scatteredInterpolant
2 次元または 3 次元の散布データの内挿
説明
scatteredInterpolant を使用して、散布データの 2 次元または 3 次元データ セットの内挿を実行します。scatteredInterpolant は指定したデータ セットの内挿 F を返します。F をクエリ点の集合 (2 次元の (xq,yq) など) で評価して、内挿値 vq = F(xq,yq) を生成できます。
griddedInterpolant を使用して、グリッド データによる内挿を実行します。
作成
構文
説明
F = scatteredInterpolant
F = scatteredInterpolant(___,Method)'nearest'、'linear'、または 'natural' を指定します。
F = scatteredInterpolant(___,Method,ExtrapolationMethod)Method と ExtrapolationMethod を最後の 2 つの入力引数として一緒に渡してください。
入力引数
プロパティ
使用法
説明
scatteredInterpolant を使用して、内挿 F を作成します。その後、次の構文のいずれかを使用して、特定の点で F を評価できます。
Vq = F(Pq) は行列 Pq のクエリ点で F を評価します。Pq の各行は、クエリ点の座標を含んでいます。
Vq = F(Xq,Yq) と Vq = F(Xq,Yq,Zq) は、等しいサイズの 2 つまたは 3 つの配列としてクエリ点を指定します。F はクエリ点を列ベクトルとして扱います (たとえば、Xq(:))。
FのValuesプロパティがサンプル点における 1 つの値セットを表す列ベクトルである場合、Vqはクエリ点と同じサイズです。FのValuesプロパティがサンプル点における複数の値セットを表す行列である場合、Vqは行列であり、各列はクエリ点における異なる値セットを表します。
例
サンプル点を定義し、これらの位置での三角関数の値を計算します。これらの点は内挿のサンプル値です。
t = linspace(3/4*pi,2*pi,50)'; x = [3*cos(t); 2*cos(t); 0.7*cos(t)]; y = [3*sin(t); 2*sin(t); 0.7*sin(t)]; v = repelem([-0.5; 1.5; 2],length(t));
内挿を作成します。
F = scatteredInterpolant(x,y,v);
クエリ位置 (xq,yq) で内挿を評価します。
tq = linspace(3/4*pi+0.2,2*pi-0.2,40)'; xq = [2.8*cos(tq); 1.7*cos(tq); cos(tq)]; yq = [2.8*sin(tq); 1.7*sin(tq); sin(tq)]; vq = F(xq,yq);
結果をプロットします。
plot3(x,y,v,'.',xq,yq,vq,'.'), grid on title('Linear Interpolation') xlabel('x'), ylabel('y'), zlabel('Values') legend('Sample data','Interpolated query data','Location','Best')

一連の散布サンプル点の内挿を作成し、その内挿を一連の 3 次元クエリ点で評価します。
200 個の乱数点を定義し、三角関数をサンプリングします。これらの点は内挿のサンプル値です。
rng default;
P = -2.5 + 5*rand([200 3]);
v = sin(P(:,1).^2 + P(:,2).^2 + P(:,3).^2)./(P(:,1).^2+P(:,2).^2+P(:,3).^2);内挿を作成します。
F = scatteredInterpolant(P,v);
クエリ位置 (xq,yq,zq) で内挿を評価します。
[xq,yq,zq] = meshgrid(-2:0.25:2); vq = F(xq,yq,zq);
結果のスライスをプロットします。
xslice = [-.5,1,2]; yslice = [0,2]; zslice = [-2,0]; slice(xq,yq,zq,vq,xslice,yslice,zslice)

サンプル点の値を変更する場合は、Values プロパティの要素を置換します。元の三角形分割は変更されないため、新しい内挿を評価すると即時に結果が得られます。
50 個の乱数点を作成し、指数関数をサンプリングします。これらの点は内挿のサンプル値です。
rng('default')
x = -2.5 + 5*rand([50 1]);
y = -2.5 + 5*rand([50 1]);
v = x.*exp(-x.^2-y.^2);内挿を作成します。
F = scatteredInterpolant(x,y,v)
F =
scatteredInterpolant with properties:
Points: [50×2 double]
Values: [50×1 double]
Method: 'linear'
ExtrapolationMethod: 'linear'
(1.40,1.90) の内挿を評価します。
F(1.40,1.90)
ans = 0.0069
内挿のサンプル値を変更し、同じ点で内挿を再評価します。
vnew = x.^2 + y.^2; F.Values = vnew; F(1.40,1.90)
ans = 5.6491
scatteredInterpolant を呼び出す前に、groupsummary を使用して重複するサンプル点を削除し、それらの結合方法を制御します。
サンプル点の位置からなる 200 行 3 列の行列を作成します。最後の 5 行に重複する点を追加します。
P = -2.5 + 5*rand(200,3); P(197:200,:) = repmat(P(196,:),4,1);
サンプル点における乱数値のベクトルを作成します。
V = rand(size(P,1),1);
重複するサンプル点で scatteredInterpolant を使用しようとすると、警告がスローされ、V の対応する値が平均化されて単一の一意の点が生成されます。ただし、groupsummary を使用すると、内挿を作成する前に重複する点を削除できます。これは、平均化以外の方法を使用して重複する点を結合する場合に特に便利です。
groupsummary を使用して、重複するサンプル点を削除し、重複するサンプル点の位置における V の最大値を保持します。サンプル点の行列をグループ化変数として指定し、対応する値をデータとして指定します。
[V_unique,P_unique] = groupsummary(V,P,@max);
グループ化変数には列が 3 つあるため、groupsummary は一意のグループ P_unique を cell 配列として返します。cell 配列を変換して行列に戻します。
P_unique = [P_unique{:}];内挿を作成します。サンプル点が一意になったため、scatteredInterpolant は警告をスローしません。
I = scatteredInterpolant(P_unique,V_unique);
scatteredInterpolant により提供される複数の内挿アルゴリズムの結果を比較します。
50 個の散布点のサンプル データ セットを作成します。内挿法ごとの差異が鮮明になるように、点の数は人為的に少なく設定されています。
x = -3 + 6*rand(50,1); y = -3 + 6*rand(50,1); v = sin(x).^4 .* cos(y);
内挿とクエリ点のグリッドを作成します。
F = scatteredInterpolant(x,y,v); [xq,yq] = meshgrid(-3:0.1:3);
'nearest'、'linear'、'natural' の各メソッドを使用して結果をプロットします。内挿法が変更されるたびに、内挿を再クエリして最新の結果を取得する必要があります。
F.Method = 'nearest'; vq1 = F(xq,yq); plot3(x,y,v,'mo') hold on mesh(xq,yq,vq1) title('Nearest Neighbor') legend('Sample Points','Interpolated Surface','Location','NorthWest')

F.Method = 'linear'; vq2 = F(xq,yq); figure plot3(x,y,v,'mo') hold on mesh(xq,yq,vq2) title('Linear') legend('Sample Points','Interpolated Surface','Location','NorthWest')

F.Method = 'natural'; vq3 = F(xq,yq); figure plot3(x,y,v,'mo') hold on mesh(xq,yq,vq3) title('Natural Neighbor') legend('Sample Points','Interpolated Surface','Location','NorthWest')

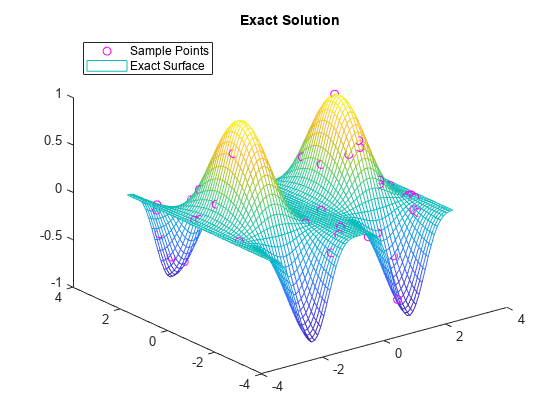
厳密解をプロットします。
figure plot3(x,y,v,'mo') hold on mesh(xq,yq,sin(xq).^4 .* cos(yq)) title('Exact Solution') legend('Sample Points','Exact Surface','Location','NorthWest')
R2024a 以降
scatteredInterpolant により提供される複数の異なる外挿法の結果を比較します。
50 個の散布点のサンプル データ セットを作成し、それらの位置での三角関数の値を計算します。これらの点は内挿のサンプル値です。
rng default
x = -3 + 6*rand(50,1);
y = -3 + 6*rand(50,1);
v = sin(x).^4 .* cos(y);内挿を作成します。
F = scatteredInterpolant(x,y,v)
F =
scatteredInterpolant with properties:
Points: [50×2 double]
Values: [50×1 double]
Method: 'linear'
ExtrapolationMethod: 'linear'
入力データの境界を計算します。
C = convhull(x,y); xc = [x(C); x(C(1))]; yc = [y(C); y(C(1))]; vc = [v(C); v(C(1))];
境界勾配に基づく線形外挿を使用して、クエリ位置 (xq,yq) で内挿を評価します。その後、内挿と外挿の結果をプロットします。
[xq,yq] = meshgrid(-4:0.1:4); vq1 = F(xq,yq); surf(xq,yq,vq1,FaceAlpha=0.5,DisplayName="Interpolation + extrapolation result",EdgeColor=[100 100 100]./256,FaceColor="interp") hold on plot3(x,y,v,"black.",MarkerSize=20,DisplayName="Sample points") plot3(xc,yc,vc,"magenta-",LineWidth=3,DisplayName="Interpolation-extrapolation boundary") title("Linear interpolation + linear extrapolation") legend(Location="NorthEast") zlim([-2.8 1.3]) colorbar colormap jet clim([-2.8 1.3]) view([-183.69 21.20]) hold off

最近傍外挿を使用するように内挿を変更し、内挿を評価して可視化します。
F.ExtrapolationMethod = "nearest"; vq2 = F(xq,yq); surf(xq,yq,vq2,FaceAlpha=0.5,DisplayName="Interpolation + extrapolation result",EdgeColor=[100 100 100]./256,FaceColor="interp") hold on plot3(x,y,v,"black.",MarkerSize=20,DisplayName="Sample points") plot3(xc,yc,vc,"magenta-",LineWidth=3,DisplayName="Interpolation-extrapolation boundary") title("Linear interpolation + Nearest extrapolation") legend(Location="NorthEast") zlim([-2.8 1.3]) colorbar colormap jet clim([-2.8 1.3]) view([-183.69 21.20]) hold off

内挿の境界を外挿の領域に拡張するように内挿を変更し、内挿を評価して可視化します。
F.ExtrapolationMethod = "boundary"; vq3 = F(xq,yq); surf(xq,yq,vq3,FaceAlpha=0.5,DisplayName="Interpolation + extrapolation result",EdgeColor=[100 100 100]./256,FaceColor="interp") hold on plot3(x,y,v,"black.",MarkerSize=20,DisplayName="Sample points") plot3(xc,yc,vc,"magenta-",LineWidth=3,DisplayName="Interpolation-extrapolation boundary") title("Linear interpolation + Boundary extrapolation") legend(Location="NorthEast") zlim([-2.8 1.3]) colorbar colormap jet clim([-2.8 1.3]) view([-183.69 21.20]) hold off

プロットされた結果を調べて外挿法を比較します。境界外挿では内挿と外挿の領域の間で連続性が維持されるのに対し、最近傍外挿では境界に沿って不連続になることがあります。境界外挿では外挿の領域内に極値は現れないのに対し、線形外挿では極値が現れることがあります。
R2023b 以降
同じクエリ点で複数のデータ セットを内挿します。
サンプル点ベクトル x および y で表された 50 個の散布点をもつサンプル データ セットを作成します。
rng("default")
x = -3 + 6*rand(50,1);
y = -3 + 6*rand(50,1);複数のデータ セットを内挿するには、各列がサンプル点における異なる関数の値を表す行列を作成します。
s1 = sin(x).^4 .* cos(y); s2 = sin(x) + cos(y); s3 = x + y; s4 = x.^2 + y; v = [s1 s2 s3 s4];
v の各値セットに対して内挿を実行する位置を示すクエリ点ベクトルを作成します。
xq = -3:0.1:3; yq = -3:0.1:3;
内挿 F を作成します。
F = scatteredInterpolant(x,y,v)
F =
scatteredInterpolant with properties:
Points: [50×2 double]
Values: [50×4 double]
Method: 'linear'
ExtrapolationMethod: 'linear'
クエリ位置で内挿を評価します。Vq の各ページには、v の対応するデータ セットに対して内挿された値が含まれます。
Vq = F({xq,yq});
size(Vq)ans = 1×3
61 61 4
各データ セットの内挿された値をプロットします。
tiledlayout(2,2) nexttile plot3(x,y,v(:,1),'mo') hold on mesh(xq,yq,Vq(:,:,1)') title("sin(x).^4 .* cos(y)") nexttile plot3(x,y,v(:,2),'mo') hold on mesh(xq,yq,Vq(:,:,2)') title("sin(x) + cos(y)") nexttile plot3(x,y,v(:,3),'mo') hold on mesh(xq,yq,Vq(:,:,3)') title("x + y") nexttile plot3(x,y,v(:,4),'mo') hold on mesh(xq,yq,Vq(:,:,4)') title("x.^2 + y") lg = legend("Sample Points","Interpolated Surface"); lg.Layout.Tile = "north";

詳細
ヒント
scatteredInterpolantオブジェクトFを多数のクエリ点の組で評価する方が、関数griddataまたはgriddatanを使用して内挿を個別に計算するより速く処理できます。以下に例を示します。% Fast to create interpolant F and evaluate multiple times F = scatteredInterpolant(X,Y,V) v1 = F(Xq1,Yq1) v2 = F(Xq2,Yq2) % Slower to compute interpolations separately using griddata v1 = griddata(X,Y,V,Xq1,Yq1) v2 = griddata(X,Y,V,Xq2,Yq2)
内挿のサンプル値または内挿法を変更する場合、内挿オブジェクト
Fのプロパティを更新する方が、新しいscatteredInterpolantオブジェクトを作成するよりも効率的です。ValuesまたはMethodを更新する場合、基になる入力データの Delaunay 三角形分割は変更されないため、新しい結果を迅速に計算できます。scatteredInterpolantによる散布データの内挿ではデータの Delaunay 三角形分割を使用するため、内挿はサンプル点x、y、zまたはPのスケーリング問題の影響を受けやすいことがあります。スケーリング問題が起きた場合は、normalizeを使用してデータを再スケーリングし、結果を改善できます。詳細については、大きさが異なるデータの正規化を参照してください。
アルゴリズム
scatteredInterpolant は散布サンプル点の Delaunay 三角形分割を使用して内挿を実行します[1]。
参照
[1] Amidror, Isaac. “Scattered data interpolation methods for electronic imaging systems: a survey.” Journal of Electronic Imaging. Vol. 11, No. 2, April 2002, pp. 157–176.
拡張機能
バージョン履歴
R2013a で導入参考
griddedInterpolant | griddata | griddatan | ndgrid | meshgrid