimarogonas, Stephen Tu, and Nikolai Matni. "Learning Control Barrier Functions from Expert Demonstrations." Preprint, submitted April 7, 2020. https://arxiv.org/abs/2004.03315