制約の適用を使用した車線維持支援用の RL エージェントの学習
この例では、Constraint Enforcement ブロックを使用して制約を適用して車線維持支援 (LKA) 用の強化学習 (RL) エージェントに学習させる方法を示します。
概要
この例における目標は、フロント ステアリング角度を調整することで、自車を車線の中央に沿って走行させることです。この例では、並列計算を使用した車線維持支援用 DQN エージェントの学習 (Reinforcement Learning Toolbox)の例と同じ車両モデルおよびパラメーターを使用します。
乱数シードを設定し、モデルのパラメーターを構成します。
% Set random seed. rng(0); % Parameters m = 1575; % Total vehicle mass (kg) Iz = 2875; % Yaw moment of inertia (mNs^2) lf = 1.2; % Longitudinal distance from center of gravity to front tires (m) lr = 1.6; % Longitudinal distance from center of gravity to rear tires (m) Cf = 19000; % Cornering stiffness of front tires (N/rad) Cr = 33000; % Cornering stiffness of rear tires (N/rad) Vx = 15; % Longitudinal velocity (m/s) Ts = 0.1; % Sample time (s) T = 15; % Duration (s) rho = 0.001; % Road curvature (1/m) e1_initial = 0.2; % Initial lateral deviation from center line (m) e2_initial = -0.1; % Initial yaw angle error (rad) steerLimit = 0.2618;% Maximum steering angle for driver comfort (rad)
データ収集用の環境とエージェントの作成
この例では、Constraint Enforcement ブロックによって適用される制約関数が不明です。関数を学習させるには、最初に環境から学習データを収集しなければなりません。
そのため、まず rlLearnConstraintLKA モデルを使用して RL 環境を作成します。このモデルでは、RL Agent ブロックを介してランダムな外部アクションを環境に適用します。
mdl = "rlLearnConstraintLKA";
open_system(mdl)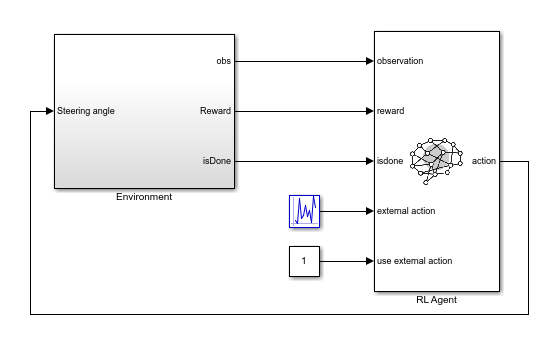
環境からの観測は、横方向の偏差 、相対ヨー角 、およびそれらの微分と積分です。それらの 6 つの信号についての連続観測空間を作成します。
obsInfo = rlNumericSpec([6 1]);
RL Agent ブロックからのアクションはフロント ステアリング角度で、-15 度から 15 度までの 31 個の値のうちのいずれかになります。この信号についての離散行動空間を作成します。
actInfo = rlFiniteSetSpec((-15:15)*pi/180);
このモデルの RL 環境を作成します。
agentblk = mdl + "/RL Agent";
env = rlSimulinkEnv(mdl,agentblk,obsInfo,actInfo);各学習エピソードまたはシミュレーションの開始時に横方向の偏差と相対ヨー角をランダムに初期化するリセット関数を指定します。
env.ResetFcn = @(in)localResetFcn(in);
次に、補助関数 createDQNAgentLKA を使用して、離散行動と連続観測をサポートする DQN 強化学習エージェントを作成します。この関数は、アクション仕様と観測仕様に基づいてクリティック表現を作成し、その表現を使用して DQN エージェントを作成します。
agent = createDQNAgentLKA(Ts,obsInfo,actInfo);
rlLearnConstraintLKA モデルでは、RL Agent ブロックはアクションを生成しません。代わりに、ランダムな外部アクションを環境に渡すように構成されています。データ収集モデルで非アクティブな RL Agent ブロックを使用するのは、データ収集で使用する環境モデル、アクション信号と観測信号の構成、およびモデルのリセット関数をその後のエージェントの学習で使用するものと確実に一致させるためです。
制約関数の学習
この例では、安全信号は です。この信号の制約は で、つまり車線の中央からの距離が 1 未満でなければなりません。この制約は、 における横方向の偏差とその微分、およびヨー角の誤差とその微分の状態に依存します。アクション はフロント ステアリング角度です。状態と横方向の偏差の関係は次の方程式で記述されます。
多少のスラックを考慮して、横方向の最大距離を 0.9 に設定します。
Constraint Enforcement ブロックは、形式 の制約を受け入れます。前述の方程式と制約の場合、制約関数の係数は次のようになります。
不明な関数 と を学習させるために、RL エージェントは [–0.2618, 0.2618] の範囲で一様分布するランダムな外部アクションを環境に渡します。
データの収集には補助関数 collectDataLKA を使用します。この関数は、環境とエージェントをシミュレートし、結果の入出力データを収集します。結果の学習データには 8 つの列があり、その最初の 6 つが RL エージェントの観測です。
横方向の偏差の積分
横方向の偏差
ヨー角の誤差の積分
ヨー角の誤差
横方向の偏差の微分
ヨー角の誤差の微分
ステアリング角度
次のタイム ステップにおける横方向の偏差
この例では、事前に収集した学習データを読み込みます。自分でデータを収集する場合は、collectData を true に設定します。
collectData = false; if collectData count = 1050; data = collectDataLKA(env,agent,count); else load trainingDataLKA data end
この例では、自車のダイナミクスは線形です。したがって、横方向の偏差の制約についての最小二乗解を求めることができます。
線形近似を適用して、不明な関数 と を学習させることができます。
% Extract state and input data. inputData = data(1:1000,[2,5,4,6,7]); % Extract data for the lateral deviation in the next time step. outputData = data(1:1000,8); % Compute the relation from the state and input to the lateral deviation. relation = inputData\outputData; % Extract the components of the constraint function coefficients. Rf = relation(1:4)'; Rg = relation(5);
補助関数 validateConstraintLKA を使用して学習済みの制約を検証します。この関数は、学習済みの制約を使用して入力学習データを処理します。その後、ネットワークの出力を学習の出力と比較し、平方根平均二乗誤差 (RMSE) を計算します。
validateConstraintLKA(data,Rf,Rg);
Test Data RMSE = 8.569169e-04
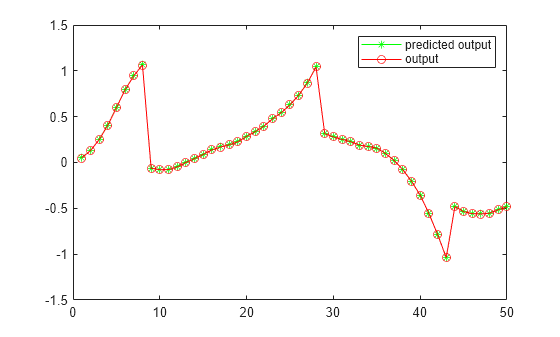
RMSE の値が小さく、制約の学習が正しく完了したことを示しています。
制約の適用を使用した RL エージェントの学習
制約の適用を使用したエージェントの学習には rlLKAWithConstraint モデルを使用します。このモデルでは、エージェントからのアクションを環境への適用前に制約します。
mdl = "rlLKAwithConstraint";
open_system(mdl)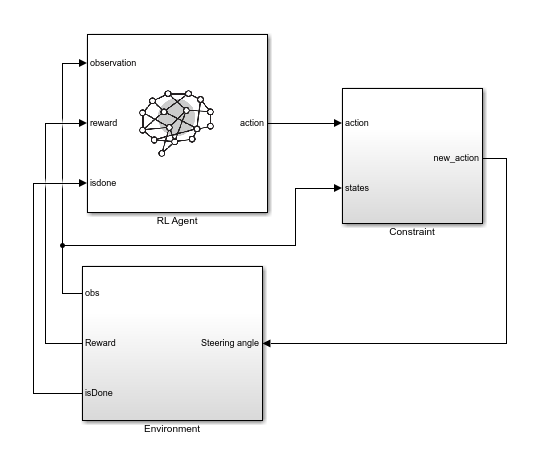
制約の実装を表示するには、Constraint サブシステムを開きます。ここで、線形制約の関係から と の値がモデルで生成されます。モデルでは、これらの値が制約範囲と一緒に Constraint Enforcement ブロックに送られます。

このモデルを使用して RL 環境を作成します。観測仕様とアクション仕様は制約学習環境と同じです。
Environment サブシステムでは、横方向の偏差が指定の制約を超えた場合に true の isDone 信号を作成します。RL Agent ブロックでは、この信号を使用して学習エピソードを完了前に終了します。
agentblk = mdl + "/RL Agent";
env = rlSimulinkEnv(mdl,agentblk,obsInfo,actInfo);
env.ResetFcn = @(in)localResetFcn(in);エージェントの学習のオプションを指定します。エージェントに最大 5000 エピソードまで学習させます。エピソード報酬が –1 を超えたら学習を停止します。
maxepisodes = 5000; maxsteps = ceil(T/Ts); trainingOpts = rlTrainingOptions(... MaxEpisodes=maxepisodes,... MaxStepsPerEpisode=maxsteps,... Verbose=false,... Plots="training-progress",... StopTrainingCriteria="EpisodeReward",... StopTrainingValue=-1);
エージェントに学習させます。学習は時間がかかるプロセスであるため、この例では事前学習済みのエージェントを読み込みます。代わりに自分でエージェントに学習させる場合は、trainAgent を true に設定します。
trainAgent = false; if trainAgent trainingStats = train(agent,env,trainingOpts); else load rlAgentConstraintLKA agent end
次の図に学習結果を示します。
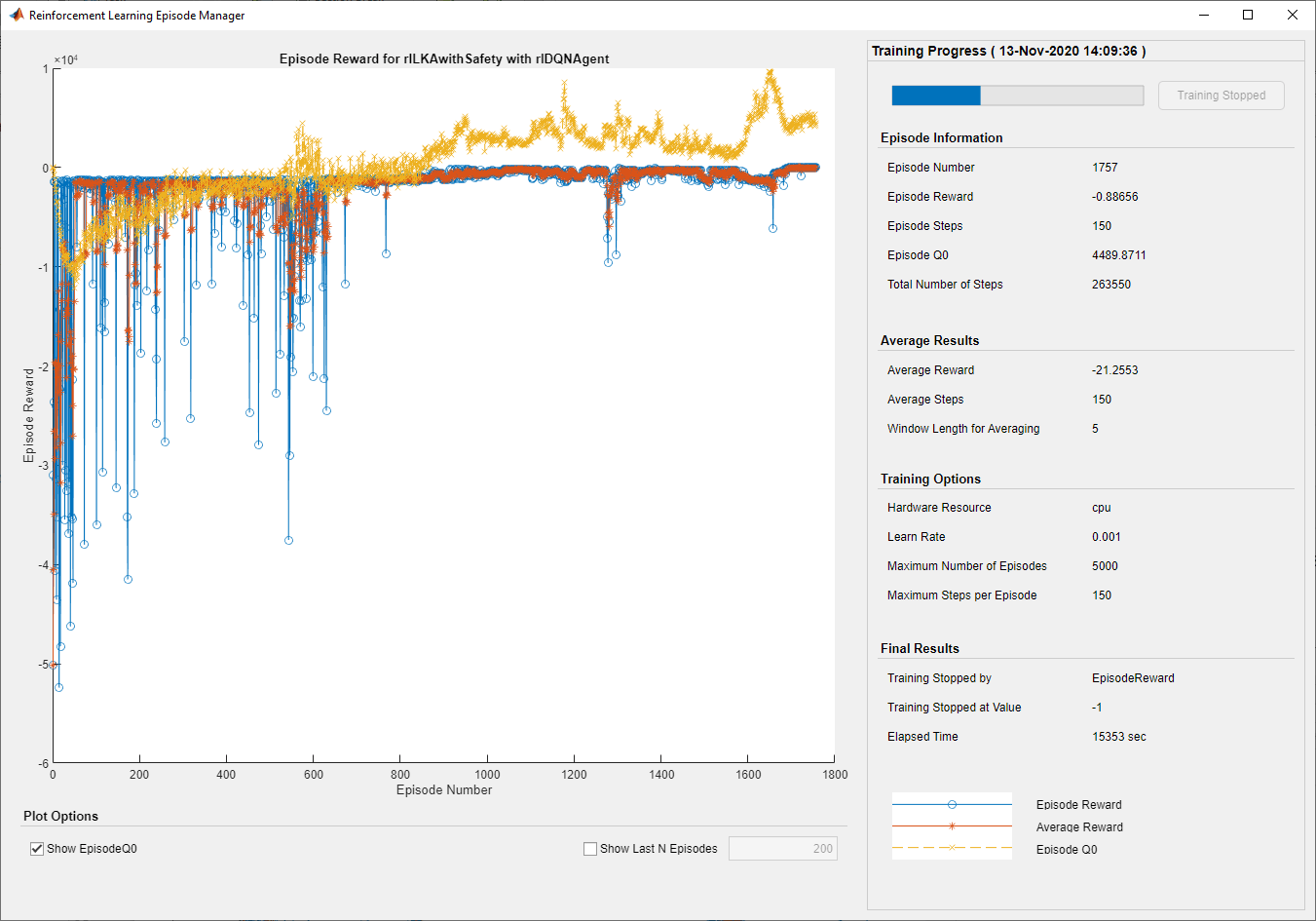
[合計ステップ数] が [エピソード番号] と [エピソード ステップ] の積に等しいことから、各学習エピソードが完了前に終了せずに最後まで実行されています。したがって、Constraint Enforcement ブロックにより、横方向の偏差が制約に違反しないようになります。
学習済みのエージェントを実行し、シミュレーション結果を確認します。
e1_initial = -0.4;
e2_initial = 0.2;
sim(mdl);
open_system(mdl + "/Environment/Lateral deviation")
ローカル リセット関数
function in = localResetFcn(in) % Set initial lateral deviation to random value. in = setVariable(in,"e1_initial", 0.5*(-1+2*rand)); % Set initial relative yaw angle to random value. in = setVariable(in,"e2_initial", 0.1*(-1+2*rand)); end
参考
ブロック
- Constraint Enforcement | RL Agent (Reinforcement Learning Toolbox)