arrayfun
配列の個々の要素に関数を適用
構文
説明
B = arrayfun(func,A)A の要素ごとに関数 func を適用します。次に、arrayfun は A の i 番目の要素について B(i) = func(A(i)) となるように func の出力を出力配列 B に連結します。入力引数 func は、スカラーを返す関数への関数ハンドルです。この構文を使用するには、func からの出力が常に同じデータ型でなければなりません。関数の出力のデータ型が異なる場合は、名前と値の引数 UniformOutput を false に設定する必要があります。配列 A と B のサイズは同じです。
arrayfun での B の要素の計算順序を指定したり、特定の順序で計算される要素に依存することはできません。
B = arrayfun(___,Name,Value)Name,Value のペアの引数で指定された追加オプションを使って func を適用します。たとえば、出力値を cell 配列で返すには、'UniformOutput',false を指定します。func の返した値を配列に連結できない場合に、cell 配列として B を返すことができます。前述の構文のいずれかの入力引数と Name,Value のペアの引数を使用することができます。
[B1,...,Bm] = arrayfun(___) は、func が m 個の出力値を返す場合に、複数の出力配列 B1,...,Bm を返します。func は異なるデータ型の出力引数を返すことができますが、func の呼び出しごとに各出力のデータ型は同じでなければなりません。この構文では、前述の構文の入力引数のいずれかを使用できます。
func の出力引数の数は、A1,...,An に指定された入力引数の数と一致する必要はありません。
例
非スカラー構造体配列を作成します。各構造体には、乱数のベクトルを含むフィールドが 1 つあります。ベクトルのサイズは異なります。
S(1).f1 = rand(1,5); S(2).f1 = rand(1,10); S(3).f1 = rand(1,15)
S=1×3 struct array with fields:
f1
関数 arrayfun を使用して S の各フィールドの平均を計算します。structfun の入力引数はスカラー構造体でなければならないため、この計算には structfun を使用できません。
A = arrayfun(@(x) mean(x.f1),S)
A = 1×3
0.6786 0.6216 0.6069
各構造体に数値配列を含む 2 つのフィールドがある構造体配列を作成します。
S(1).X = 5:5:100; S(1).Y = rand(1,20); S(2).X = 10:10:100; S(2).Y = rand(1,10); S(3).X = 20:20:100; S(3).Y = rand(1,5)
S=1×3 struct array with fields:
X
Y
数値配列をプロットします。関数 plot から chart line オブジェクトの配列を返し、これらを使用して各データ点セットに異なるマーカーを追加します。arrayfun は、そのデータ型のオブジェクトが連結できる限り、任意のデータ型の配列を返すことができます。
figure hold on p = arrayfun(@(a) plot(a.X,a.Y),S); p(1).Marker = 'o'; p(2).Marker = '+'; p(3).Marker = 's'; hold off
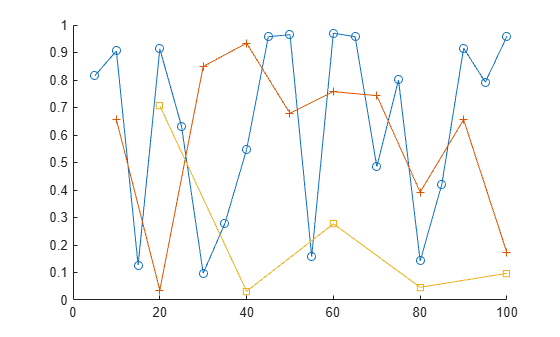
非スカラー構造体配列を作成します。各構造体には、数値行列を含むフィールドが 1 つあります。
S(1).f1 = rand(3,5); S(2).f1 = rand(6,10); S(3).f1 = rand(4,2)
S=1×3 struct array with fields:
f1
関数 arrayfun を使用して S の各フィールドの平均を計算します。mean は各列の平均を含むベクトルを返すため、平均は配列として返されません。cell 配列に平均を返すには、名前と値のペア 'UniformOutput',false を指定します。
A = arrayfun(@(x) mean(x.f1),S,'UniformOutput',false)A=1×3 cell array
{[0.6158 0.5478 0.5943 0.6977 0.7476]} {[0.6478 0.6664 0.3723 0.4882 0.4337 0.5536 0.5124 0.4436 0.5641 0.5566]} {[0.3534 0.5603]}
非スカラー構造体配列を作成します。
S(1).f1 = 1:10; S(2).f1 = [2; 4; 6]; S(3).f1 = []
S=1×3 struct array with fields:
f1
関数 arrayfun を使用して、S の各フィールドのサイズを計算します。行数と列数はそれぞれ 1 行 3 列の数値配列で表されます。
[nrows,ncols] = arrayfun(@(x) size(x.f1),S)
nrows = 1×3
1 3 0
ncols = 1×3
10 1 0
入力引数
名前と値の引数
出力引数
制限
異種混合配列
UniformOutputがtrueに設定されている場合、arrayfunは異種混合配列をサポートしません。複素数からなる入力配列の動作の違い
入力配列
Aが複素数の配列であり、虚数部が 0 に等しい要素があると、arrayfun呼び出しと、配列のインデックス付けとで結果が異なる場合があります。arrayfunは、常にそのような数を虚数部が 0 に等しい複素数として扱います。しかし、インデックス付けは、そのような値を実数として返します。動作の違いを説明するために、まず複素数の配列を作成します。
A = zeros(2,1); A(1) = 1; A(2) = 0 + 1i
A = 1.0000 + 0.0000i 0.0000 + 1.0000i
次に cell 配列を作成し、
Aの要素を割り当てます。A(1)にインデックスを付けると、虚数部が 0 に等しいため、その値は実数として返されます。cell 配列は異なる型をもつデータを保存できるため、実数値と複素数値をC1の異なる cell に保存できます。C1 = cell(2,1); C1{1} = A(1); C1{2} = A(2)C1 = 2×1 cell array {[ 1]} {[0.0000 + 1.0000i]}arrayfunを呼び出して、Aの要素にアクセスします。値を cell 配列に割り当てます。arrayfunは、A(1)にアクセスするとき、この値を複素数として扱い、C2{1}に割り当てます。C2 = arrayfun(@(x) x, A, 'UniformOutput', false)C2 = 2×1 cell array {[1.0000 + 0.0000i]} {[0.0000 + 1.0000i]}
拡張機能
バージョン履歴
R2006a より前に導入
参考
structfun | cellfun | spfun | cell2mat | splitapply | varfun | rowfun | groupsummary