griddedInterpolant
グリッド データの内挿
説明
griddedInterpolant を使用して、1 次元、2 次元、3 次元、N 次元のグリッド データ セットに対して内挿を実行します。griddedInterpolant は指定されたデータ セットの内挿関数 F を返します。F をクエリ点の集合 (2 次元の (xq,yq) など) で評価して、内挿値 vq = F(xq,yq) を生成できます。
散布データを使用して内挿を実行するには、scatteredInterpolant を使用します。
作成
構文
説明
F = griddedInterpolant
F = griddedInterpolant(V)griddedInterpolant は、i 番目の次元で、間隔が 1、範囲が [1, size(V,i)] の点の集合としてグリッドを定義します。この構文は、点の間の絶対距離を考慮せず、メモリを節約する場合に使用します。
F = griddedInterpolant(___,Method)'linear'、'nearest'、'next'、'previous'、'pchip'、'cubic'、'makima' または 'spline' を指定します。前述の任意の構文で、最後の入力引数として Method を指定できます。
F = griddedInterpolant(___,Method,ExtrapolationMethod)griddedInterpolant は、クエリ点がサンプル点の領域外であるときに ExtrapolationMethod を使用して値を推定します。
入力引数
プロパティ
使用法
説明
griddedInterpolant を使用して、内挿 F を作成します。その後、次の構文のいずれかを使用して、特定のクエリ点で F を評価できます。
Vq = F(Xq) は行列 Xq のクエリ点を指定します。Xq の各行は、1 つのクエリ点の座標を含みます。
Vq = F(xq1,xq2,...,xqn) はクエリ点を複数の列ベクトル xq1,xq2,...,xqn として指定します。列ベクトルは長さが m で、n 次元空間に散在する m 個の点を表します。
Vq = F(Xq1,Xq2,...,Xqn) は n 次元配列 Xq1,Xq2,...,Xqn を使用してクエリ点を指定します。この配列は点のフル グリッドを定義します。
Vq = F({xgq1,xgq2,...,xgqn}) はクエリ点をグリッド ベクトルとして指定します。この構文は、クエリする点のグリッドが大きく、メモリを節約する場合に使用してください。
例
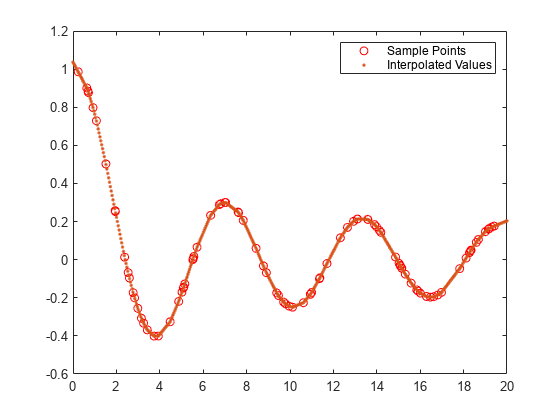
griddedInterpolant を使用して 1 次元データ セットを内挿します。
散在するサンプル点 v のベクトルを作成します。点は 0 ~ 20 のランダムな 1 次元の位置でサンプリングされます。
x = sort(20*rand(100,1)); v = besselj(0,x);
データのグリッド内挿オブジェクトを作成します。既定で、griddedInterpolant は 'linear' 内挿法を使用します。
F = griddedInterpolant(x,v)
F =
griddedInterpolant with properties:
GridVectors: {[100×1 double]}
Values: [100×1 double]
Method: 'linear'
ExtrapolationMethod: 'linear'
0 ~ 20 の等間隔の 500 点で、内挿 F をクエリします。内挿結果 (xq,vq) を元のデータ (x,v) の上にプロットします。
xq = linspace(0,20,500); vq = F(xq); plot(x,v,'ro') hold on plot(xq,vq,'.') legend('Sample Points','Interpolated Values')
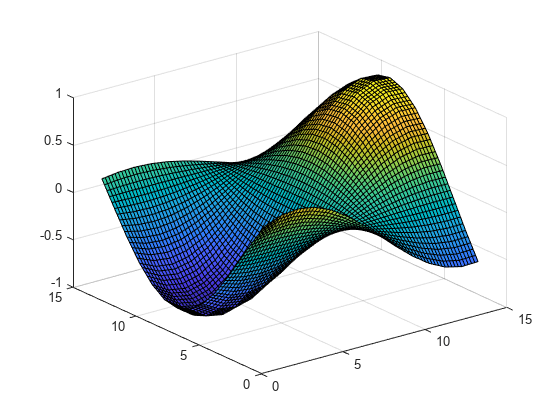
2 つの手法を使用して 3 次元データを内挿し、クエリ点を指定します。
関数 を範囲 [-5,5] のグリッド サンプル点のセットで評価した結果を表す 3 次元データ セットを作成して、プロットします。
[x,y] = ndgrid(-5:0.8:5); z = sin(x.^2 + y.^2) ./ (x.^2 + y.^2); surf(x,y,z)

データのグリッド内挿オブジェクトを作成します。
F = griddedInterpolant(x,y,z);
細かいメッシュを使用して内挿をクエリし、分解能を向上させます。
[xq,yq] = ndgrid(-5:0.1:5); vq = F(xq,yq); surf(xq,yq,vq)

多数のサンプル点またはクエリ点がある場合、およびメモリ使用量が問題になる場合は、"グリッド ベクトル" を使用してメモリ使用量を改善できます。
ndgridを使用する代わりにグリッド ベクトルを指定してフル グリッドを作成した場合、griddedInterpolantはフル クエリ グリッドを形成せずに計算を実行します。グリッド ベクトルを渡した場合、通常これらは cell 配列
{xg1, xg2, ..., xgn}のセルとしてグループ化されます。グリッド ベクトルは、フル グリッドの点をコンパクトに表す方法です。

あるいは、グリッド ベクトルを使用して前述のコマンドを実行します。
x = -5:0.8:5;
y = x';
z = sin(x.^2 + y.^2) ./ (x.^2 + y.^2);
F = griddedInterpolant({x,y},z);
xq = -5:0.1:5;
yq = xq';
vq = F({xq,yq});
surf(xq,yq,vq)
既定のグリッドを使用して、サンプル点のセットに内挿を迅速に実行します。既定のグリッドは単位間隔の点を使用するため、この内挿はサンプル点間の正確な xy 間隔が重要ではない場合に便利です。
サンプルの関数値の行列を作成し、既定のグリッドに対してこれらをプロットします。
x = (1:0.3:5)'; y = x'; V = cos(x) .* sin(y); n = length(x); surf(1:n,1:n,V)

既定のグリッドを使用してデータを内挿します。
F = griddedInterpolant(V)
F =
griddedInterpolant with properties:
GridVectors: {[1 2 3 4 5 6 7 8 9 10 11 12 13 14] [1 2 3 4 5 6 7 8 9 10 11 12 13 14]}
Values: [14×14 double]
Method: 'linear'
ExtrapolationMethod: 'linear'
内挿をクエリして、結果をプロットします。
[xq,yq] = ndgrid(1:0.2:n); Vq = F(xq,yq); surf(xq',yq',Vq)
粗くサンプリングされたデータを、0.5 間隔のフル グリッドを使用して内挿します。
サンプル点を、フル グリッドとして、両方の次元に範囲 [1, 10] で定義します。
[X,Y] = ndgrid(1:10,1:10);
グリッド点で をサンプリングします。
V = X.^2 + Y.^2;
3 次内挿を指定して内挿を作成します。
F = griddedInterpolant(X,Y,V,'cubic');クエリ点のフル グリッドを 0.5 間隔で定義し、それらの点で内挿を評価します。次に、結果をプロットします。
[Xq,Yq] = ndgrid(1:0.5:10,1:0.5:10); Vq = F(Xq,Yq); mesh(Xq,Yq,Vq);

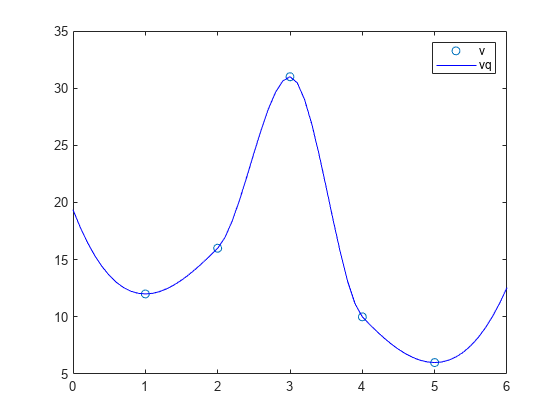
外挿法の 'pchip' と 'nearest' を使用して、F の領域の外側で内挿をクエリした際の結果を比較します。
内挿法に 'pchip' を指定し、外挿法に 'nearest' を指定して、内挿を作成します。
x = [1 2 3 4 5]; v = [12 16 31 10 6]; F = griddedInterpolant(x,v,'pchip','nearest')
F =
griddedInterpolant with properties:
GridVectors: {[1 2 3 4 5]}
Values: [12 16 31 10 6]
Method: 'pchip'
ExtrapolationMethod: 'nearest'
内挿をクエリし、F の領域の外側の点を含めます。
xq = 0:0.1:6; vq = F(xq); figure plot(x,v,'o',xq,vq,'-b'); legend ('v','vq')

同じ点で再び内挿をクエリしますが、今回は 'pchip' 外挿法を使用します。
F.ExtrapolationMethod = 'pchip'; figure vq = F(xq); plot(x,v,'o',xq,vq,'-b'); legend ('v','vq')
griddedInterpolant を使用して、同じクエリ点で 3 つの異なる値セットを内挿します。
および のサンプル点のグリッドを作成します。
gx = -5:5; gy = -3:3; [X,Y] = ndgrid(gx,gy);
サンプル点で 3 つの関数を評価します。その後、各 2 次元ページが 1 つの関数の値に対応する 3 次元配列にサンプル値を連結します。V のページは 3 つになります。これは、各サンプル点のサンプル値の数です。V の各ページのサイズは X および Y のグリッドと同じです。
f1 = X.^2 + Y.^2; f2 = X.^3 + Y.^3; f3 = X.^4 + Y.^4; V = cat(3,f1,f2,f3);
サンプル点とサンプル値を使用して内挿を作成します。
F = griddedInterpolant(X,Y,V);
クエリ点のグリッドをサンプル点と比べてより細かいメッシュ サイズで作成します。
qx = -5:0.4:5; qy = -3:0.4:3; [XQ,YQ] = ndgrid(qx,qy);
各 2 次元ページのクエリ点で内挿を評価します。
VQ = F(XQ,YQ);
元のデータと内挿結果を比較します。
tiledlayout(3,2) nexttile surf(X,Y,f1) title("f1") nexttile surf(XQ,YQ,VQ(:,:,1)) title("Interpolated f1") nexttile surf(X,Y,f2) title("f2") nexttile surf(XQ,YQ,VQ(:,:,2)) title("Interpolated f2") nexttile surf(X,Y,f3) title("f3") nexttile surf(XQ,YQ,VQ(:,:,3)) title("Interpolated f3")

詳細
ヒント
griddedInterpolantオブジェクトFを多数のクエリ点のセットで評価する方が、interp1、interp2、interp3、またはinterpnを使用して内挿を個別に計算するより速く処理できます。以下に例を示します。% Fast to create interpolant F and evaluate multiple times F = griddedInterpolant(X1,X2,V) v1 = F(Xq1) v2 = F(Xq2) % Slower to compute interpolations separately using interp2 v1 = interp2(X1,X2,V,Xq1) v2 = interp2(X1,X2,V,Xq2)
拡張機能
バージョン履歴
R2011b で導入参考
scatteredInterpolant | interp1 | interp2 | interp3 | interpn | ndgrid | meshgrid | fillmissing | filloutliers