ディープ ネットワーク デザイナーを使用した DQN エージェントの作成およびイメージ観測値を使用した学習
この例では、MATLAB® でモデル化された振子の振り上げと平衡化を行うことができる深層 Q 学習ネットワーク (DQN) エージェントを作成する方法を説明します。この例では、ディープ ネットワーク デザイナーを使用して DQN エージェントを作成します。DQN エージェントの詳細については、深層 Q ネットワーク (DQN) エージェントを参照してください。
イメージ MATLAB 環境を使用した振子の振り上げ
この例では、初期状態で下向きにぶら下がっている摩擦がない単純な振子を、強化学習の環境として使用します。学習の目標は、最小限の制御操作を使用して振子を直立させることです。

この環境では、次のようにします。
振子が倒立平衡状態となっている位置を 0 ラジアン、鉛直下向きとなっている位置を
piラジアンとする。エージェントから環境へのトルク アクション信号は、–2 ~ 2 N·m (反時計回りが正) の範囲にある 5 つの整数のいずれかの値を取れるものとする。
環境からの観測値は、簡略化された振子のグレースケール イメージおよび振子の角度の微分とする。
各タイム ステップで与えられる報酬 は次のとおりとする。
ここで、以下となります。
は直立位置からの変位角 (反時計回りが正)。
は変位角の微分。
は前のタイム ステップからの制御量。
このモデルの連続行動空間版の詳細については、振子の振り上げと平衡化のための、イメージ観測を使用した DDPG エージェントの学習を参照してください。
環境オブジェクトの作成
振子の事前定義済み環境オブジェクトを作成します。
env = rlPredefinedEnv("SimplePendulumWithImage-Discrete");このインターフェイスは 2 つの観測値をもちます。1 つ目の観測値は、"pendImage" という名前で、50 x 50 のグレースケール イメージです。
obsInfo = getObservationInfo(env); obsInfo(1)
ans =
rlNumericSpec with properties:
LowerLimit: 0
UpperLimit: 1
Name: "pendImage"
Description: [0×0 string]
Dimension: [50 50]
DataType: "double"
2 つ目の観測値は、"angularRate" という名前で、振子の角速度です。
obsInfo(2)
ans =
rlNumericSpec with properties:
LowerLimit: -Inf
UpperLimit: Inf
Name: "angularRate"
Description: [0×0 string]
Dimension: [1 1]
DataType: "double"
このインターフェイスは、エージェントが 5 つの可能なトルク値 (-2、-1、0、1、または 2 N·m) のいずれかを振子に適用できる、離散行動空間をもちます。
actInfo = getActionInfo(env)
actInfo =
rlFiniteSetSpec with properties:
Elements: [-2 -1 0 1 2]
Name: "torque"
Description: [0×0 string]
Dimension: [1 1]
DataType: "double"
再現性をもたせるために、乱数発生器のシードを固定します。
rng(0)
ディープ ネットワーク デザイナーを使用したクリティック ネットワークの構築
DQN エージェントは、パラメーター化された Q 値関数近似器を使用して方策の価値を推定します。DQN エージェントは離散行動空間をもつため、(多出力の) ベクトル Q 値関数クリティックを使用できます。これは通常、単出力クリティックよりも効率的です。ただし、この例では、標準の単出力 Q 値関数クリティックを使用します。
パラメーター化された Q 値関数をクリティック内でモデル化するには、3 つの入力層 (そのうち 2 つは obsInfo で指定された観測チャネル用で、もう 1 つは actInfo で指定されたアクション チャネル用) と 1 つの出力層 (これはスカラー値を返します) をもつニューラル ネットワークを使用します。深層ニューラル ネットワークに基づく Q 値関数近似器の作成の詳細については、Create Actors, Critics, and Policy Objectsを参照してください。
ディープ ネットワーク デザイナーアプリを使用して、クリティック ネットワークを対話的に構築します。これを行うには、まず、観測値とアクションごとに個別の入力パスを作成します。これらのパスは、各入力から下位レベルの特徴を学習します。その後、入力パスからの出力を結合する共通の出力パスを作成します。
イメージ観測パスの作成
イメージ観測パスを作成するには、まず、imageInputLayer を [層のライブラリ] ペインからキャンバスにドラッグします。層の [InputSize] をイメージ観測用に 50,50,1 と設定し、[Normalization] を none に設定します。
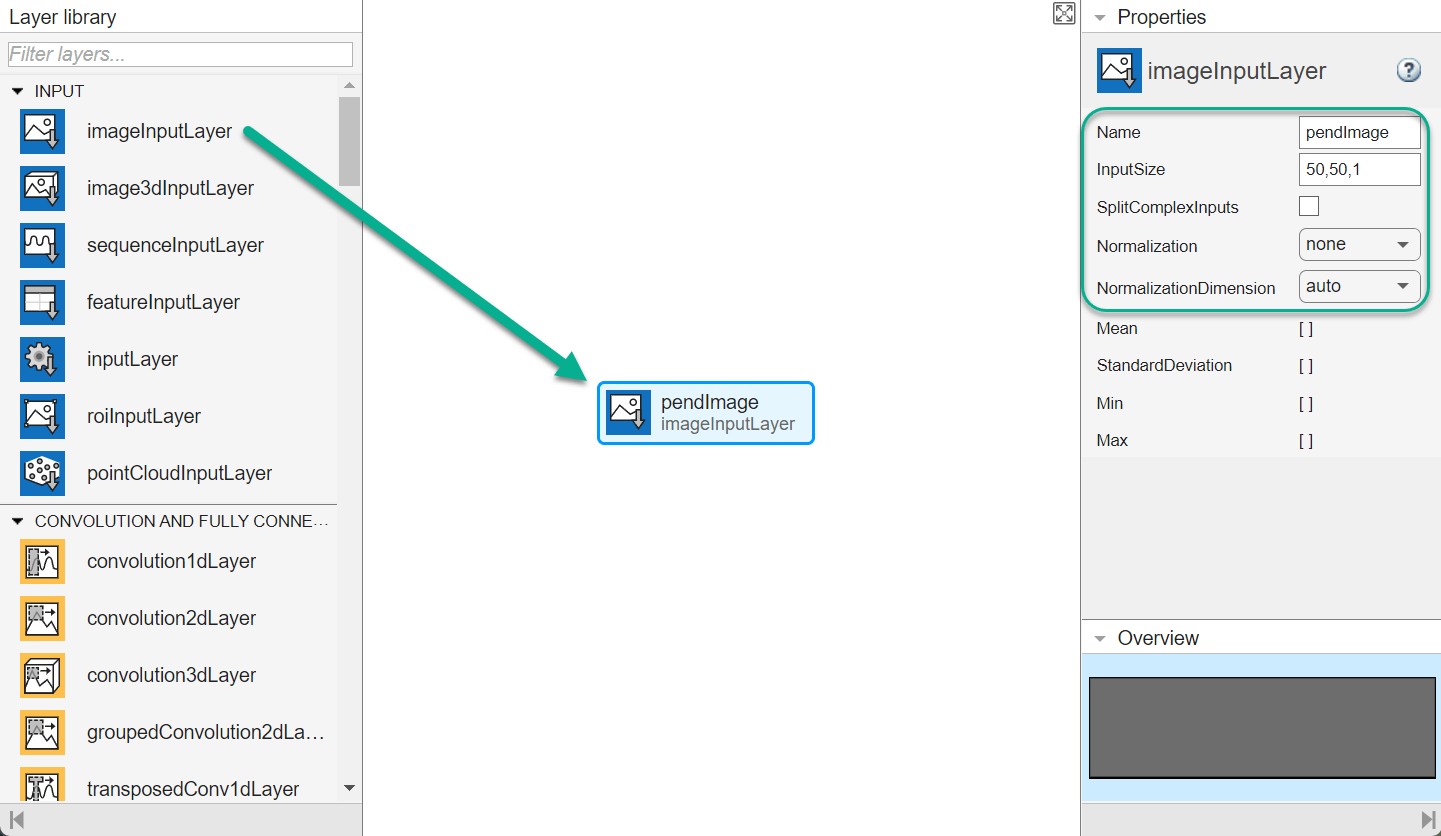
次に、convolution2DLayer をキャンバスにドラッグし、この層の入力を imageInputLayer の出力に接続します。2 個のフィルターをもち (NumFilters プロパティ)、高さと幅が 10 である (FilterSize プロパティ) 畳み込み層を作成します。また、水平方向と垂直方向のストライドを 5 とします (Stride プロパティ)。

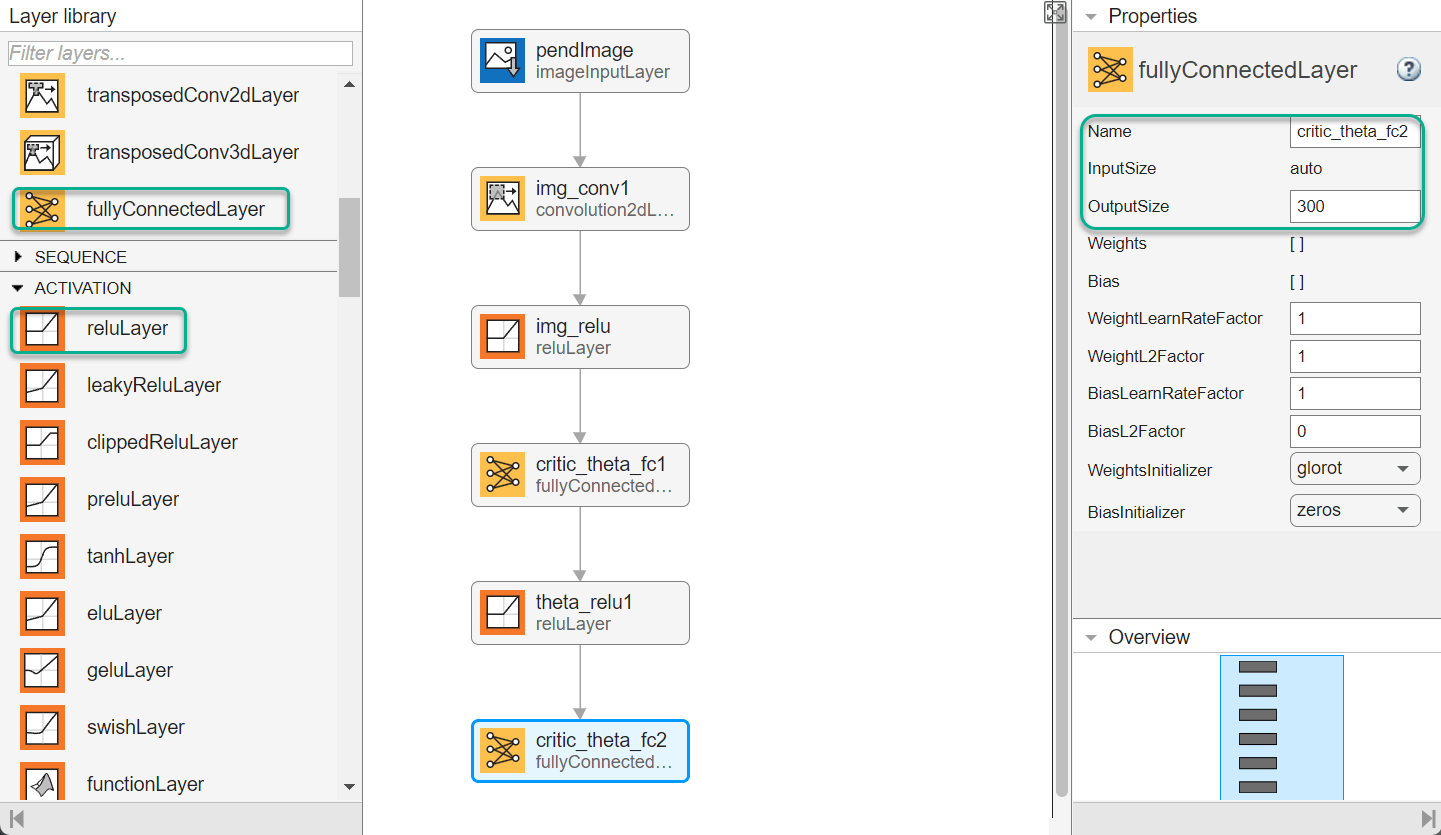
最後に、reLULayer 層と fullyConnectedLayer 層の組を 2 つ使用して、イメージ パスのネットワークを完成させます。1 番目と 2 番目の fullyConnectedLayer 層の出力サイズは、それぞれ 400 と 300 です。
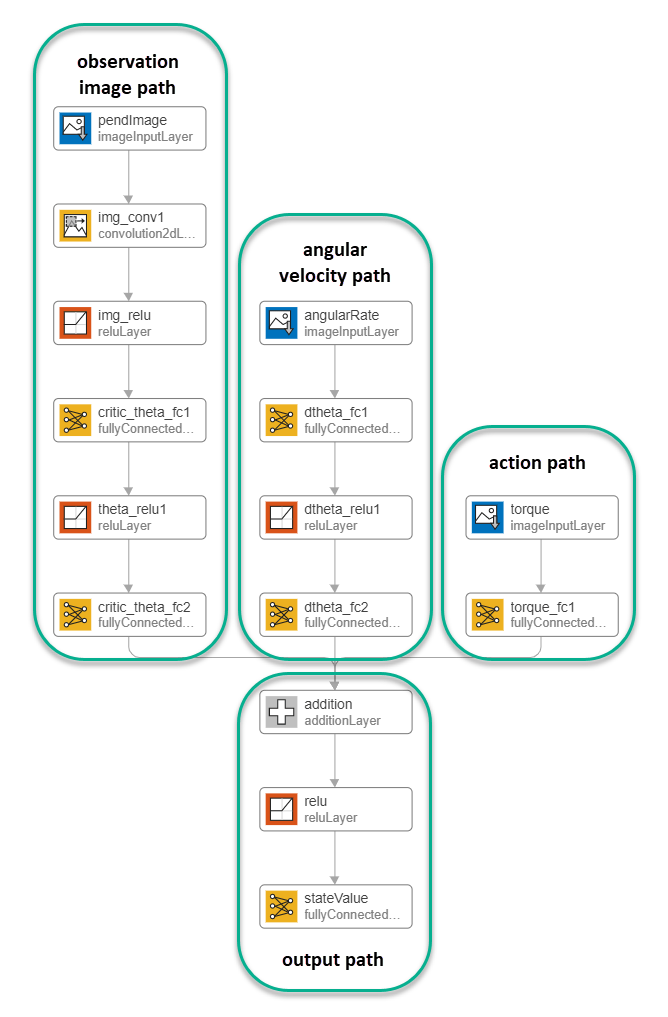
すべての入力パスと出力パスの作成
同様の方法で、その他の入力パスと出力パスを作成します。この例では、次のオプションを使用します。
角速度パス (スカラー入力):
imageInputLayer— InputSize を1,1に設定し、Normalization をnoneに設定。fullyConnectedLayer— OutputSize を400に設定。reLULayerfullyConnectedLayer— OutputSize を300に設定。
アクション パス (スカラー入力):
imageInputLayer— InputSize を1,1に設定し、Normalization をnoneに設定。fullyConnectedLayer— OutputSize を300に設定。
出力パス:
additionLayer— すべての入力パスの出力をこの層の入力に接続。reLULayerfullyConnectedLayer— OutputSize を1に設定 (スカラーの価値関数用)。
ディープ ネットワーク デザイナーからのネットワークのエクスポート
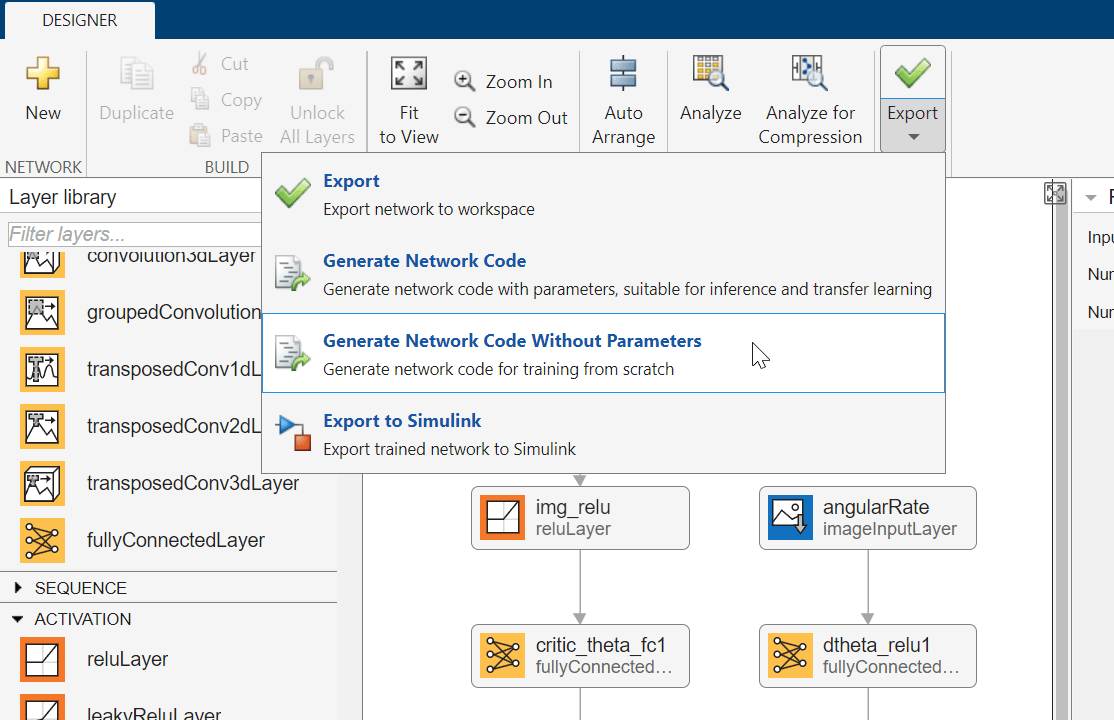
ネットワークを MATLAB ワークスペースにエクスポートするには、ディープ ネットワーク デザイナーで [エクスポート] をクリックします。ディープ ネットワーク デザイナーは、ネットワーク層を格納する新しい変数としてネットワークをエクスポートします。このネットワーク層変数を使用して、クリティック表現を作成できます。
または、このネットワークと同等の MATLAB コードを生成するために、[エクスポート]、[パラメーターなしでネットワーク コードを生成] をクリックします。
生成されるコードは次のとおりです。
net = dlnetwork();
tempLayers = [
imageInputLayer([1 1 1],"Name","angularRate","Normalization","none")
fullyConnectedLayer(400,"Name","dtheta_fc1")
reluLayer("Name","dtheta_relu1")
fullyConnectedLayer(300,"Name","dtheta_fc2")];
net = addLayers(net,tempLayers);
tempLayers = [
imageInputLayer([1 1 1],"Name","torque","Normalization","none")
fullyConnectedLayer(300,"Name","torque_fc1")];
net = addLayers(net,tempLayers);
tempLayers = [
imageInputLayer([50 50 1],"Name","pendImage","Normalization","none")
convolution2dLayer([10 10],2,"Name","img_conv1","Padding","same","Stride",[5 5])
reluLayer("Name","relu_1")
fullyConnectedLayer(400,"Name","critic_theta_fc1")
reluLayer("Name","theta_relu1")
fullyConnectedLayer(300,"Name","critic_theta_fc2")];
net = addLayers(net,tempLayers);
tempLayers = [
additionLayer(3,"Name","addition")
reluLayer("Name","relu_2")
fullyConnectedLayer(1,"Name","stateValue")];
net = addLayers(net,tempLayers);
net = connectLayers(net,"torque_fc1","addition/in3");
net = connectLayers(net,"critic_theta_fc2","addition/in1");
net = connectLayers(net,"dtheta_fc2","addition/in2");クリティック ネットワークの構成を表示します。
figure plot(net)
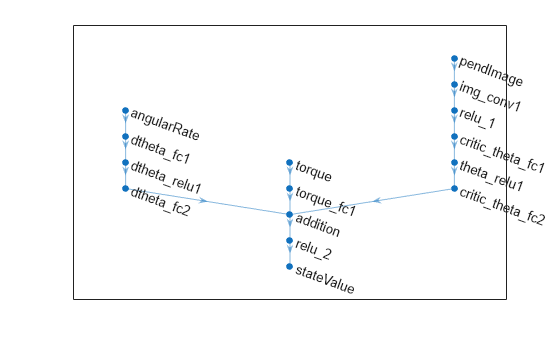
dlnetwork オブジェクトを初期化し、パラメーターの数を表示します。
net = initialize(net); summary(net)
Initialized: true
Number of learnables: 322.9k
Inputs:
1 'angularRate' 1×1×1 images
2 'torque' 1×1×1 images
3 'pendImage' 50×50×1 images
ニューラル ネットワーク、アクション、および観測仕様を使用してクリティックを作成し、観測値とアクションのチャネルに接続する入力層に名前を付けます。詳細については、rlQValueFunctionを参照してください。
critic = rlQValueFunction(net,obsInfo,actInfo, ... "ObservationInputNames",["pendImage","angularRate"], ... "ActionInputNames","torque");
rlOptimizerOptions を使用して、クリティックのオプションを指定します。
criticOpts = rlOptimizerOptions(LearnRate=1e-03,GradientThreshold=1);
rlDQNAgentOptionsを使用して DQN エージェントのオプションを指定します。アクターとクリティックの学習オプションを含めます。
agentOpts = rlDQNAgentOptions( ... UseDoubleDQN=false, ... CriticOptimizerOptions=criticOpts, ... ExperienceBufferLength=1e6, ... SampleTime=env.Ts);
ドット表記を使用してエージェントのオプションを設定または変更することもできます。
agentOpts.EpsilonGreedyExploration.EpsilonDecay = 1e-5;
または、最初にエージェントを作成してから、ドット表記を使用してそのオプションを変更することもできます。
クリティックとエージェントのオプションのオブジェクトを使用して、DQN エージェントを作成します。詳細については、rlDQNAgentを参照してください。
agent = rlDQNAgent(critic,agentOpts);
DQN エージェントの学習
エージェントに学習させるには、まず、学習オプションを指定します。この例では、次のオプションを使用します。
最大 5000 個のエピソードについて、各学習を実行 (各エピソードの持続時間は最大 500 タイム ステップ)。
Episode Manager のダイアログ ボックスに学習の進行状況を表示 (
Plotsオプションを設定) し、コマンド ラインの表示を無効化 (Verboseオプションをfalseに設定)。既定のウィンドウ長 (連続する 5 個のエピソード) について、-1000 を超える平均累積報酬をエージェントが受け取ったときに学習を停止。この時点で、エージェントは最小限の制御操作を使用して、振子を直立位置で素早く平衡化できるようになります。
学習オプションの詳細については、rlTrainingOptionsを参照してください。
trainOpts = rlTrainingOptions( ... MaxEpisodes=5000, ... MaxStepsPerEpisode=500, ... Verbose=false, ... Plots="training-progress", ... StopTrainingCriteria="AverageReward", ... StopTrainingValue=-1000);
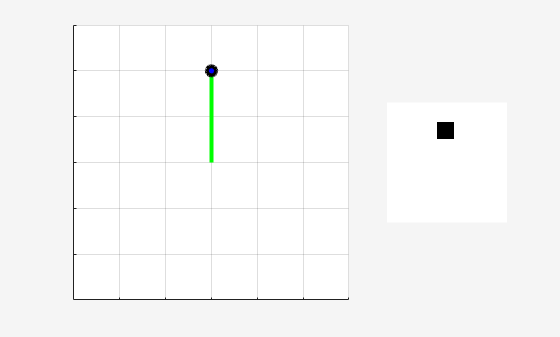
学習中またはシミュレーション中に、関数 plot を使用して振子系を可視化します。
plot(env)
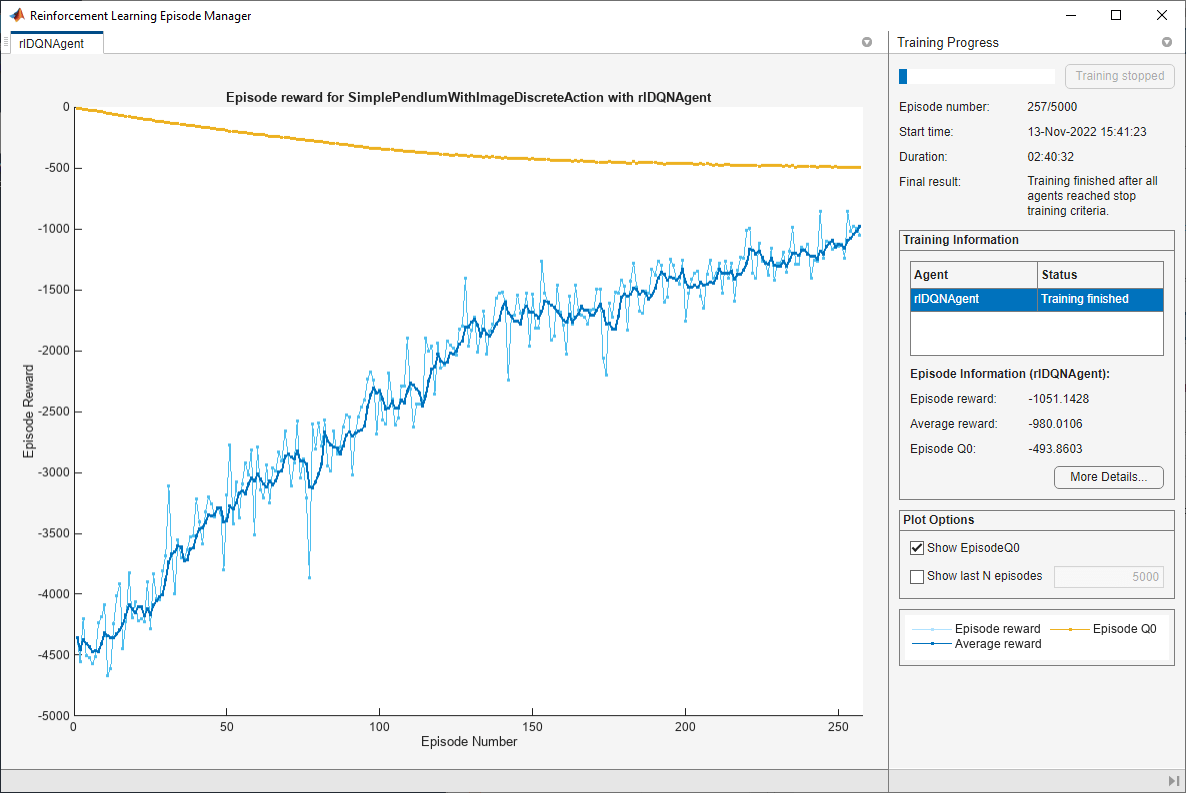
関数 train を使用して、エージェントに学習させます。これは計算量が多いプロセスのため、完了するのに数時間かかります。この例の実行時間を節約するために、doTraining を false に設定して事前学習済みのエージェントを読み込みます。エージェントに学習させるには、doTraining を true に設定します。
doTraining = false; if doTraining % Train the agent. trainingStats = train(agent,env,trainOpts); else % Load pretrained agent for the example. load("MATLABPendImageDQN.mat","agent"); end
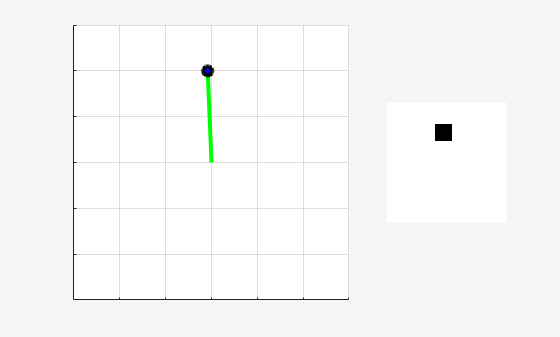
学習済みエージェントのシミュレーション
学習済みエージェントの性能を検証するには、振子環境内でこれをシミュレートします。エージェントのシミュレーションの詳細については、rlSimulationOptions および sim を参照してください。
simOptions = rlSimulationOptions(MaxSteps=500); experience = sim(env,agent,simOptions);
totalReward = sum(experience.Reward)
totalReward = -713.0336
参考
アプリ
関数
オブジェクト
トピック
- 強化学習デザイナーを使用したエージェントの設計と学習
- 離散振子の振り上げと平衡化のための既定の DQN エージェントの学習
- 振子の振り上げと平衡化のための、イメージ観測を使用した DDPG エージェントの学習
- Transfer Learning: Fine-Tune DQN Agent for Pendulum Swing-Up from Earth to Mars
- Use Predefined Control System Environments
- 深層 Q ネットワーク (DQN) エージェント
- Create Actors, Critics, and Policy Objects
- Train Reinforcement Learning Agents