rlHybridStochasticActor
Hybrid stochastic actor with a hybrid action space for reinforcement learning agents
Since R2024b
Description
This object implements a function approximator to be used as a stochastic actor
within a reinforcement learning agent with a hybrid action space (partly discrete and partly
continuous). A hybrid stochastic actor takes an environment observation as input and returns
as output a random action containing a discrete and a continuous part. The discrete part is
sampled from a categorical (also known as Multinoulli) probability distribution, and the
continuous part is sampled from a parameterized Gaussian probability distribution. After you
create an rlHybridStochasticActor object, use it to create an rlSACAgent agent with a
hybrid action space. For more information on creating actors and critics, see Create Actors, Critics, and Policy Objects.
Creation
Syntax
Description
actor = rlHybridStochasticActor(net,observationInfo,actionInfo,DiscreteActionOutputNames=dsctOutLyrName,ContinuousActionMeanOutputNames=meanOutLyrName,ContinuousActionStandardDeviationOutputNames=stdOutLyrName)net as approximation model. Here, net must
have three differently named output layers. One layer must return the probability of each
possible discrete action, and the other two layers must return the mean and the standard
deviation of the Gaussian distribution of each component of the continuous action,
respectively. The actor uses the output of these three layers, according to the names
specified in the strings dsctOutLyrName,
meanOutLyrName and stdOutLyrName, to represent
the probability distributions from which the discrete and continuous components of the
action are sampled. This syntax sets the ObservationInfo and
ActionInfo properties of actor to the input
arguments observationInfo and actionInfo, respectively.
Note
actor does not enforce constraints set by the continuous
action specification. When using this actor in a different agent than SAC, you must
enforce action space constraints within the environment.
actor = rlHybridStochasticActor(___,Name=Value)UseDevice property using one or more name-value arguments. Use
this syntax with any of the input argument combinations in the preceding syntax. Specify
the input layer names to explicitly associate the layers of your network with specific
environment channels. To specify the device where computations for
actor are executed, set the UseDevice property, for example
UseDevice="gpu".
Input Arguments
Name-Value Arguments
Properties
Object Functions
rlSACAgent | Soft actor-critic (SAC) reinforcement learning agent |
getAction | Obtain action from agent, actor, or policy object given environment observations |
evaluate | Evaluate function approximator object given observation (or observation-action) input data |
gradient | (Not recommended) Evaluate gradient of function approximator object given observation and action input data |
accelerate | (Not recommended) Option to accelerate computation of gradient for approximator object based on neural network |
getLearnableParameters | Obtain learnable parameter values from agent, function approximator, or policy object |
setLearnableParameters | Set learnable parameter values of agent, function approximator, or policy object |
setModel | Set approximation model in function approximator object |
getModel | Get approximation model from function approximator object |
Examples
Create an observation specification object (or alternatively use the getObservationInfo function to extract the specification object from an environment). For this example, define the observation space as a continuous five-dimensional space, so that there is a single observation channel that carries a column vector containing five doubles.
obsInfo = rlNumericSpec([5 1]);
Create a hybrid action specification object (or alternatively use the getActionInfo function to extract the specification object from an environment with a hybrid action space). For this example, define a discrete action channel that carries a single scalar that can be -1, 0, or 1, and define a continuous action channel that carries a column vector containing three doubles, each between -10 and 10.
actInfo = [
rlFiniteSetSpec([-1,0,1])
rlNumericSpec([3 1], ...
LowerLimit=-10, ...
UpperLimit=10)
];A hybrid stochastic actor implements a parameterized stochastic policy for a hybrid action space. This actor takes an observation as input and returns as output a hybrid action consisting of a discrete and a continuous part. The discrete part of the action is sampled from a categorical probability distribution, while the continuous part of the action is sampled from a Gaussian probability distribution.
To approximate the mean values and standard deviations of the stochastic distribution, you must use a neural network with three output layers. One of these three layers must return a vector containing the probability of each possible discrete action, another layer must return a vector containing the mean values for each dimension of the continuous action space, and the third layer must return a vector containing the standard deviations for each dimension of the continuous action space.
Therefore, the discrete action probability layer must have the same number of outputs as the number of possible discrete actions, as specified in the first component actInfo. The continuous action mean and standard deviation layers must each have the same number of outputs as the number of dimensions of the continuous action channel, as specified in the second component of actInfo.
Note that standard deviations must be nonnegative, and mean values must fall within the range of the action. Therefore, the output layer that returns the standard deviations must be a softplus or ReLU layer, to enforce nonnegativity, while the output layer that returns the mean values must be a scaling layer immediately preceded by a tahnLayer, to scale the mean values to the output range. However, if you are going to use the actor within a SAC agent, do not add a tanhLayer and a scalingLayer as the last two nonlinear layers in the mean output path. For more information, see Soft Actor-Critic (SAC) Agent.
For this example the environment has only one observation channel, and therefore the network has only one input layer. Note that prod(obsInfo.Dimension) and prod(actInfo.Dimension) return the number of dimensions of the observation and action spaces, respectively, regardless of whether they are arranged as row vectors, column vectors, or matrices.
Define each network path as an array of layer objects and assign names to the input and output layers of each path. These names allow you to connect the paths and then to explicitly associate the network input and output layers with the appropriate environment channel.
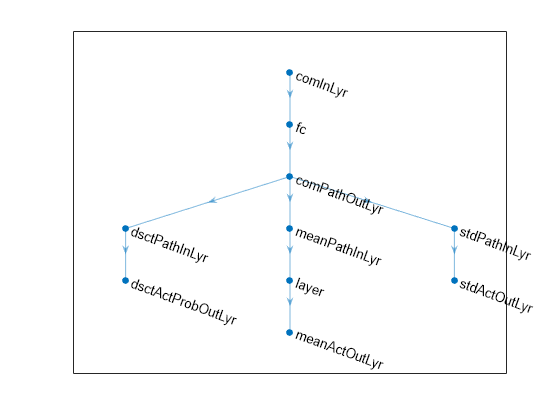
% Common input path layers comPath = [ featureInputLayer( ... prod(obsInfo.Dimension), ... Name="comInLyr"); fullyConnectedLayer( ... prod(actInfo(1).Dimension)+prod(actInfo(2).Dimension)); reluLayer(Name="comPathOutLyr") ]; % Path layers for discrete probabilities dsctPath = [ fullyConnectedLayer( ... numel(actInfo(1).Elements), ... Name="dsctPathInLyr"); softmaxLayer('Name','dsctActProbOutLyr') ]; % Path layers for mean value % Using scalingLayer to scale range from (-1,1) to (-10,10) meanPath = [ fullyConnectedLayer( ... prod(actInfo(2).Dimension), ... Name="meanPathInLyr"); % DO NOT USE following lines if actor is used for a SAC agent tanhLayer; scalingLayer(Name="meanActOutLyr",Scale=actInfo(2).UpperLimit) ]; % Path layers for standard deviations % Using softplus layer to make them nonnegative sdevPath = [ fullyConnectedLayer( ... prod(actInfo(2).Dimension), ... Name="stdPathInLyr"); softplusLayer(Name="stdActOutLyr") ];
Assemble the dlnetwork object.
net = dlnetwork(); net = addLayers(net,comPath); net = addLayers(net,dsctPath); net = addLayers(net,meanPath); net = addLayers(net,sdevPath);
Connect the layers.
net = connectLayers(net,"comPathOutLyr","dsctPathInLyr/in"); net = connectLayers(net,"comPathOutLyr","meanPathInLyr/in"); net = connectLayers(net,"comPathOutLyr","stdPathInLyr/in");
Plot the network.
plot(net)
Initialize the network and display the number of learnable parameters (weights).
net = initialize(net); summary(net)
Initialized: true
Number of learnables: 69
Inputs:
1 'comInLyr' 5 features
Create the actor with rlHybridStochasticActor, using the network, the observation and action specification objects, and the names of the network input and output layers.
actor = rlHybridStochasticActor(net, obsInfo, actInfo, ... DiscreteActionOutputNames="dsctActProbOutLyr", ... ContinuousActionMeanOutputNames="meanActOutLyr", ... ContinuousActionStandardDeviationOutputNames="stdActOutLyr", ... ObservationInputNames="comInLyr");
To check your actor, use the getAction function to return the discrete and continuous action batches from a batch of 10 random observations, using the current network weights.
robs = rand([obsInfo.Dimension 10]);
act = getAction(actor,{robs});Display the seventh element of the discrete action batch.
act{1}(7)ans = -1
The discrete action is a random sample from the categorical distribution provided by the first output of the neural network, as a function of the current observation.
Display the seventh element of the continuous action batch.
act{2}(:,7)ans = 3×1 single column vector
-4.0232
-5.5108
-6.1783
Each of the three elements of the continuous action vector is a random sample from the stochastic distribution, with mean and standard deviation provided by the first output of the neural network, as a function of the current observation.
To return the stochastic distributions of the action, given an observation, use evaluate.
dist = evaluate(actor,{robs});Display the categorical distribution of the seventh element of the discrete action batch.
dist{1}(:,7)ans = 3×1 single column vector
0.3891
0.1413
0.4695
Display the vector of mean values of the seventh element of the continuous action batch.
dist{2}(:,7)ans = 3×1 single column vector
-4.1822
-5.6662
-6.2020
Display the vector of standard deviations of the seventh element of the continuous action batch.
dist{3}(:,7)ans = 3×1 single column vector
0.3130
0.5510
0.7079
You can now use the actor (along with a critic) to create an agent for the environment described by the given specification objects. The agent that uses a hybrid stochastic actor is rlSACAgent.
For more information on creating approximator objects such as actors and critics, see Create Actors, Critics, and Policy Objects.
Version History
Introduced in R2024b