gpuDevice
GPU デバイスのクエリまたは選択
説明
GPUDevice オブジェクトはコンピューターのグラフィックス処理装置 (GPU) を表します。GPU を使用すると、gpuArray 変数をサポートする MATLAB® コードを実行することや、CUDAKernel オブジェクトを使用して CUDA® カーネルを実行することができます。
GPUDevice オブジェクトを使用して GPU デバイスのプロパティの検査、GPU デバイスのリセット、または GPU の計算が完了するまでの待機ができます。GPUDevice オブジェクトを取得するには、関数 gpuDevice を使用します。関数 gpuDevice を使用して GPU デバイスの選択または選択解除もできます。複数の GPU にアクセスできる場合、関数 gpuDevice を使用して、コードを実行する特定の GPU デバイスを選択します。
GPU 上で関数を実行するために GPUDevice オブジェクトを使用する必要はありません。GPU 対応関数の使用方法の詳細については、GPU での MATLAB 関数の実行を参照してください。
作成
説明
gpuDevice は、現在選択されている GPU デバイスのプロパティを表示します。現在デバイスが選択されていない場合、gpuDevice は、既定のデバイスをクリアせずに選択します。GPU デバイスのプロパティを検査するときに、この構文を使用します。
D = gpuDevice は、現在選択されているデバイスを表す GPUDevice オブジェクトを返します。現在デバイスが選択されていない場合、gpuDevice は既定のデバイスを選択し、そのデバイスを表す GPUDevice オブジェクトをクリアせずに返します。
gpuDevice([]) に空の引数が指定されると (引数がない場合とは異なる)、GPU デバイスの選択を解除し、メモリから gpuArray と CUDAKernel の変数をクリアします。この構文では、現在のデバイスとして選択されている GPU デバイスがなくなります。
入力引数
プロパティ
オブジェクト関数
reset | GPU デバイスをリセットし、そのメモリを消去する |
wait (GPUDevice) | GPU の計算が完了するまで待機 |
次の関数も使用できます。
parallel.gpu.GPUDevice.isAvailable(ind) | インデックス ind によって指定された GPU がサポートされていて選択可能な場合は、logical 1 または true を返します。ind は整数、または整数のベクトルで、既定のインデックスは現在のデバイスです。 |
parallel.gpu.GPUDevice.getDevice(ind) | GPUDevice オブジェクトを選択せずに返します。 |
関数の完全な一覧については、GPUDevice オブジェクトに対して関数 methods を使用してください。
methods('parallel.gpu.GPUDevice')次のコマンドを使用して、任意のオブジェクト関数のヘルプを取得できます。
help parallel.gpu.GPUDevice.functionname
ここで、functionname は関数の名前です。たとえば、isAvailable のヘルプを表示するには、次を入力します。
help parallel.gpu.GPUDevice.isAvailable
例
この例では、gpuDevice を使用して、使用するデバイスの識別と選択を行う方法を説明します。
お使いのコンピューターで利用できる GPU デバイスの数を確認するには、関数gpuDeviceCountを使用します。
gpuDeviceCount("available")ans = 2
デバイスが複数ある場合は、1 番目のデバイスが既定になります。関数gpuDeviceTableでそのプロパティを調べて、使用する目的のデバイスかどうかを判断することができます。
gpuDeviceTable
ans=2×5 table
1 "NVIDIA RTX A5000" "8.6" true true
2 "NVIDIA RTX A5000" "8.6" true false
最初のデバイスが使用する目的のデバイスである場合は、次に進むことができます。GPU 上で計算を実行するには、gpuArray対応関数を使用します。詳細については、GPU での MATLAB 関数の実行を参照してください。
MATLAB® で GPU を使用できることを確認するには、canUseGPU関数を使用します。この関数は、計算に使用できる GPU がある場合は 1 (true) を返し、ない場合は 0 (false) を返します。
canUseGPU
ans = logical
1
canUseGPU が 0 (false) を返す場合などに GPU の設定に関する問題を診断するには、validateGPU関数を使用します。GPU の検証はオプションです。
validateGPU
# Beginning GPU validation # Performing system validation # CUDA-supported platform .................................................PASSED # CUDA-enabled graphics driver exists .....................................PASSED # Version: 570.133.07 # CUDA-enabled graphics driver load .......................................PASSED # CUDA environment variables ..............................................PASSED # CUDA_VISIBLE_DEVICES: "0,1" # CUDA device count .......................................................PASSED # Found 2 devices. # GPU libraries load ......................................................PASSED # # Performing device validation for device index 1 # Device exists ...........................................................PASSED # NVIDIA RTX A5000 # Device supported ........................................................PASSED # Device available ........................................................PASSED # Device is in 'Default' compute mode. # Device selectable .......................................................PASSED # Device memory allocation ................................................PASSED # Device kernel launch ....................................................PASSED # # Finished GPU validation with no failures.
他のデバイスを使用するには、そのデバイスのインデックスを指定してgpuDeviceを呼び出します。
gpuDevice(2)
ans =
CUDADevice with properties:
Name: 'NVIDIA RTX A5000'
Index: 2 (of 2)
ComputeCapability: '8.6'
DriverModel: 'N/A'
TotalMemory: 25294995456 (25.29 GB)
AvailableMemory: 25073221632 (25.07 GB)
DeviceAvailable: true
DeviceSelected: true
Show all properties.
あるいは、利用できる GPU デバイスの数を判別し、デバイスのプロパティのいくつかを検査して、MATLAB® デスクトップから使用するデバイスを選択することもできます。[ホーム] タブの [環境] 領域で、[並列]、[GPU 環境の選択] を選択します。
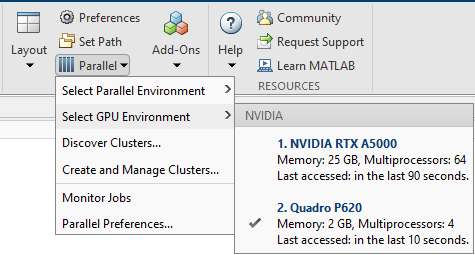
既定の GPU デバイスを表すオブジェクトを作成し、その compute capability をクエリします。
D = gpuDevice; D.ComputeCapability
ans = '8.6'
使用可能なすべての GPU デバイスの計算能力をクエリします。
for idx = 1:gpuDeviceCount D = gpuDevice(idx); disp("Device " + D.Index + " has compute capability " + D.ComputeCapability) end
Device 1 has compute capability 8.6 Device 2 has compute capability 8.6
gpuDeviceTableを使用してシステム内の GPU デバイスの計算能力および可用性を比較します。
gpuDeviceTable
ans=2×5 table
1 "NVIDIA RTX A5000" "8.6" true false
2 "NVIDIA RTX A5000" "8.6" true true
GPU のキャッシュ ポリシーを変更します。
既定の GPU デバイスを表すオブジェクトを作成します。
D = gpuDevice
D =
CUDADevice with properties:
Name: 'NVIDIA RTX A5000'
Index: 1 (of 2)
ComputeCapability: '8.6'
DriverModel: 'TCC'
TotalMemory: 25544294400 (25.54 GB)
AvailableMemory: 25120866304 (25.12 GB)
DeviceAvailable: true
DeviceSelected: true
Show all properties.
GPU デバイスの CachePolicy プロパティにアクセスします。
D.CachePolicy
ans = 'balanced'
キャッシュ ポリシーを変更して、GPU で計算を高速化するためにメモリの最大量をキャッシュできるようにします。
D.CachePolicy = "maximum";
D.CachePolicyans = 'maximum'
プロパティを [] に設定して、キャッシュ ポリシーを既定のポリシーにリセットします。
D.CachePolicy = [];
reset(D) を呼び出すか、gpuDevice で別のデバイスを選択した場合も、キャッシュ ポリシーは既定値にリセットされます。
複数の GPU にアクセスできる場合、並列プールを使用して複数の GPU で並列計算を実行することができます。
MATLAB で使用可能な GPU の数を特定するには、関数gpuDeviceCountを使用します。
availableGPUs = gpuDeviceCount("available")availableGPUs = 3
使用可能な GPU と同数のワーカーをもつ並列プールを起動します。最良のパフォーマンスを得るために、MATLAB は既定でワーカーごとに別々の GPU を割り当てます。
parpool("Processes",availableGPUs);Starting parallel pool (parpool) using the 'Processes' profile ... Connected to the parallel pool (number of workers: 3).
各ワーカーが使用している GPU を識別するために、spmd ブロック内で gpuDevice を呼び出します。spmd ブロックは各ワーカーで gpuDevice を実行します。
spmd gpuDevice end
parforやparfevalなどの並列言語機能を使用して、並列プールのワーカーに計算を分散します。計算にgpuArray対応関数を使用すると、これらの関数はワーカーの GPU で実行されます。詳細については、GPU での MATLAB 関数の実行を参照してください。例は、複数の GPU での MATLAB 関数の実行を参照してください。
計算が完了したら、並列プールをシャットダウンします。関数gcpを使用して、現在の並列プールを取得できます。
delete(gcp("nocreate"));他の GPU を選択して使用する場合は、gpuDevice で GPU デバイス インデックスを使用して、各ワーカーで特定の GPU を選択できます。関数 gpuDeviceCount を使用すると、システム内の各 GPU デバイスのインデックスを取得できます。
システム内に使用可能な GPU が 3 つあり、その中の 2 つだけを計算に使用するとします。デバイスのインデックスを取得します。
[availableGPUs,gpuIndx] = gpuDeviceCount("available")availableGPUs = 3
gpuIndx = 1×3
1 2 3
使用するデバイスのインデックスを定義します。
useGPUs = [1 3];
並列プールを起動します。spmd ブロックと gpuDevice を使用して、各ワーカーと使用する GPU のいずれかをデバイス インデックスにより関連付けます。関数 spmdIndex は各ワーカーのインデックスを識別します。
parpool("Processes",numel(useGPUs));Starting parallel pool (parpool) using the 'Processes' profile ... Connected to the parallel pool (number of workers: 2).
spmd gpuDevice(useGPUs(spmdIndex)); end
ベスト プラクティスとして、また最良のパフォーマンスを得るには、各ワーカーに異なる GPU を割り当てます。
計算が完了したら、並列プールをシャットダウンします。
delete(gcp("nocreate"));ヒント
リモート GPU のプロパティをクエリするには、クラスターを使用して並列プールを起動し、
spmdブロックの中でgpuDeviceを呼び出します。ワーカーに GPU が複数ある場合は、代わりにgpuDeviceTableを使用します。cluster = parcluster("myRemoteGPUCluster"); pool = parpool(cluster); spmd D = gpuDevice end
リモート GPU の使用の詳細については、Work with Remote GPUsを参照してください。