このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
振子の振り上げと平衡化のための DDPG エージェントの学習
この例では、Simulink® でモデル化された振子の振り上げと平衡化を行うように、深層決定論的方策勾配 (DDPG) エージェントに学習させる方法を説明します。
DDPG エージェントの詳細については、深層決定論的方策勾配 (DDPG) エージェントを参照してください。MATLAB® で DDPG エージェントに学習させる例については、Compare DDPG Agent to LQR Controllerを参照してください。
再現性のための乱数ストリームの固定
サンプル コードには、さまざまな段階で乱数の計算が含まれる場合があります。サンプル コード内のさまざまなセクションの先頭にある乱数ストリームを固定すると、実行するたびにセクション内の乱数シーケンスが維持されるため、結果が再現される可能性が高くなります。詳細については、Results Reproducibilityを参照してください。
シード 0 で乱数ストリームを固定し、メルセンヌ・ツイスター乱数アルゴリズムを使用します。乱数生成に使用されるシード制御の詳細については、rngを参照してください。
previousRngState = rng(0,"twister");出力 previousRngState は、ストリームの前の状態に関する情報が格納された構造体です。例の最後で、状態を復元します。
振子振り上げモデル
この例では、初期状態で下向きにぶら下がっている摩擦がない単純な振子を、強化学習の環境として使用します。学習の目標は、最小限の制御操作を使用して振子を直立させることです。
モデルを開きます。
mdl = "rlSimplePendulumModel";
open_system(mdl)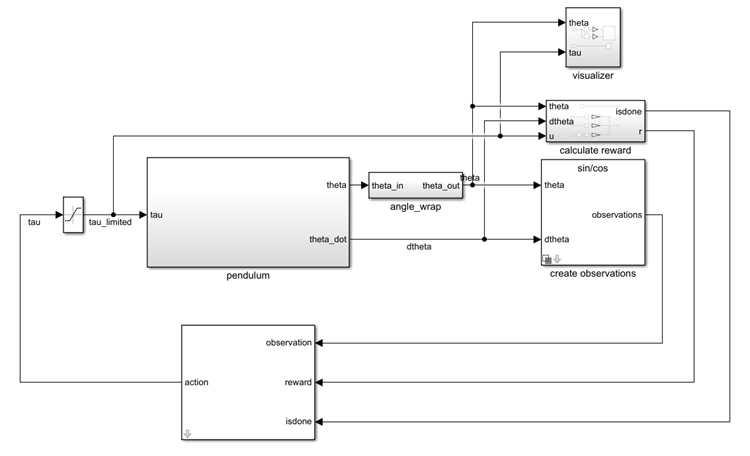
このモデルでは、次のようにします。
振子が直立平衡状態となっている位置を 0 ラジアン、振子が鉛直下向きになっている位置を
piラジアンとする。エージェントから環境へのトルク アクション信号は、–2 ~ 2 N m とする。
環境からの観測値は、振子角度の正弦、振子角度の余弦、および振子角度の微分とする。
各タイム ステップで与えられる報酬 は次のとおりとする。
ここで、以下となります。
は直立位置からの変位角。
は変位角の微分。
は前のタイム ステップからの制御量。
このモデルの詳細については、Use Predefined Control System Environmentsを参照してください。
環境インターフェイスの作成
振子の事前定義済み環境オブジェクトを作成します。
env = rlPredefinedEnv("SimplePendulumModel-Continuous")env =
SimulinkEnvWithAgent with properties:
Model : rlSimplePendulumModel
AgentBlock : rlSimplePendulumModel/RL Agent
ResetFcn : []
UseFastRestart : on
obsInfo = getObservationInfo(env);
このオブジェクトは、エージェントが -2 ~ 2 N·m のトルク値を振子に適用できる、連続行動空間をもちます。
actInfo = getActionInfo(env)
actInfo =
rlNumericSpec with properties:
LowerLimit: -2
UpperLimit: 2
Name: "torque"
Description: [0×0 string]
Dimension: [1 1]
DataType: "double"
環境の観測値を振子角度の正弦、振子角度の余弦、および振子角度の微分に設定します。
set_param( ... "rlSimplePendulumModel/create observations", ... "ThetaObservationHandling","sincos");
振子の初期状態を下向きにぶら下がっている状態として定義するには、無名関数ハンドルを使用して環境のリセット関数を指定します。このリセット関数は、モデル ワークスペース変数 theta0 を pi に設定します。
env.ResetFcn = @(in)setVariable(in,"theta0",pi,"Workspace",mdl);
エージェントのサンプル時間 Ts とシミュレーション時間 Tf を秒単位で指定します。
Ts = 0.05; Tf = 20;
DDPG エージェントの作成
エージェントを作成すると、アクター ネットワークとクリティック ネットワークがランダムに初期化されます。乱数生成に使用するシード値を固定することで、セクションの再現性を確保します。
rng(0,"twister")環境仕様オブジェクトを使用して、既定のrlDDPGAgentオブジェクトを作成します。
agent = rlDDPGAgent(obsInfo,actInfo);
環境内の RL Agent ブロックが、既定の設定の 1 秒ではなく Ts 秒ごとに確実に実行されるようにするには、エージェントの SampleTime プロパティを設定します。
agent.AgentOptions.SampleTime = Ts;
学習をより滑らかに (遅くなるとしても) 促進するために、学習率と勾配しきい値を低く設定します。
agent.AgentOptions.CriticOptimizerOptions.LearnRate = 1e-3; agent.AgentOptions.ActorOptimizerOptions.LearnRate = 1e-3; agent.AgentOptions.CriticOptimizerOptions.GradientThreshold = 1; agent.AgentOptions.ActorOptimizerOptions.GradientThreshold = 1;
経験バッファーの長さとミニ バッファーのサイズを増やします。
agent.AgentOptions.ExperienceBufferLength = 1e5; agent.AgentOptions.MiniBatchSize = 128;
エージェントの学習
エージェントに学習させるには、まず、学習オプションを指定します。この例では、次のオプションを使用します。
最大 5000 個のエピソードについて、学習を実行 (各エピソードの持続時間は最大
ceil(Tf/Ts)タイム ステップ)。[強化学習の学習モニター] ダイアログ ボックスに学習の進行状況を表示し (
Plotsオプションを設定)、コマンド ラインの表示を無効化 (Verboseオプションをfalseに設定)。決定論的方策を評価するときに、-740 よりも大きい平均累積報酬をエージェントが受け取った時点で学習を停止。この時点で、エージェントは最小限の制御操作を使用して、振子を直立位置で素早く平衡化できるようになります。
累積報酬が -740 よりも大きい各エピソードについてエージェントのコピーを保存。
学習オプションの詳細については、rlTrainingOptionsを参照してください。
maxepisodes = 5000; maxsteps = ceil(Tf/Ts); trainOpts = rlTrainingOptions(... MaxEpisodes=maxepisodes,... MaxStepsPerEpisode=maxsteps,... ScoreAveragingWindowLength=5,... Verbose=false,... Plots="training-progress",... StopTrainingCriteria="EvaluationStatistic",... StopTrainingValue=-740,... SaveAgentCriteria="EvaluationStatistic",... SaveAgentValue=-740);
関数 train を使用して、エージェントに学習させます。このエージェントの学習は計算量が多いプロセスのため、完了するのに数時間かかります。この例の実行時間を節約するために、doTraining を false に設定して事前学習済みのエージェントを読み込みます。エージェントに学習させるには、doTraining を true に設定します。
doTraining =false; if doTraining % Use the rlEvaluator object to measure policy performance every 10 % episodes evaluator = rlEvaluator(... NumEpisodes=1,... EvaluationFrequency=10); % Train the agent. trainingResults = train(agent,env,trainOpts,Evaluator=evaluator); else % Load the pretrained agent for the example. load("SimulinkPendulumDDPG.mat","agent") end
DDPG エージェントのシミュレーション
再現性のために乱数ストリームを固定します。
rng(0,"twister");学習済みエージェントの性能を検証するには、振子環境内でこれをシミュレートします。エージェントのシミュレーションの詳細については、rlSimulationOptions および sim を参照してください。
simOptions = rlSimulationOptions(MaxSteps=500); experience = sim(env,agent,simOptions);

totalReward = sum(experience.Reward)
totalReward = -731.2350
シミュレーションでは、エージェントが振子を垂直位置に安定させることが示されています。
previousRngState に保存されている情報を使用して、乱数ストリームを復元します。
rng(previousRngState);
参考
アプリ
関数
train|sim|rlSimulinkEnv
オブジェクト
rlDDPGAgent|rlDDPGAgentOptions|rlQValueFunction|rlContinuousDeterministicActor|rlTrainingOptions|rlSimulationOptions|rlOptimizerOptions