このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
オーディオ処理
アプリ
| 信号ラベラー | 対象となる信号の属性、領域および点へのラベル付けまたは特徴の抽出 |
関数
ブロック
トピック
- Deep Learning for Audio Applications (Audio Toolbox)
Learn common tools and workflows to apply deep learning to audio applications.
- Classify Sound Using Deep Learning (Audio Toolbox)
Train, validate, and test a simple long short-term memory (LSTM) to classify sounds.
- Adapt Pretrained Audio Network for New Data Using Deep Network Designer
This example shows how to interactively adapt a pretrained network to classify new audio signals using Deep Network Designer.
- Audio Transfer Learning Using Experiment Manager
Configure an experiment that compares the performance of multiple pretrained networks applied to a speech command recognition task using transfer learning.
- Compare Speaker Separation Models
Compare the performance, size, and speed of multiple deep learning speaker separation models.
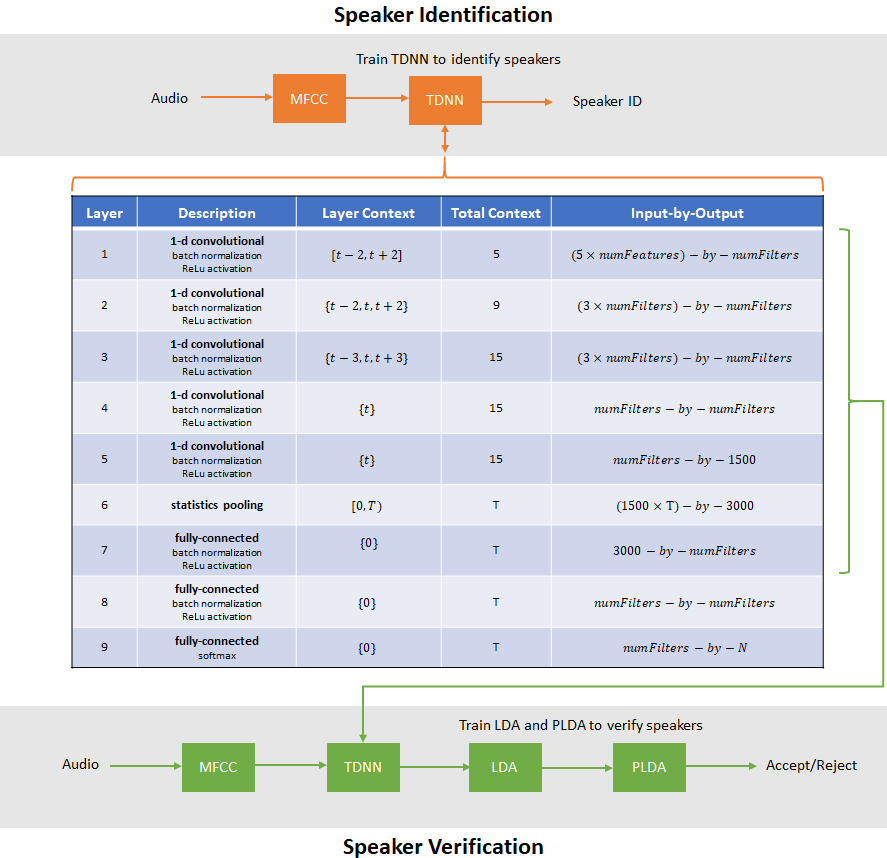
- Speaker Identification Using Custom SincNet Layer and Deep Learning
Perform speech recognition using a custom deep learning layer that implements a mel-scale filter bank.
- Dereverberate Speech Using Deep Learning Networks
Train a deep learning model that removes reverberation from speech.
- Speech Command Recognition in Simulink
Detect the presence of speech commands in audio using a Simulink® model.
- オーディオの特徴に関する逐次特徴選択
この例では、数字の音声認識タスクに適用される特徴選択の標準的なワークフローを説明します。
- Train Spoken Digit Recognition Network Using Out-of-Memory Audio Data
This example trains a spoken digit recognition network on out-of-memory audio data using a transformed datastore. In this example, you apply a random pitch shift to audio data used to train a convolutional neural network (CNN). For each training iteration, the audio data is augmented using the
audioDataAugmenter(Audio Toolbox) object and then features are extracted using theaudioFeatureExtractor(Audio Toolbox) object. The workflow in this example applies to any random data augmentation used in a training loop. The workflow also applies when the underlying audio data set or training features do not fit in memory. - Train Spoken Digit Recognition Network Using Out-of-Memory Features
This example trains a spoken digit recognition network on out-of-memory auditory spectrograms using a transformed datastore. In this example, you extract auditory spectrograms from audio using
audioDatastore(Audio Toolbox) andaudioFeatureExtractor(Audio Toolbox), and you write them to disk. You then use asignalDatastore(Signal Processing Toolbox) to access the features during training. The workflow is useful when the training features do not fit in memory. In this workflow, you only extract features once, which speeds up your workflow if you are iterating on the deep learning model design. - Investigate Audio Classifications Using Deep Learning Interpretability Techniques
This example shows how to use interpretability techniques to investigate the predictions of a deep neural network trained to classify audio data.
- Accelerate Audio Deep Learning Using GPU-Based Feature Extraction
Leverage GPUs for feature extraction to decrease the time required to train an audio deep learning model.
関連情報
注目の例















You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)