getActor
強化学習エージェントからのアクターの抽出
説明
例
既存の学習済み強化学習エージェントがあると仮定します。この例では、Compare DDPG Agent to LQR Controllerの学習済みエージェントを読み込みます。
load("DoubleIntegDDPG.mat","agent")
エージェントからアクター関数近似器を取得します。
actor = getActor(agent);
近似器オブジェクトでは、ドット表記を使用して Learnables プロパティにアクセスできます。
まず、パラメーターを表示します。
actor.Learnables{1}ans = 1×2 single dlarray -15.4663 -7.2746
パラメーター値を変更します。この例では、すべてのパラメーターを単純に 2 で割ります。
actor.Learnables{1} = actor.Learnables{1}/2;新しいパラメーターを表示します。
actor.Learnables{1}ans = 1×2 single dlarray -7.7331 -3.6373
あるいは、getLearnableParameters と setLearnableParameters を使用することもできます。
学習可能なパラメーターをアクターから取得します。
params = getLearnableParameters(actor)
params=2×1 cell array
{[-7.7331 -3.6373]}
{[ 0]}
パラメーター値を変更します。この例では、すべてのパラメーターを単純に 2 倍します。
modifiedParams = cellfun(@(x) x*2,params,"UniformOutput",false);アクターのパラメーター値を新しく変更した値に設定します。
actor = setLearnableParameters(actor,modifiedParams);
エージェント内のアクターを新しく変更したアクターに設定します。
setActor(agent,actor);
新しいパラメーター値を表示します。
getLearnableParameters(getActor(agent))
ans=2×1 cell array
{[-15.4663 -7.2746]}
{[ 0]}
連続行動空間をもつ環境を作成し、その観測仕様とアクション仕様を取得します。この例では、Compare DDPG Agent to LQR Controllerの例で使用されている環境を読み込みます。
事前定義された環境を読み込みます。
env = rlPredefinedEnv("DoubleIntegrator-Continuous");観測仕様とアクション仕様を取得します。
obsInfo = getObservationInfo(env); actInfo = getActionInfo(env);
環境の観測仕様とアクション仕様から PPO エージェントを作成します。このエージェントは、アクターとクリティックに既定の深層ニューラル ネットワークを使用します。
agent = rlPPOAgent(obsInfo,actInfo);
強化学習エージェント内の深層ニューラル ネットワークを変更するには、まずアクター関数近似器とクリティック関数近似器を抽出しなければなりません。
actor = getActor(agent); critic = getCritic(agent);
アクター関数近似器とクリティック関数近似器の両方から深層ニューラル ネットワークを抽出します。
actorNet = getModel(actor); criticNet = getModel(critic);
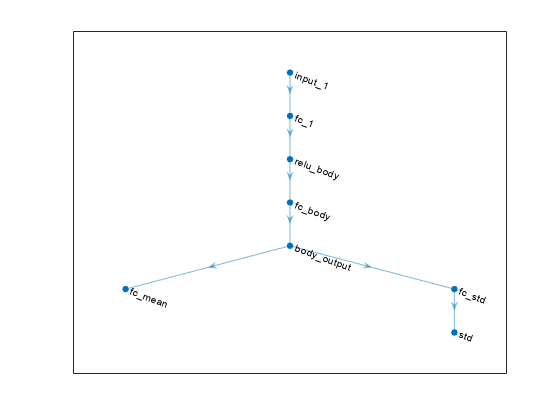
アクター ネットワークをプロットします。
plot(actorNet)
ネットワークを検証するには、analyzeNetwork を使用します。たとえば、クリティック ネットワークを検証します。
analyzeNetwork(criticNet)
アクターおよびクリティックのネットワークを変更し、エージェントに保存し直すことができます。ネットワークを変更するには、ディープ ネットワーク デザイナーアプリを使用できます。各ネットワーク用にアプリを開くには、次のコマンドを使用します。
deepNetworkDesigner(criticNet) deepNetworkDesigner(actorNet)
ディープ ネットワーク デザイナーでネットワークを変更します。たとえば、ネットワークに他の層を追加できます。ネットワークを変更するときに、getModel によって返されるネットワークの入力層と出力層を変更しないでください。ネットワークの構築の詳細については、ディープ ネットワーク デザイナーを使用したネットワークの構築を参照してください。
変更したネットワークをディープ ネットワーク デザイナーで検証するには、[解析] セクションの [解析] をクリックしなければなりません。変更したネットワーク構造を MATLAB® ワークスペースにエクスポートするには、新しいネットワークを作成するコードを生成し、コマンド ラインからそのコードを実行します。ディープ ネットワーク デザイナーのエクスポート オプションは使用しないでください。コードを生成して実行する方法を示す例については、ディープ ネットワーク デザイナーを使用した DQN エージェントの作成およびイメージ観測値を使用した学習を参照してください。
この例では、変更したアクター ネットワークとクリティック ネットワークを作成するコードが createModifiedNetworks 補助スクリプトに含まれています。
createModifiedNetworks
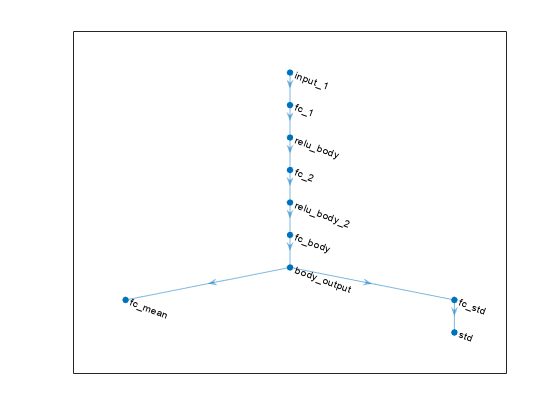
変更した各ネットワークには、メインの共通パスに追加の fullyConnectedLayer と reluLayer が含まれます。変更したアクター ネットワークをプロットします。
plot(modifiedActorNet)
ネットワークをエクスポートした後、ネットワークをアクター関数近似器とクリティック関数近似器に挿入します。
actor = setModel(actor,modifiedActorNet); critic = setModel(critic,modifiedCriticNet);
最後に、変更したアクター関数近似器とクリティック関数近似器をアクター オブジェクトとクリティック オブジェクトに挿入します。
agent = setActor(agent,actor); agent = setCritic(agent,critic);
入力引数
出力引数
バージョン履歴
R2019a で導入