rlDDPGAgent
深層決定論的方策勾配 (DDPG) 強化学習エージェント
説明
深層決定論的方策勾配 (DDPG) アルゴリズムは、連続行動空間をもつ環境向けの Off-Policy actor-critic 手法です。DDPG エージェントは、決定論的方策を学習すると同時に、Q 値関数クリティックを使用して最適な方策の値を推定します。ターゲット アクターおよびターゲット クリティックに加え、経験バッファーを備えています。DDPG エージェントは、オフライン学習 (環境なしで保存されたデータからの学習) をサポートします。
詳細については、深層決定論的方策勾配 (DDPG) エージェントを参照してください。さまざまな種類の強化学習エージェントの詳細については、強化学習エージェントを参照してください。
作成
構文
説明
観測仕様とアクション仕様からのエージェントの作成
agent = rlDDPGAgent(observationInfo,actionInfo)observationInfo とアクション仕様 actionInfo から構築された既定の深層ニューラル ネットワークを使用します。agent の ObservationInfo プロパティと ActionInfo プロパティは、それぞれ observationInfo 入力引数と actionInfo 入力引数に設定されます。
agent = rlDDPGAgent(observationInfo,actionInfo,initOpts)initOpts オブジェクトで指定されたオプションを使用して構成された既定のネットワークを使用します。初期化オプションの詳細については、rlAgentInitializationOptions を参照してください。
アクターとクリティックからのエージェントの作成
エージェント オプションの指定
agent = rlDDPGAgent(___,agentOptions)AgentOptions プロパティを agentOptions 入力引数に設定します。この構文は、前の構文にある任意の入力引数の後に使用します。
入力引数
プロパティ
オブジェクト関数
train | Train reinforcement learning agents within a specified environment |
sim | Simulate trained reinforcement learning agents within specified environment |
getAction | Obtain action from agent, actor, or policy object given environment observations |
getActor | 強化学習エージェントからのアクターの抽出 |
setActor | Set actor of reinforcement learning agent |
getCritic | 強化学習エージェントからのクリティックの抽出 |
setCritic | Set critic of reinforcement learning agent |
generatePolicyFunction | Generate MATLAB function that evaluates policy of an agent or policy object |
例
連続行動空間をもつ環境を作成し、その観測仕様とアクション仕様を取得します。この例では、Compare DDPG Agent to LQR Controllerの例で使用されている環境を読み込みます。環境からの観測値は、質量の位置と速度を含むベクトルです。アクションは、質量に適用される力を表すスカラーであり、-2 ~ 2 ニュートンの範囲で連続的に変化します。
env = rlPredefinedEnv("DoubleIntegrator-Continuous");観測仕様とアクション仕様を取得します。
obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
エージェント作成関数は、アクター ネットワークとクリティック ネットワークをランダムに初期化します。乱数発生器のシード値を固定して、セクションの再現性を確保します。
rng(0)
環境の観測仕様とアクション仕様から方策勾配エージェントを作成します。
agent = rlDDPGAgent(obsInfo,actInfo)
agent =
rlDDPGAgent with properties:
ExperienceBuffer: [1×1 rl.replay.rlReplayMemory]
AgentOptions: [1×1 rl.option.rlDDPGAgentOptions]
UseExplorationPolicy: 0
ObservationInfo: [1×1 rl.util.rlNumericSpec]
ActionInfo: [1×1 rl.util.rlNumericSpec]
SampleTime: 1
UseGPUForLearning: 0
エージェントを確認するには、getAction 関数を使用して、10 個のランダムな観測値で構成されるバッチからアクションを返します。
robs = rand([obsInfo(1).Dimension 10]);
a = getAction(agent,{robs});アクション バッチの 7 番目の要素を表示します。
a{1}(7)ans = -0.0053
これで、環境内でエージェントのテストと学習ができるようになりました。また、getActorとgetCriticを使用してアクターとクリティックをそれぞれ抽出することも、getModelを使用してアクターまたはクリティックから近似器モデル (既定では深層ニューラル ネットワーク) を抽出することもできます。
連続行動空間をもつ環境を作成し、その観測仕様とアクション仕様を取得します。この例では、振子の振り上げと平衡化のための、イメージ観測を使用した DDPG エージェントの学習の例で使用されている環境を読み込みます。この環境には、50×50 のグレースケール イメージとスカラー (振子の角速度) から成る 2 つの観測値があります。アクションは、-2 ~ 2 Nm の範囲のトルクを表すスカラーです。
env = rlPredefinedEnv("SimplePendulumWithImage-Continuous");観測仕様とアクション仕様を取得します。
obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
エージェント初期化オプション オブジェクトを作成し、ネットワーク内の各隠れ全結合層に 128 個のニューロン (既定の数 256 ではなく) が必要であることを指定します。
initOpts = rlAgentInitializationOptions(NumHiddenUnit=128);
エージェント作成関数は、アクター ネットワークとクリティック ネットワークをランダムに初期化します。乱数発生器のシード値を固定することで再現性を確保できます。
rng(0)
環境の観測仕様とアクション仕様から DDPG エージェントを作成します。
agent = rlDDPGAgent(obsInfo,actInfo,initOpts);
エージェントのアクターおよびクリティックの両方から深層ニューラル ネットワークを抽出します。
actorNet = getModel(getActor(agent)); criticNet = getModel(getCritic(agent));
それぞれの隠れ全結合層に 128 個のニューロンがあることを検証するには、MATLAB® コマンド ウィンドウに層を表示します。
criticNet.Layers
または、analyzeNetworkを使用して構造体を対話的に可視化します。
analyzeNetwork(criticNet)
アクター ネットワークとクリティック ネットワークをプロットします。
plot(actorNet)
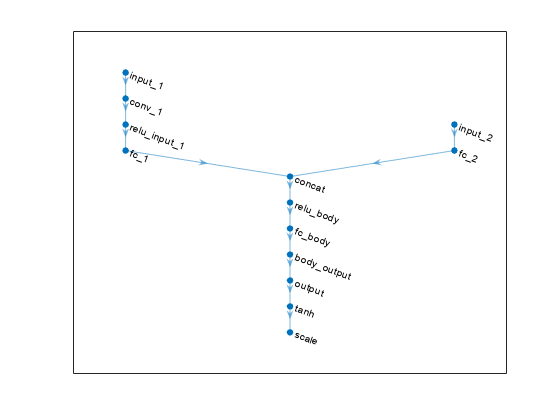
plot(criticNet)
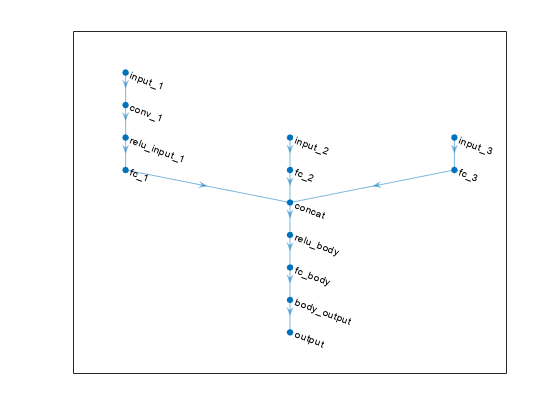
エージェントを確認するには、getAction 関数を使用してランダムな観測値からアクションを返します。
getAction(agent,{rand(obsInfo(1).Dimension),rand(obsInfo(2).Dimension)})ans = 1×1 cell array
{[-0.0364]}
これで、環境内でエージェントのテストと学習ができるようになりました。
連続行動空間をもつ環境を作成し、その観測仕様とアクション仕様を取得します。この例では、Compare DDPG Agent to LQR Controllerの例で使用されている環境を読み込みます。環境からの観測値は、質量の位置と速度を含むベクトルです。アクションは、-2 ~ 2 ニュートンまで連続的に変化する力を表すスカラーです。
env = rlPredefinedEnv("DoubleIntegrator-Continuous");環境の観測仕様オブジェクトとアクション仕様オブジェクトを取得します。
obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
アクター ネットワークとクリティック ネットワークはランダムに初期化されます。乱数発生器のシード値を固定して、セクションの再現性を確保します。
rng(0)
DDPG エージェントは、パラメーター化された Q 値関数近似器を使用して方策の価値を推定します。Q 値関数クリティックは、現在の観測値とアクションを入力として取り、単一のスカラーを出力として返します (状態からのアクションを取る割引累積長期報酬の推定値は、現在の観測値に対応し、その後の方策に従います)。
パラメーター化された Q 値関数をクリティック内でモデル化するには、2 つの入力層 (そのうち 1 つは obsInfo で指定された観測チャネル用で、もう 1 つは actInfo で指定されたアクション チャネル用) と 1 つの出力層 (これはスカラー値を返します) をもつニューラル ネットワークを使用します。
prod(obsInfo.Dimension) および prod(actInfo.Dimension) は、行ベクトル、列ベクトル、行列のいずれによって構成されているかにかかわらず、それぞれ観測値と行動空間の次元の数を返すことに注意してください。
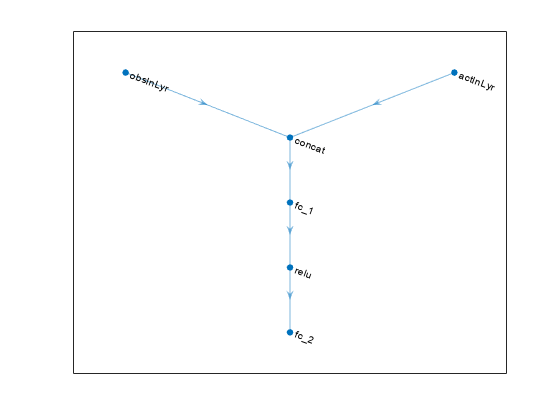
各ネットワーク パスを layer オブジェクトの配列として定義し、各パスの入力層と出力層に名前を割り当てます。これらの名前を使用すると、パスを接続してから、ネットワークの入力層と出力層に適切な環境チャネルを明示的に関連付けることができます。
% Define observation and action paths obsPath = featureInputLayer(prod(obsInfo.Dimension),Name="obsInLyr"); actPath = featureInputLayer(prod(actInfo.Dimension),Name="actInLyr"); % Define common path: concatenate along first dimension. commonPath = [ concatenationLayer(1,2,Name="concat") fullyConnectedLayer(50) reluLayer fullyConnectedLayer(1) ];
dlnetwork オブジェクトを組み立て、層を追加します。
criticNet = dlnetwork; criticNet = addLayers(criticNet, obsPath); criticNet = addLayers(criticNet, actPath); criticNet = addLayers(criticNet, commonPath);
パスを接続します。
criticNet = connectLayers(criticNet,"obsInLyr","concat/in1"); criticNet = connectLayers(criticNet,"actInLyr","concat/in2");
ネットワークをプロットします。
plot(criticNet)
ネットワークを初期化します。
criticNet = initialize(criticNet);
重みの数を表示します。
summary(criticNet)
Initialized: true
Number of learnables: 251
Inputs:
1 'obsInLyr' 2 features
2 'actInLyr' 1 features
criticNet、環境の観測仕様とアクション仕様、および環境の観測チャネルとアクション チャネルに接続されるネットワーク入力層の名前を使用して、クリティック近似器オブジェクトを作成します。詳細については、rlQValueFunctionを参照してください。
critic = rlQValueFunction(criticNet,obsInfo,actInfo, ... ObservationInputNames="obsInLyr", ... ActionInputNames="actInLyr");
ランダムな観測値とアクション入力を使用して、クリティックをチェックします。
getValue(critic,{rand(obsInfo.Dimension)},{rand(actInfo.Dimension)})ans = single
-0.4260
DDPG エージェントは、連続行動空間において、パラメーター化された決定論的方策を使用します。この方策は、連続決定論的アクターによって学習されます。このアクターは、現在の観測値を入力として取り、観測値の決定論的関数であるアクションを出力として返します。
パラメーター化された方策をアクター内でモデル化するには、1 つの入力層 (これは、obsInfo で指定された、環境観測チャネルのコンテンツを受け取ります) と 1 つの出力層 (これは、actInfo で指定された、環境アクション チャネルへのアクションを返します) をもつニューラル ネットワークを使用します。
ネットワークを layer オブジェクトの配列として定義します。
actorNet = [
featureInputLayer(prod(obsInfo.Dimension))
fullyConnectedLayer(16)
tanhLayer
fullyConnectedLayer(16)
tanhLayer
fullyConnectedLayer(prod(actInfo.Dimension))
];dlnetwork オブジェクトに変換します。
actorNet = dlnetwork(actorNet);
ネットワークを初期化します。
actorNet = initialize(actorNet);
重みの数を表示します。
summary(actorNet)
Initialized: true
Number of learnables: 337
Inputs:
1 'input' 2 features
actorNet および観測仕様とアクション仕様を使用して、アクターを作成します。連続決定論的アクターの詳細については、rlContinuousDeterministicActorを参照してください。
actor = rlContinuousDeterministicActor(actorNet,obsInfo,actInfo);
ランダムな観測値入力を使用して、アクターをチェックします。
getAction(actor,{rand(obsInfo.Dimension)})ans = 1×1 cell array
{[-0.5493]}
アクターとクリティックを使用して DDPG エージェントを作成します。
agent = rlDDPGAgent(actor,critic)
agent =
rlDDPGAgent with properties:
ExperienceBuffer: [1×1 rl.replay.rlReplayMemory]
AgentOptions: [1×1 rl.option.rlDDPGAgentOptions]
UseExplorationPolicy: 0
ObservationInfo: [1×1 rl.util.rlNumericSpec]
ActionInfo: [1×1 rl.util.rlNumericSpec]
SampleTime: 1
UseGPUForLearning: 0
アクターとクリティックの学習オプションを含むエージェント オプションを指定します。
agent.AgentOptions.SampleTime=env.Ts; agent.AgentOptions.TargetSmoothFactor=1e-3; agent.AgentOptions.ExperienceBufferLength=1e6; agent.AgentOptions.DiscountFactor=0.99; agent.AgentOptions.MiniBatchSize=32; agent.AgentOptions.CriticOptimizerOptions.LearnRate=5e-3; agent.AgentOptions.CriticOptimizerOptions.GradientThreshold=1; agent.AgentOptions.ActorOptimizerOptions.LearnRate=1e-4; agent.AgentOptions.ActorOptimizerOptions.GradientThreshold=1;
ランダムな観測入力を使用して、エージェントをチェックします。
getAction(agent,{rand(obsInfo.Dimension)})ans = 1×1 cell array
{[-0.5947]}
これで、環境内でエージェントに学習させることができるようになりました。
この例では、Compare DDPG Agent to LQR Controllerの例で使用されている環境を読み込みます。環境からの観測値は、質量の位置と速度を含むベクトルです。アクションは、-2 ~ 2 ニュートンまで連続的に変化する力を表すスカラーです。
env = rlPredefinedEnv("DoubleIntegrator-Continuous");観測仕様オブジェクトとアクション仕様オブジェクトを取得します。
obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
DDPG エージェントは、パラメーター化された Q 値関数近似器を使用して方策の価値を推定します。
クリティック内でパラメーター化された Q 値関数をモデル化するには、2 つの入力層と 1 つの出力層 (スカラー値を返す) をもつ再帰型ニューラル ネットワークを使用します。
各ネットワーク パスを layer オブジェクトの配列として定義します。再帰型ニューラル ネットワークを作成するには、入力層として sequenceInputLayer を使用し、他のネットワーク層の 1 つとして lstmLayer を含めます。
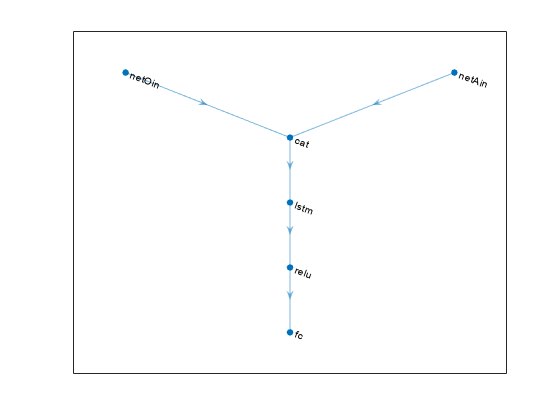
% Define observation and action paths obsPath = sequenceInputLayer(prod(obsInfo.Dimension),Name="netOin"); actPath = sequenceInputLayer(prod(actInfo.Dimension),Name="netAin"); % Define common path: concatenate along first dimension commonPath = [ concatenationLayer(1,2,Name="cat") lstmLayer(50) reluLayer fullyConnectedLayer(1) ];
dlnetwork オブジェクトを作成し、層を追加します。
criticNet = dlnetwork(); criticNet = addLayers(criticNet, obsPath); criticNet = addLayers(criticNet, actPath); criticNet = addLayers(criticNet, commonPath);
層を接続します。
criticNet = connectLayers(criticNet,"netOin","cat/in1"); criticNet = connectLayers(criticNet,"netAin","cat/in2");
ネットワークをプロットします。
plot(criticNet)
ネットワークを初期化し、重みの数を表示します。
criticNet = initialize(criticNet); summary(criticNet)
Initialized: true
Number of learnables: 10.9k
Inputs:
1 'netOin' Sequence input with 2 channels
2 'netAin' Sequence input with 1 channels
criticNet、環境の観測仕様とアクション仕様、および環境の観測チャネルとアクション チャネルに接続されるネットワーク入力層の名前を使用して、クリティック近似器オブジェクトを作成します。詳細については、rlQValueFunctionを参照してください。
critic = rlQValueFunction(criticNet,obsInfo,actInfo, ... ObservationInputNames="netOin",ActionInputNames="netAin");
10 個のランダムな観測値とアクションから成るバッチを使用して、クリティックをチェックします。
robs = rand([obsInfo.Dimension 10]);
ract = rand([actInfo.Dimension 10]);
v = getValue(critic,{robs},{ract});バッチの 6 番目の要素を表示します。
v(6)
ans = single
-0.0078
DDPG エージェントは、方策を近似するために連続決定論的アクターを使用します。クリティックは再帰型ネットワークをもつため、アクターにも再帰型ネットワークを使用しなければなりません。
ネットワークを layer オブジェクトの配列として定義します。
actorNet = [
sequenceInputLayer(prod(obsInfo.Dimension))
lstmLayer(10)
reluLayer
fullyConnectedLayer(prod(actInfo.Dimension))
];dlnetwork オブジェクトに変換し、ネットワークを初期化し、重みの数を表示します。
actorNet = dlnetwork(actorNet); actorNet = initialize(actorNet); summary(actorNet)
Initialized: true
Number of learnables: 531
Inputs:
1 'sequenceinput' Sequence input with 2 channels
actorNet および観測仕様とアクション仕様を使用して、アクターを作成します。連続決定論的アクターの詳細については、rlContinuousDeterministicActorを参照してください。
actor = rlContinuousDeterministicActor(actorNet,obsInfo,actInfo);
10 個のランダムな観測値入力から成るバッチを使用して、アクターをチェックします。
robs = rand([obsInfo.Dimension 10]);
a = getAction(actor,{robs});
a{1}(7)ans = single
-0.1019
クリティックの学習オプションをいくつか指定します。
criticOpts = rlOptimizerOptions( ...
LearnRate=5e-3,GradientThreshold=1);アクターの学習オプションをいくつか指定します。
actorOpts = rlOptimizerOptions( ...
LearnRate=1e-4,GradientThreshold=1);エージェント オプションを指定します。DDPG エージェントを再帰型ニューラル ネットワークで使用するには、1 より大きい SequenceLength を指定しなければなりません。
agentOpts = rlDDPGAgentOptions( ... SampleTime=env.Ts, ... TargetSmoothFactor=1e-3, ... ExperienceBufferLength=1e6, ... DiscountFactor=0.99, ... SequenceLength=20, ... MiniBatchSize=32, ... CriticOptimizerOptions=criticOpts, ... ActorOptimizerOptions=actorOpts);
アクターとクリティックを使用して DDPG エージェントを作成します。
agent = rlDDPGAgent(actor,critic,agentOpts)
agent =
rlDDPGAgent with properties:
ExperienceBuffer: [1×1 rl.replay.rlReplayMemory]
AgentOptions: [1×1 rl.option.rlDDPGAgentOptions]
UseExplorationPolicy: 0
ObservationInfo: [1×1 rl.util.rlNumericSpec]
ActionInfo: [1×1 rl.util.rlNumericSpec]
SampleTime: 0.1000
UseGPUForLearning: 0
エージェントをチェックするには、ランダムな観測値からアクションを返します。
getAction(agent,{rand(obsInfo.Dimension)})ans = 1×1 cell array
{[-0.0848]}
連続する観測値を使用してエージェントを評価するには、シーケンス長 (時間) 次元を使用します。たとえば、9 つの観測値のシーケンスに対するアクションを取得します。
robs = rand([obsInfo.Dimension 1 9]);
[action,state] = getAction(agent,{robs});観測値の 7 番目の要素に対応するアクションを表示します。
action = action{1};
action(1,1,1,7)ans = -0.2942
これで、環境内でエージェントのテストと学習ができるようになりました。
バージョン履歴
R2019a で導入