制約の適用を使用した強化学習エージェントの学習
この例では、Constraint Enforcement ブロックを使用してアクションを制約して強化学習 (RL) エージェントに学習させる方法を示します。このブロックは、制約とアクション範囲に従って、エージェントによるアクションの出力に最も近い変更された制御アクションを計算します。強化学習エージェントの学習には Reinforcement Learning Toolbox™ ソフトウェアが必要です。
この例におけるエージェントの目標は、緑色のボールを赤色のボールの変化するターゲット位置に可能な限り近づけることです [1]。
緑色のボールの速度 から位置 へのダイナミクスは、減衰係数 が小さいニュートンの法則によって制御されます。
緑色のボールの位置 と速度の実行可能領域は の範囲に制限されます。
ターゲットの赤色のボールの位置は の範囲の一様な乱数です。このターゲット位置について、エージェントはノイズを含む推定しか観測できません。
乱数シードを設定し、再現性を確保します。
rng("default")モデル パラメーターを構成します。
Tv = 0.8; % sample time for visualizer Ts = 0.1; % sample time for controller tau = 0.01; % damping constant for green ball velLimit = 1; % maximum speed for green ball s0 = 200; % random seed s1 = 100; % random seed x0 = 0.2; % initial position for ball
データ収集用の環境とエージェントの作成
この例では、学習させた深層ニューラル ネットワークを使用して制約関数を表します。ネットワークに学習させるには、最初に環境から学習データを収集しなければなりません。
そのため、まず rlBallOneDim モデルを使用して RL 環境を作成します。このモデルでは、RL Agent ブロックを介してランダムな外部アクションを環境に適用します。
mdl = "rlBallOneDim";
open_system(mdl)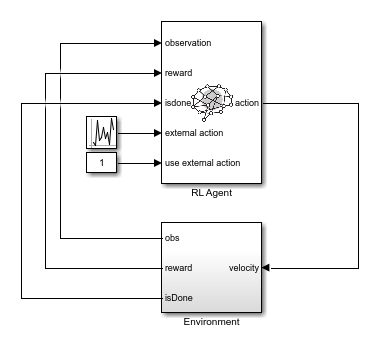
Environment サブシステムで実行される手順は次のとおりです。
入力速度を環境モデルに適用して結果の出力観測を生成
学習報酬 を計算 ( は赤色のボールの位置)
ボールの位置が制約 に違反する場合に終端信号
isDoneをtrueに設定
このモデルの環境からの観測には、緑色のボールの位置と速度、および赤色のボールの位置のノイズを含む測定が含まれます。それらの 3 つの値についての連続観測空間を定義します。
obsInfo = rlNumericSpec([3 1]);
緑色のボールに対してエージェントが適用するアクションはボールの速度です。連続行動空間を作成し、必要な速度範囲を適用します。
actInfo = rlNumericSpec([1 1], ... LowerLimit=-velLimit, ... UpperLimit=velLimit);
このモデルの RL 環境を作成します。
agentblk = mdl + "/RL Agent";
env = rlSimulinkEnv(mdl,agentblk,obsInfo,actInfo);各学習エピソードまたはシミュレーションの開始時に環境をランダムに初期化するリセット関数を指定します。
env.ResetFcn = @(in)localResetFcn(in);
次に、補助関数 createDDPGAgentBall を使用して、連続行動と連続観測をサポートする DDPG 強化学習エージェントを作成します。この関数は、アクション仕様と観測仕様に基づいてクリティック表現とアクター表現を作成し、その表現を使用して DDPG エージェントを作成します。
agent = createDDPGAgentBall(Ts,obsInfo,actInfo);
rlBallOneDim モデルでは、RL Agent ブロックはアクションを生成しません。代わりに、ランダムな外部アクションを環境に渡すように構成されています。データ収集モデルで非アクティブな RL Agent ブロックを使用するのは、データ収集で使用する環境モデル、アクション信号と観測信号の構成、およびモデルのリセット関数をその後のエージェントの学習で使用するものと確実に一致させるためです。
制約関数の学習
この例では、ボールの位置の信号 は を満たさなければなりません。多少のスラックを考慮して、制約は に設定します。速度から位置への動的モデルは、減衰定数が非常に小さいため、 で近似できます。したがって、緑色のボールの制約は次の方程式で求められます。
Constraint Enforcement ブロックは、形式 の制約を受け入れます。上記の方程式の場合、この制約関数の係数は次のようになります。
関数 は、環境内で RL エージェントをシミュレートすることで収集されたデータに基づいて学習させた深層ニューラル ネットワークで近似されます。不明な関数 を学習させるために、RL エージェントは の範囲で一様分布するランダムな外部アクションを環境に渡します。
データの収集には補助関数 collectDataBall を使用します。この関数は、環境とエージェントをシミュレートし、結果の入出力データを収集します。結果の学習データには、、、および の 3 つの列があります。
この例では、事前に収集した学習データを読み込みます。自分でデータを収集する場合は、collectData を true に設定します。
collectData = false; if collectData count = 1050; data = collectDataBall(env,agent,count); else load("trainingDataBall.mat","data") end
補助関数 trainConstraintBall を使用して、深層ニューラル ネットワークに学習させて制約関数を近似します。この関数は、学習するデータの形式を整えてから、深層ニューラル ネットワークを作成して学習させます。深層ニューラル ネットワークの学習には Deep Learning Toolbox™ ソフトウェアが必要です。
この例では、再現性を確保するために、事前学習済みのネットワークを読み込みます。自分でネットワークに学習させる場合は、trainConstraint を true に設定します。
trainConstraint = false; if trainConstraint network = trainConstraintBall(data); else load("trainedNetworkBall.mat","network") end
次の図は、学習の進行状況の例を示しています。
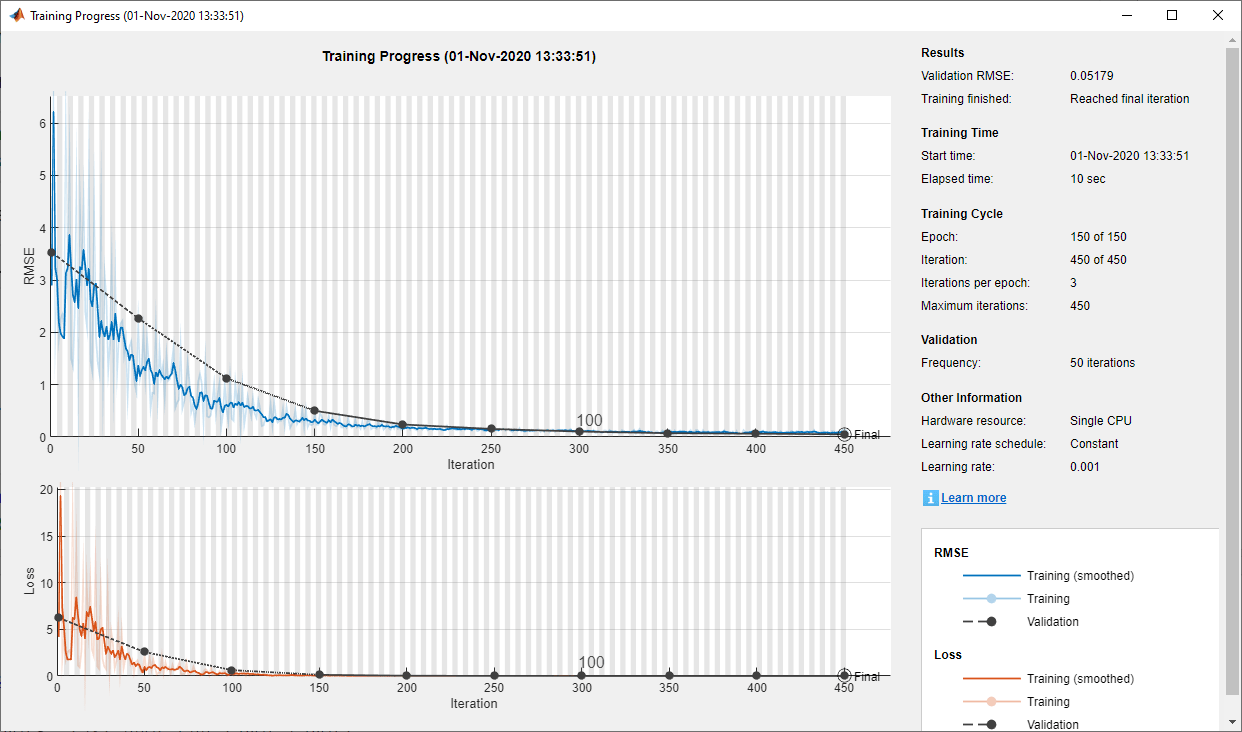
補助関数 validateNetworkBall を使用して学習済みのニューラル ネットワークを検証します。この関数は、学習済みの深層ニューラル ネットワークを使用して入力学習データを処理します。その後、ネットワークの出力を学習の出力と比較し、平方根平均二乗誤差 (RMSE) を計算します。
validateNetworkBall(data,network)
Test Data RMSE = 9.100315e-02
RMSE の値が小さく、ネットワークが制約関数を正しく学習したことを示しています。
制約の適用を使用したエージェントの学習
制約の適用を使用したエージェントの学習には rlBallOneDimWithConstraint モデルを使用します。このモデルでは、エージェントからのアクションを環境への適用前に制約します。
mdl = "rlBallOneDimWithConstraint";
open_system(mdl)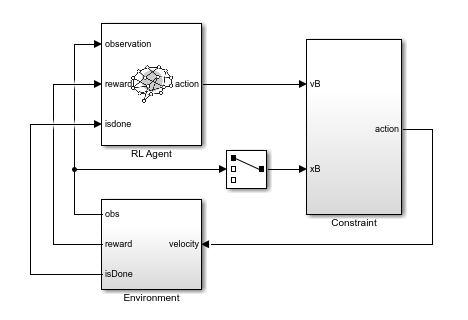
制約の実装を表示するには、Constraint サブシステムを開きます。ここで、学習済みの深層ニューラル ネットワークによって が近似され、Constraint Enforcement ブロックによって制約関数と速度範囲が適用されます。
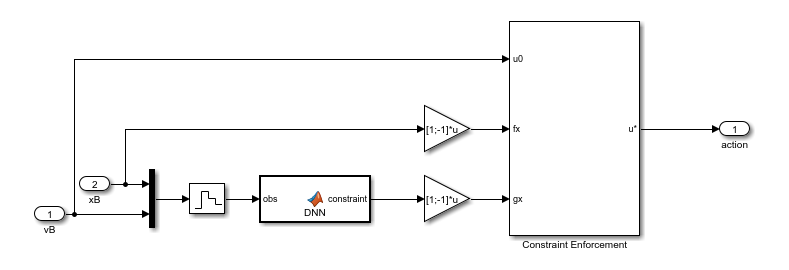
この例で使用する Constraint Enforcement ブロック パラメーター設定は次のとおりです。
制約数 —
2アクション数 —
1制約範囲 —
[0.9;-0.1]
このモデルを使用して RL 環境を作成します。使用する観測仕様とアクション仕様は前のデータ収集環境と同じです。
agentblk = mdl + "/RL Agent";
env = rlSimulinkEnv(mdl,agentblk,obsInfo,actInfo);
env.ResetFcn = @(in)localResetFcn(in);エージェントの学習のオプションを指定します。エピソードあたり 300 ステップを指定して 120 エピソードを RL エージェントに学習させます。
trainOpts = rlTrainingOptions(... MaxEpisodes=120, ... MaxStepsPerEpisode=300, ... Verbose=false, ... Plots="training-progress");
エージェントに学習させます。学習は時間がかかるプロセスです。この例では、事前学習済みのエージェントを読み込みます。自分でエージェントに学習させる場合は、trainAgent を true に設定します。
trainAgent = false; if trainAgent trainingStats = train(agent,env,trainOpts); else load("rlAgentBallParams.mat","agent") end
次の図に学習結果を示します。学習プロセスは 40 エピソードまでに良好なエージェントに収束しています。
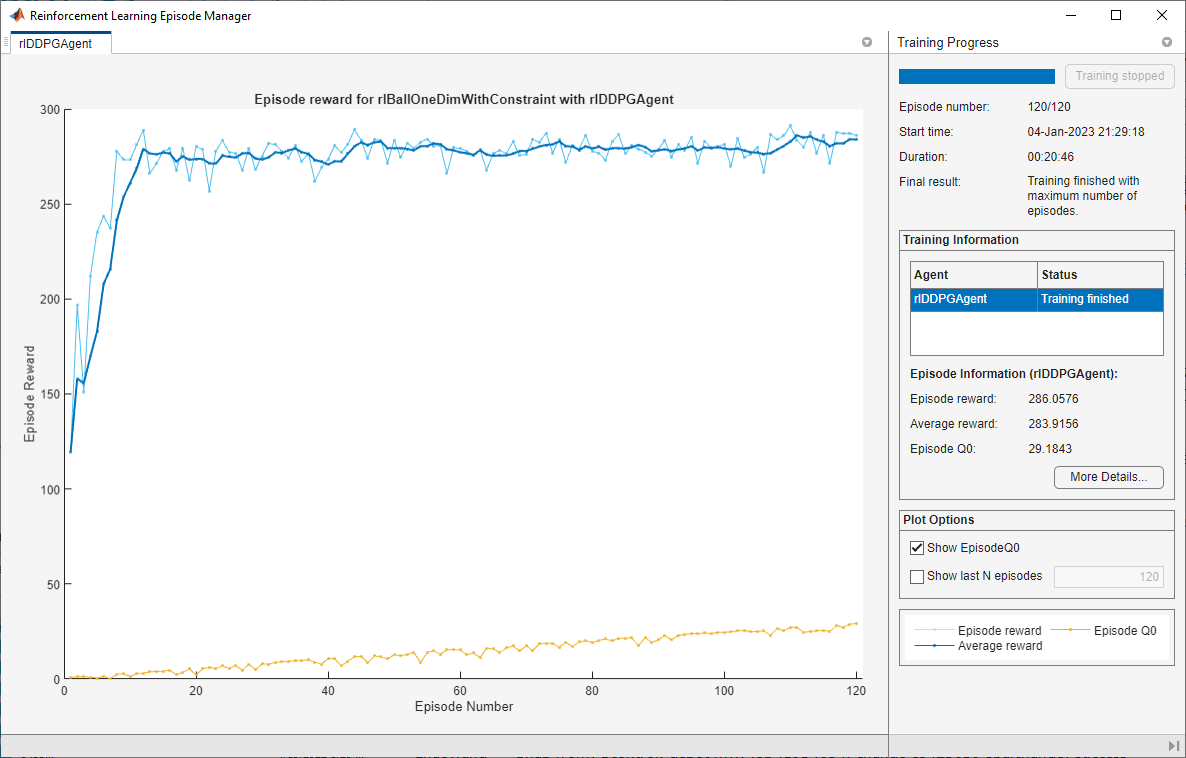
[合計ステップ数] が [エピソード番号] と [エピソード ステップ] の積に等しいことから、各学習エピソードが完了前に終了せずに最後まで実行されています。したがって、Constraint Enforcement ブロックにより、ボールの位置 が制約 に違反しないようになります。
補助関数 simWithTrainedAgentBall を使用して学習済みのエージェントをシミュレートします。
simWithTrainedAgentBall(env,agent)


エージェントは赤色のボールの位置を正しく追跡しています。
制約の適用なしのエージェントの学習
エージェントの学習に制約の適用を使用する利点を確認するために、制約なしでエージェントに学習させ、学習結果を制約の適用を使用した場合と比較できます。
制約なしのエージェントの学習には rlBallOneDimWithoutConstraint モデルを使用します。このモデルでは、エージェントからのアクションを環境にそのまま適用します。
mdl = "rlBallOneDimWithoutConstraint";
open_system(mdl)
このモデルを使用して RL 環境を作成します。
agentblk = mdl + "/RL Agent";
env = rlSimulinkEnv(mdl,agentblk,obsInfo,actInfo);
env.ResetFcn = @(in)localResetFcn(in);学習させる新しい DDPG エージェントを作成します。このエージェントの構成は前の学習で使用したエージェントと同じにします。
agentNoConstraint = createDDPGAgentBall(Ts,obsInfo,actInfo);
制約の適用を使用した場合と同じ学習オプションを使用してエージェントに学習させます。この例では、前の学習と同じように、事前学習済みのエージェントを読み込みます。自分でエージェントに学習させる場合は、trainAgent を true に設定します。
trainAgent = false; if trainAgent trainingStats2 = train(agentNoConstraint,env,trainOpts); else load("rlAgentBallCompParams.mat","agentNoConstraint") end
次の図に学習結果を示します。学習プロセスは約 90 エピソードを過ぎたところで良好なエージェントに収束しています。
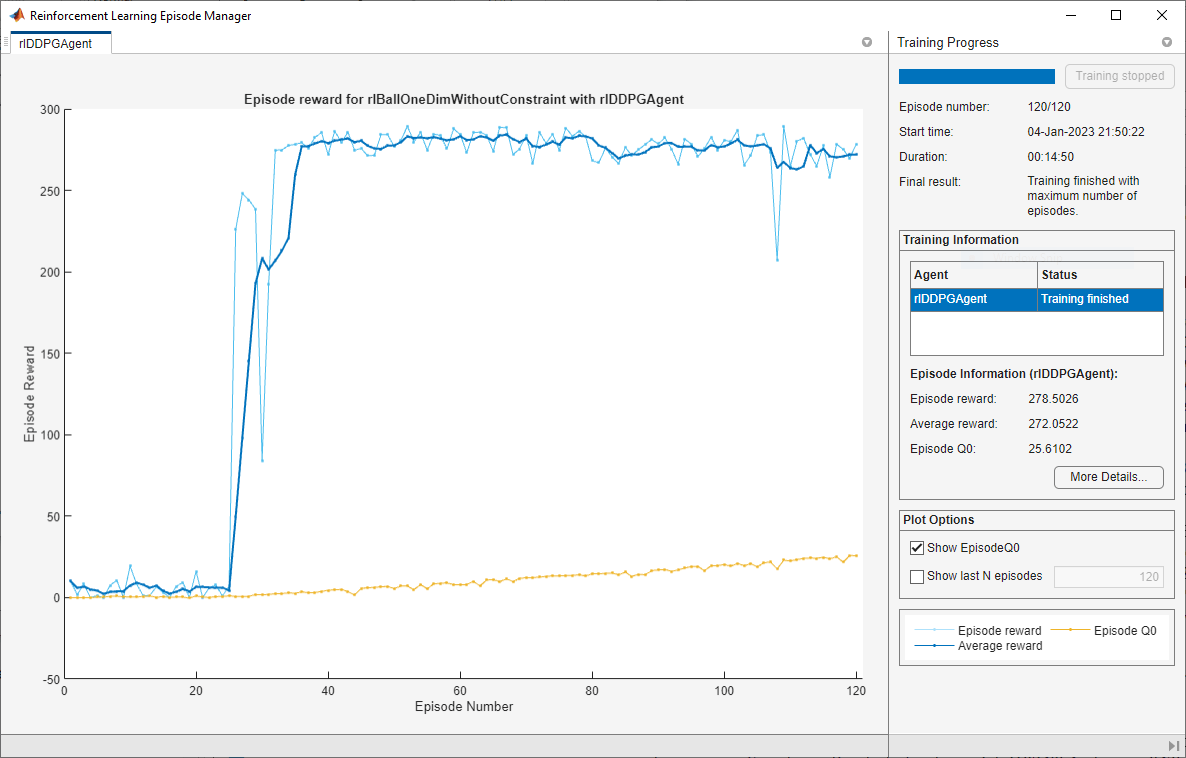
[合計ステップ数] が [エピソード番号] と [エピソード ステップ] の積よりも小さいことから、制約違反によって完了前に終了したエピソードが学習に含まれています。
学習済みのエージェントをシミュレートします。
simWithTrainedAgentBall(env,agentNoConstraint)

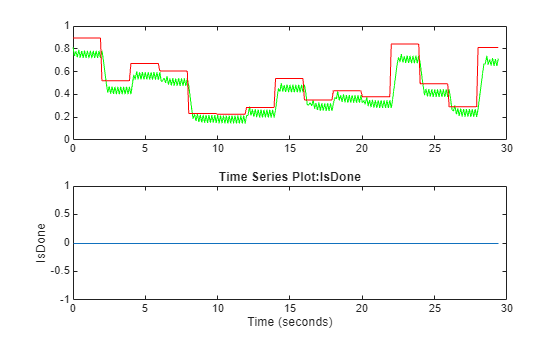
エージェントは赤色のボールの位置を追跡していますが、定常状態オフセットは制約ありで学習させたエージェントよりも大きくなっています。
まとめ
この例では、Constraint Enforcement ブロックを使用して RL エージェントに学習させることにより、環境に適用されるアクションで制約違反が発生しないようにします。その結果、学習プロセスは迅速に良好なエージェントに収束します。同じエージェントに制約なしで学習させた場合、収束までに時間がかかり、性能も低下します。
close("Ball One Dim")ローカル リセット関数
function in = localResetFcn(in) % Reset function in = setVariable(in,"x0",rand); in = setVariable(in,"s0",randi(5000)); in = setVariable(in,"s1",randi(5000)); end
参考文献
[1] Dalal, Gal, Krishnamurthy Dvijotham, Matej Vecerik, Todd Hester, Cosmin Paduraru, and Yuval Tassa. "Safe Exploration in Continuous Action Spaces." Preprint, submitted January 26, 2018. https://arxiv.org/abs/1801.08757
参考
ブロック
- Constraint Enforcement | RL Agent (Reinforcement Learning Toolbox)