boxchart
ボックス チャート (箱ひげ図)
構文
説明
ベクトルと行列のデータ
boxchart( は行列 ydata)ydata の各列に対してボックス チャート (箱ひげ図) を作成します。ydata がベクトルの場合、boxchart は単一のボックス チャートを作成します。
各ボックス チャートには、中央値、上位四分位数、下位四分位数、すべての外れ値 (四分位数間範囲を使用して計算)、外れ値でない最小値と最大値の各情報が表示されます。詳細については、ボックス チャート (箱ひげ図)を参照してください。
boxchart( は xgroupdata,ydata)xgroupdata の一意の値に従ってベクトル ydata のデータをグループ化し、データの各グループを個別のボックス チャートとしてプロットします。xgroupdata は各ボックス チャートの x 軸上の位置を決定します。ydata はベクトルでなければならず、xgroupdata の長さは ydata と同じでなければなりません。
boxchart(___,'GroupByColor', は、色を使用してボックス チャートを区別します。ソフトウェアでは、cgroupdata)xgroupdata (指定している場合) と cgroupdata の一意の値の組み合わせに従ってベクトル ydata のデータをグループ化し、データの各グループを個別のボックス チャートとしてプロットします。次にベクトル cgroupdata は、各ボックス チャートの色を決定します。ydata はベクトルでなければならず、cgroupdata は ydata と同じ長さでなければなりません。'GroupByColor' 名前と値のペアの引数は、前述した構文における任意の入力引数の組み合わせの後に指定します。
テーブル データ
追加オプション
boxchart(___, は、1 つ以上の名前と値のペアの引数を使用して追加のチャート オプションを指定します。たとえば、Name,Value)'Notch','on' を指定してノッチを使用することにより、サンプルの中央値を比較できます。名前と値のペアの引数は、その他すべての入力引数の後に指定します。プロパティの一覧については、BoxChart のプロパティ を参照してください。
b = boxchart(___)BoxChart オブジェクトを返します。cgroupdata を指定しない場合、b には 1 つのオブジェクトが含まれます。指定した場合、b には、cgroupdata の各一意の値ごとに 1 つずつある、オブジェクトのベクトルが含まれます。b を使用してボックス チャートの作成後にプロパティを設定します。プロパティの一覧については、BoxChart のプロパティ を参照してください。
例
年齢のベクトルから単一のボックス チャートを作成します。ボックス チャートを使用して年齢の分布を可視化します。
patients データ セットを読み込みます。変数 Age には患者 100 名の年齢が含まれています。ボックス チャートを作成して、年齢の分布を可視化します。
load patients boxchart(Age) ylabel('Age (years)')
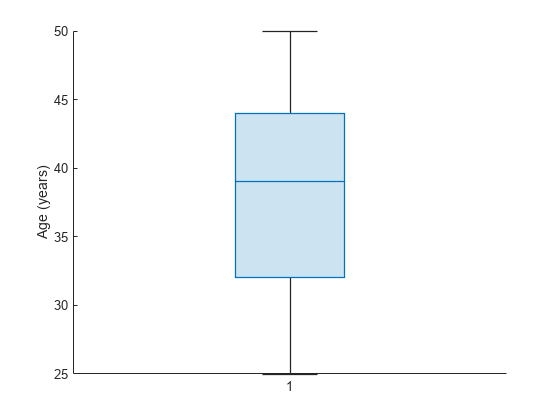
患者の年齢の中央値である 39 歳は、ボックス内の線として示されます。上位四分位数と下位四分位数の 32 歳と 44 歳はそれぞれ、ボックスの上端と下端として示されます。ひげ (ボックスの下と上にはみ出している線) は、最も年齢の低い患者と、最も年齢の高い患者に対応する終点をもちます。最も年齢の低い患者は 25 歳で、最も年齢の高い患者は 50 歳です。このデータ セットには小さい円で表される外れ値は含まれていません。
データ ヒントを使用してデータの統計量の概要を取得できます。ボックス チャートの上にカーソルを合わせてデータ ヒントを表示します。
ボックス チャートを使用して魔方陣の列および行に沿った値の分布を比較します。
10 行 10 列の魔方陣を作成します。
Y = magic(10)
Y = 10×10
92 99 1 8 15 67 74 51 58 40
98 80 7 14 16 73 55 57 64 41
4 81 88 20 22 54 56 63 70 47
85 87 19 21 3 60 62 69 71 28
86 93 25 2 9 61 68 75 52 34
17 24 76 83 90 42 49 26 33 65
23 5 82 89 91 48 30 32 39 66
79 6 13 95 97 29 31 38 45 72
10 12 94 96 78 35 37 44 46 53
11 18 100 77 84 36 43 50 27 59
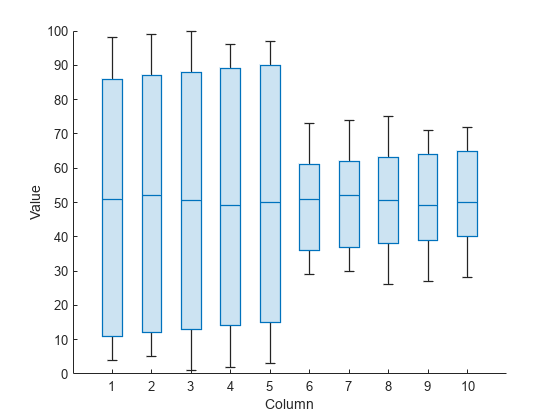
魔方陣の列ごとにボックス チャートを作成します。各列の中央値は類似しています (50 前後)。しかし、Y の最初の 5 列は Y の最後の 5 列よりも四分位数間範囲が大きくなっています。四分位数間範囲は上位四分位数 (ボックスの上端) と下位四分位数 (ボックスの下端) との間の距離です。
boxchart(Y) xlabel('Column') ylabel('Value')
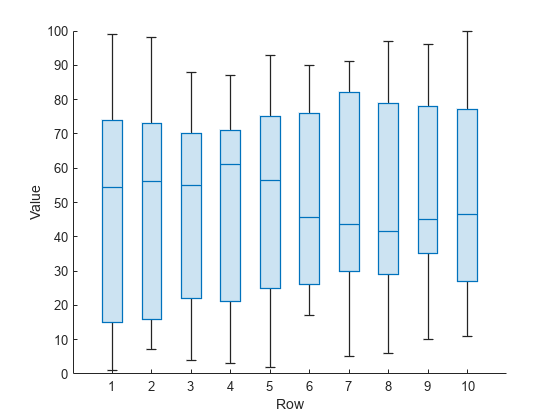
魔方陣の行ごとにボックス チャートを作成します。各行の四分位数間範囲は類似していますが、中央値は行間で異なります。
boxchart(Y') xlabel('Row') ylabel('Value')
R2025a 以降
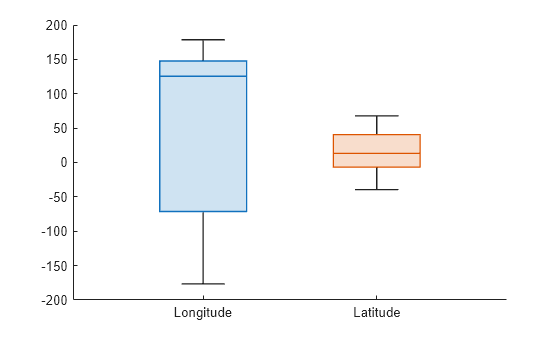
tsunami データ セットをテーブルに読み込みます。Longitude と Latitude の変数のボックス チャートを作成し、変数名でグループにラベルを付けます。
tbl = readtable("tsunamis.xlsx"); boxchart(tbl,["Longitude","Latitude"]) xticklabels(["Longitude","Latitude"])
R2025a 以降
発生した月に基づいて地震のマグニチュードをプロットします。地震マグニチュードのベクトルと、地震ごとの月を示すグループ化変数を使用します。データのグループごとに、ボックス チャートを作成して、x 軸上の指定した位置に配置します。
津波データのセットをワークスペースに table として読み取ります。このデータ セットには地震だけでなく、津波のその他の原因に関する情報も含まれています。table の月、原因、地震マグニチュードの列を示す、最初の 8 行を表示します。
tsunamis = readtable('tsunamis.xlsx'); tsunamis(1:8,["Month","Cause","EarthquakeMagnitude"])
ans=8×3 table
Month Cause EarthquakeMagnitude
_____ __________________ ___________________
10 {'Earthquake' } 7.6
8 {'Earthquake' } 6.9
12 {'Volcano' } NaN
3 {'Earthquake' } 8.1
3 {'Earthquake' } 4.5
5 {'Meteorological'} NaN
11 {'Earthquake' } 9
3 {'Earthquake' } 5.8
table earthquakes を作成します。これには地震によって発生した津波のデータが含まれます。
unique(tsunamis.Cause)
ans = 8×1 cell
{0×0 char }
{'Earthquake' }
{'Earthquake and Landslide'}
{'Landslide' }
{'Meteorological' }
{'Unknown Cause' }
{'Volcano' }
{'Volcano and Landslide' }
idx = contains(tsunamis.Cause,'Earthquake');
earthquakes = tsunamis(idx,:);対応する津波が発生した月に基づいて、地震マグニチュードをグループ化します。月ごとに、個別のボックス チャートを表示します。たとえば、boxchart では 4 番目、5 番目、8 番目の地震マグニチュードなどを使用し、3 番目の月に対応する 3 番目のボックス チャートを作成します。
boxchart(earthquakes,"Month","EarthquakeMagnitude") xlabel('Month') ylabel('Earthquake Magnitude')
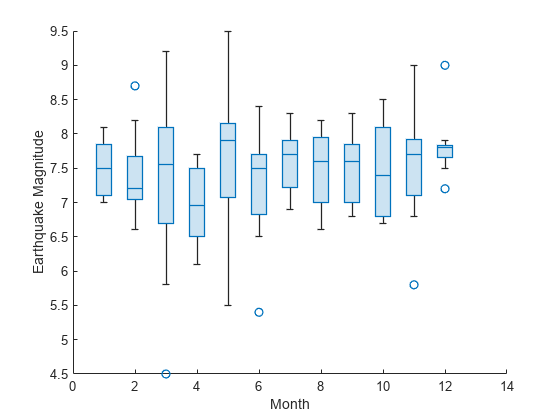
月の値は数値であるため、x 軸ルーラーも数値であることに注意してください。
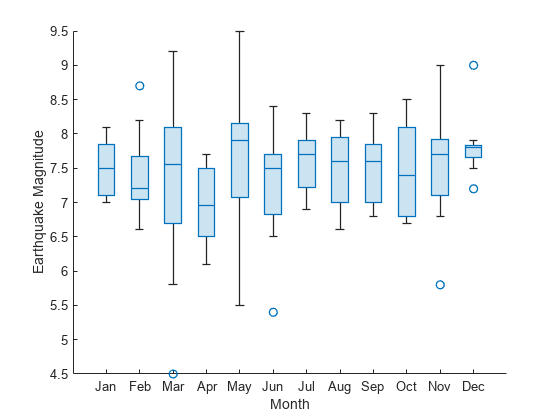
月の名前を説明的にする場合は、earthquakes.Month 変数を categorical 変数に変換します。
monthOrder = ["Jan","Feb","Mar","Apr","May","Jun","Jul", ... "Aug","Sep","Oct","Nov","Dec"]; earthquakes.Months = categorical(earthquakes.Month,1:12,monthOrder);
前と同じボックス チャートを作成します。x 軸ルーラーが categorical になったため、Months のカテゴリの順序により、ボックス チャートの順序が決まります。
boxchart(earthquakes,"Months","EarthquakeMagnitude") xlabel('Month') ylabel('Earthquake Magnitude')
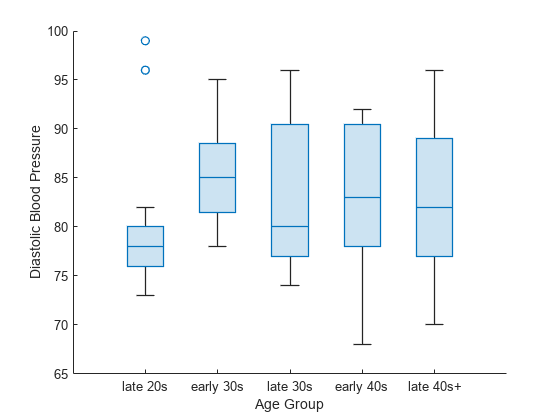
医療患者を年齢に基づいてグループ化し、年齢グループごとに拡張期血圧値のボックス チャートを作成します。
patients データ セットを読み込みます。変数 Age および変数 Diastolic には患者 100 名の年齢と拡張期血圧レベルが含まれます。
load patientsこれらの患者を 5 つの年齢のビンにグループ化します。最低年齢と最高年齢を求めてから、その間の範囲を 5 つの年齢のビンに分割します。関数 discretize を使用し、変数 Age で値をビン化します。bins でビンの名前を使用します。結果の変数 groupAge は変数 categorical になります。
min(Age)
ans = 25
max(Age)
ans = 50
binEdges = 25:5:50;
bins = {'late 20s','early 30s','late 30s','early 40s','late 40s+'};
groupAge = discretize(Age,binEdges,'categorical',bins);年齢グループごとにボックス チャートを作成します。各ボックス チャートには、そのグループの患者の拡張期血圧値が示されます。
boxchart(groupAge,Diastolic) xlabel('Age Group') ylabel('Diastolic Blood Pressure')
2 つのグループ化変数を使用して、データをグループ化し、結果のボックス チャートの位置と色を設定します。
2015 年 1 月から 2016 年 7 月までの毎日の平均気温を含んだサンプル ファイル TemperatureData.csv を読み込みます。ファイルを table に読み取ります。
tbl = readtable('TemperatureData.csv');変数 tbl.Month を変数 categorical に変換します。カテゴリの順序を指定します。
monthOrder = {'January','February','March','April','May','June','July', ...
'August','September','October','November','December'};
tbl.Month = categorical(tbl.Month,monthOrder);月と年を組み合わせた期間中の気温の分布を示すボックス チャートを作成します。tbl.Month を位置のグループ化変数として指定します。'GroupByColor' 名前と値のペア引数を使用して、tbl.Year を色のグループ化変数として指定します。tbl には、2016 年のいくつかの月のデータが含まれていません。
boxchart(tbl.Month,tbl.TemperatureF,'GroupByColor',tbl.Year) ylabel('Temperature (F)') legend
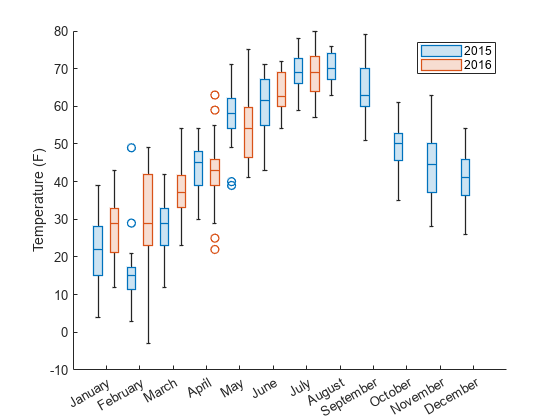
この図では、複数の年にわたり特定の月の気温の分布を簡単に比較できます。たとえば、2 月の気温は 2015 年よりも 2016 年の変動が大きいことがわかります。
ボックス チャートを作成し、hold on を使用してそのボックス チャート上に平均値をプロットします。
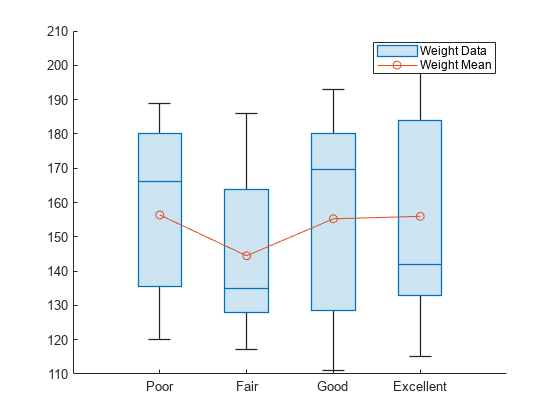
patients データ セットを読み込みます。Poor、Fair、Good、Excellent の各カテゴリは自然順をもつため、SelfAssessedHealthStatus を順序変数 categorical に変換します。
load patients healthOrder = {'Poor','Fair','Good','Excellent'}; SelfAssessedHealthStatus = categorical(SelfAssessedHealthStatus, ... healthOrder,'Ordinal',true);
自己申告の健康状態に従って患者をグループ化し、各グループの患者の平均体重を求めます。
meanWeight = groupsummary(Weight,SelfAssessedHealthStatus,'mean');ボックス チャートを使用して患者の各グループの体重を比較します。平均体重をボックス チャート上にプロットします。
boxchart(SelfAssessedHealthStatus,Weight) hold on plot(meanWeight,'-o') hold off legend(["Weight Data","Weight Mean"])
ノッチを使用して、中央値が相互に大きく異なるかどうかを判断します。
patients データ セットを読み込みます。場所に基づいて患者を分割します。患者のグループごとに、体重のボックス チャートを作成します。'Notch','on' を指定して、各ボックスにノッチと呼ばれる、先細の影付き領域が含まれるようにします。ノッチがオーバーラップしないボックス チャートには、5% の有意水準で異なる中央値があります。
load patients boxchart(categorical(Location),Weight,'Notch','on') ylabel('Weight (lbs)')
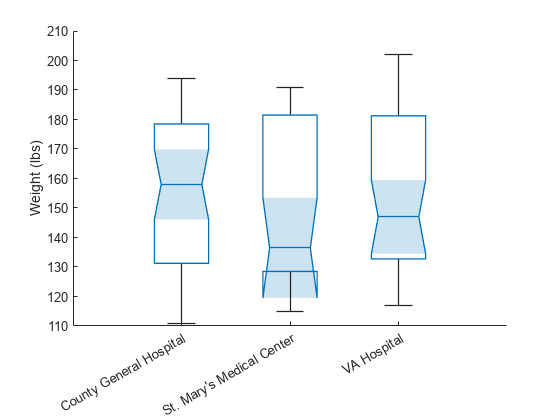
この例では、3 つのノッチがオーバーラップしており、3 つの体重の中央値は大きく異ならないことを示しています。
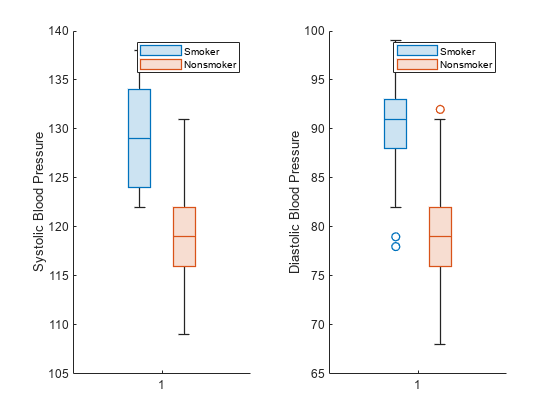
関数 tiledlayout と関数 nexttile を使用して、ボックス チャートのペアを並べて表示します。
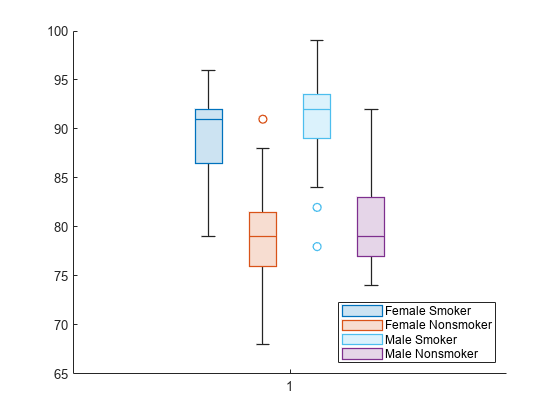
patients データ セットを読み込みます。Smoker を、説明的なカテゴリ名 (1 や 0 ではなく、Smoker や Nonsmoker) をもつ変数 categorical に変換します。
load patients Smoker = categorical(Smoker,logical([1 0]),{'Smoker','Nonsmoker'});
関数 tiledlayout を使用して、1 行 2 列のタイル表示チャート レイアウトを作成します。関数 nexttile を呼び出して、最初の座標軸 ax1 のセットをその内部で作成します。1 番目の座標軸のセットには、喫煙者と非喫煙者に対する収縮期血圧値の 2 つのボックス チャートが表示されます。関数 nexttile を呼び出して、タイル表示チャート レイアウト内で座標軸 ax2 の 2 番目のセットを作成します。座標軸の 2 番目のセットで、拡張期血圧値について同じ操作を実行します。
tiledlayout(1,2) % Left axes ax1 = nexttile; boxchart(ax1,Systolic,'GroupByColor',Smoker) ylabel(ax1,'Systolic Blood Pressure') legend % Right axes ax2 = nexttile; boxchart(ax2,Diastolic,'GroupByColor',Smoker) ylabel(ax2,'Diastolic Blood Pressure') legend
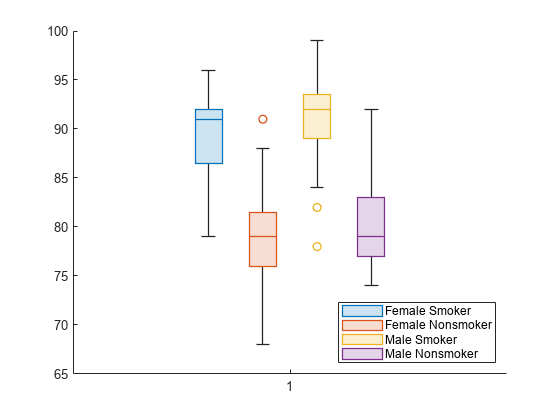
BoxChart オブジェクトのベクトルとして返される、色分けされたボックス チャートのセットを作成します。ベクトルを使用して、1 つのボックス チャートの色を変更します。
patients データ セットを読み込みます。Gender および Smoker を変数 categorical に変換します。1 および 0 ではなく、説明的なカテゴリ名 Smoker および Nonsmoker を指定します。
load patients Gender = categorical(Gender); Smoker = categorical(Smoker,logical([1 0]),{'Smoker','Nonsmoker'});
変数 Gender と変数 Smoker を 1 つのグループ化変数 cgroupdata に連結します。性別および喫煙状態の各組み合わせの拡張期血圧レベルの分布を示すボックス チャートを作成します。b は、データのグループごとに 1 つずつある、BoxChart オブジェクトのベクトルです。
cgroupdata = Gender.*Smoker;
b = boxchart(Diastolic,'GroupByColor',cgroupdata)b = 4×1 BoxChart array: BoxChart BoxChart BoxChart BoxChart
legend('Location','southeast')
SeriesIndex プロパティを使用して 3 つ目のボックス チャートの色を更新します。SeriesIndex プロパティを更新すると、ボックス面の色と外れ値マーカーの色の両方が変更されます。
b(3).SeriesIndex = 6;
多数の外れ値をもつ停電データからボックス チャートを作成し、BoxChart オブジェクトのプロパティを変更することにより、それらを視覚的に簡単に区別できるようにします。外れ値エントリのインデックスを求めます。
停電データをワークスペースに table として読み取ります。table の最初の数行を表示します。
outages = readtable('outages.csv');
head(outages) Region OutageTime Loss Customers RestorationTime Cause
_____________ ________________ ______ __________ ________________ ___________________
{'SouthWest'} 2002-02-01 12:18 458.98 1.8202e+06 2002-02-07 16:50 {'winter storm' }
{'SouthEast'} 2003-01-23 00:49 530.14 2.1204e+05 NaT {'winter storm' }
{'SouthEast'} 2003-02-07 21:15 289.4 1.4294e+05 2003-02-17 08:14 {'winter storm' }
{'West' } 2004-04-06 05:44 434.81 3.4037e+05 2004-04-06 06:10 {'equipment fault'}
{'MidWest' } 2002-03-16 06:18 186.44 2.1275e+05 2002-03-18 23:23 {'severe storm' }
{'West' } 2003-06-18 02:49 0 0 2003-06-18 10:54 {'attack' }
{'West' } 2004-06-20 14:39 231.29 NaN 2004-06-20 19:16 {'equipment fault'}
{'West' } 2002-06-06 19:28 311.86 NaN 2002-06-07 00:51 {'equipment fault'}
BoxChart オブジェクト b を outages.Customers 値から作成し、停電ごとに影響を受けた顧客の数を示します。boxchart は NaN 値をもつエントリを破棄します。
b = boxchart(outages.Customers);
ylabel('Number of Customers')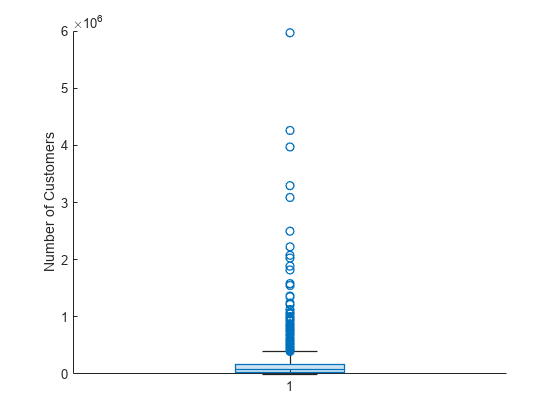
このプロットには多くの外れ値が含まれます。これらを見やすくするために、外れ値に微変動を起こし、外れ値のマーカー スタイルを変更します。BoxChart オブジェクトの JitterOutliers プロパティを 'on' に設定すると、外れ値のマーカーは水平方向にランダムに変位するため、完全にオーバーラップする可能性は非常に低くなります。外れ値の値と縦方向の位置は変更されません。
b.JitterOutliers = 'on'; b.MarkerStyle = '.';
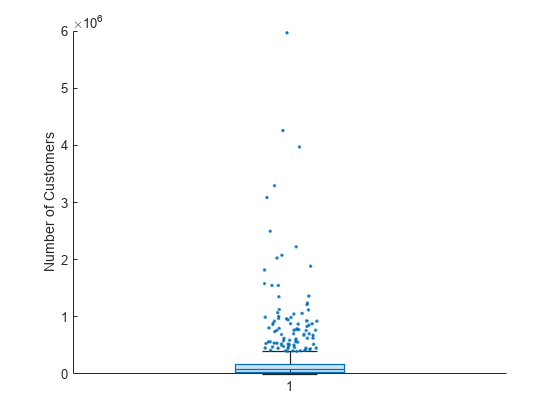
これで、外れ値の分布を簡単に確認できます。
外れ値のインデックスを求めるには、関数 isoutlier を使用します。boxchart の外れ値の定義と一致するように外れ値を計算する 'quartiles' メソッドを指定します。インデックスを使用して outages データのサブセットが含まれる outliers table を作成します。isoutlier で 96 個の外れ値が特定されたことがわかります。
idx = isoutlier(outages.Customers,'quartiles');
outliers = outages(idx,:);
size(outliers,1)ans = 96
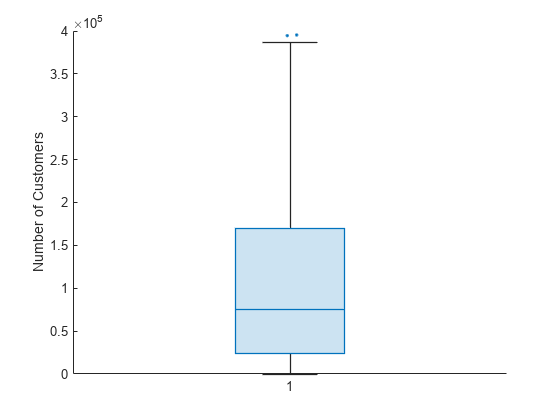
これらすべての外れ値により、ボックス チャートの四分位数が見づらくなっています。これらを挿入するには、y 軸の範囲を変更します。
ylim([0 4e5])
入力引数
名前と値の引数
オプションの引数のペアを Name1=Value1,...,NameN=ValueN として指定します。ここで、Name は引数名で、Value は対応する値です。名前と値の引数は他の引数の後に指定しなければなりませんが、ペアの順序は重要ではありません。
例: boxchart([rand(10,4); 4*rand(1,4)],'BoxFaceColor',[0 0.5 0],'MarkerColor',[0 0.5 0]) は、適用される場合、緑のボックスと緑の外れ値を使用してボックス チャートを作成します。
メモ
ここでは、BoxChart プロパティの一部だけを紹介しています。完全な一覧については、BoxChart のプロパティ を参照してください。
あるいは、名前を使用して一部の一般的な色を指定できます。次の表に、名前の付いた色オプション、等価の RGB 3 成分、および 16 進数カラー コードを示します。
| 色名 | 省略名 | RGB 3 成分 | 16 進数カラー コード | 外観 |
|---|---|---|---|---|
"red" | "r" | [1 0 0] | "#FF0000" |
|
"green" | "g" | [0 1 0] | "#00FF00" |
|
"blue" | "b" | [0 0 1] | "#0000FF" |
|
"cyan" | "c" | [0 1 1] | "#00FFFF" |
|
"magenta" | "m" | [1 0 1] | "#FF00FF" |
|
"yellow" | "y" | [1 1 0] | "#FFFF00" |
|
"black" | "k" | [0 0 0] | "#000000" |
|
"white" | "w" | [1 1 1] | "#FFFFFF" |
|
"none" | 該当なし | 該当なし | 該当なし | 色なし |








次の表に、ライト テーマとダーク テーマでのプロットの既定のカラー パレットを示します。
| パレット | パレットの色 |
|---|---|
R2025a より前: ほとんどのプロットで、これらの色が既定で使用されます。 |
|
|
|


orderedcolors 関数と rgb2hex 関数を使用すると、これらのパレットの RGB 3 成分および 16 進数カラー コードを取得できます。たとえば、"gem" パレットの RGB 3 成分を取得し、16 進数カラー コードに変換します。
RGB = orderedcolors("gem");
H = rgb2hex(RGB);R2023b より前: RGB = get(groot,"FactoryAxesColorOrder") を使用して、RGB 3 成分を取得します。
R2024a より前: H = compose("#%02X%02X%02X",round(RGB*255)) を使用して、16 進数カラー コードを取得します。
例: b = boxchart(rand(10,1),'BoxFaceColor','red')
例: b.BoxFaceColor = [0 0.5 0.5];
例: b.BoxFaceColor = '#EDB120';
R2025a 以降
色グループのレイアウト。"grouped" または "overlaid" として指定します。既定では、各色のグループ化のボックス チャートは互いに並べてプロットされます。各ボックス チャートの幅は、cgroupdata に指定された色の数 (つまり、カラー データの一意の値) の逆数に応じて決まります。
ColorGroupLayout="overlaid" を指定すると、次のようになります。
各色のグループ化のボックス チャートは、互いに重ねてプロットされます。
ColorGroupWidthの値は無視されます。BoxWidthを指定することで、重ね合わされた色のグループ化間の間隔を調整できます。
データ型: string | char
外れ値スタイル。次の表にリストされたオプションのいずれかとして指定します。
| マーカー | 説明 | 結果のマーカー |
|---|---|---|
"o" | 円 |
|
"+" | プラス記号 |
|
"*" | アスタリスク |
|
"." | 点 |
|
"x" | 十字 |
|
"_" | 水平線 |
|
"|" | 垂直線 |
|
"square" | 正方形 |
|
"diamond" | 菱形 |
|
"^" | 上向き三角形 |
|
"v" | 下向き三角形 |
|
">" | 右向き三角形 |
|
"<" | 左向き三角形 |
|
"pentagram" | 星形五角形 |
|
"hexagram" | 星形六角形 |
|
"none" | マーカーなし | 該当なし |















例: b = boxchart([rand(10,1);2],'MarkerStyle','x')
例: b.MarkerStyle = 'x';
出力引数
詳細
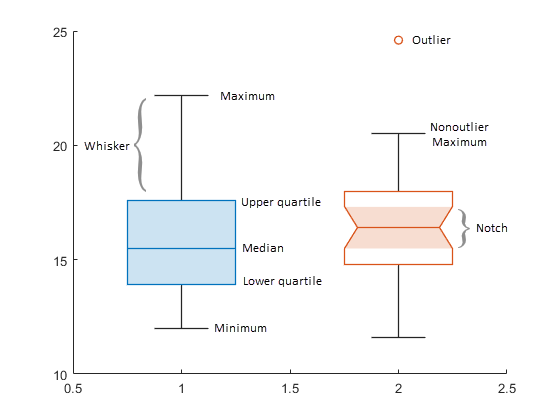
ボックス チャート (箱ひげ図) により、データ サンプルの要約統計量の視覚的表現が提供されます。数値データを指定すると、対応するボックス チャートには、中央値、上位四分位数、下位四分位数、すべての外れ値 (四分位数間範囲を使用して計算)、外れ値でない最小値と最大値の各情報が表示されます。
各ボックス内の線はサンプルの中央値です。関数
medianを使用して中央値の値を計算できます。各ボックスの上端と下端はそれぞれ、上位四分位数と下位四分位数です。上端と下端の間の距離は四分位数間範囲 (IQR) です。
四分位数を計算する方法の詳細については、
quantileを参照してください。ここで、上位四分位数は 0.75 四分位数に対応し、下位四分位数は 0.25 四分位数に対応します。外れ値は、ボックスの上端と下端から 1.5 · IQR を超えて離れている値です。通常の設定では、
boxchartには'o'記号を使用した外れ値がそれぞれ表示されます。外れ値の計算は'quartiles'メソッドを使用した関数isoutlierと同じです。ひげは、各ボックスの上下を超えている線です。一方のひげは上位四分位数を "最大非外れ値" (外れ値でない最大データ値) につなげ、もう一方は下位四分位数を "最小非外れ値" (外れ値でない最小データ値) につなげます。
ノッチは、複数のボックス チャートに対するサンプルの中央値を比較する場合に役立ちます。
'Notch','on'を指定すると、関数boxchartにより、各中央値の周りに先細の影付き領域が作成されます。ノッチがオーバーラップしないボックス チャートには、5% の有意水準で異なる中央値があります。有意水準は標準の分布仮定に基づいていますが、中央値の比較はその他の分布に対して十分にロバストです。ノッチ領域の上端と下端は と にそれぞれ対応しています。ここで、m は中央値、IQR は四分位数間範囲、n は
NaN値を除いたデータ点数です。
ヒント
BoxChartオブジェクトのデータを調べるには、データ ヒントを使用します。一部のオプションはライブ エディターでは使用できません。2 種類のデータ ヒントを
BoxChartオブジェクトに追加できます。1 つは各ボックス チャート、もう 1 つは各外れ値に使用します。一般的なデータ ヒントは、ボックス チャートでクリックする位置に関係なく、非外れ最大値で表示されます。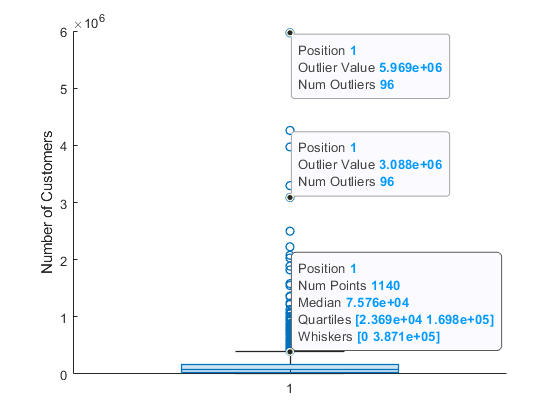
メモ
表示された
Num Points値には対応するydataのNaN値が含まれますが、ボックス チャートの統計を計算する前にboxchartはNaN値を破棄します。関数
datatipを使用してデータ ヒントをBoxChartオブジェクトに追加できますが、データ ヒントのインデックス付けが他のチャートと異なります。boxchartは最初にインデックスをボックス チャートに割り当ててから、インデックスを外れ値に割り当てます。たとえば、BoxChartオブジェクトbに 2 つのボックス チャートと 1 つの外れ値が表示される場合、datatip(b,'DataIndex',3)は外れ値点でデータ ヒントを作成します。