オーディオ処理
アプリ
| 信号ラベラー | 対象となる信号の属性、領域および点へのラベル付け |
関数
ブロック
トピック
- Deep Learning for Audio Applications (Audio Toolbox)
Learn common tools and workflows to apply deep learning to audio applications.
- Classify Sound Using Deep Learning (Audio Toolbox)
Train, validate, and test a simple long short-term memory (LSTM) to classify sounds.
- Adapt Pretrained Audio Network for New Data Using Deep Network Designer
This example shows how to interactively adapt a pretrained network to classify new audio signals using Deep Network Designer.
- Audio Transfer Learning Using Experiment Manager
Configure an experiment that compares the performance of multiple pretrained networks applied to a speech command recognition task using transfer learning.
- Compare Speaker Separation Models
Compare the performance, size, and speed of multiple deep learning speaker separation models.
- Speaker Identification Using Custom SincNet Layer and Deep Learning
Perform speech recognition using a custom deep learning layer that implements a mel-scale filter bank.
- Dereverberate Speech Using Deep Learning Networks
Train a deep learning model that removes reverberation from speech.
- オーディオの特徴に関する逐次特徴選択
この例では、数字の音声認識タスクに適用される特徴選択の標準的なワークフローを説明します。
- Train Spoken Digit Recognition Network Using Out-of-Memory Audio Data
This example trains a spoken digit recognition network on out-of-memory audio data using a transformed datastore.
- Train Spoken Digit Recognition Network Using Out-of-Memory Features
This example trains a spoken digit recognition network on out-of-memory auditory spectrograms using a transformed datastore.
- Investigate Audio Classifications Using Deep Learning Interpretability Techniques
This example shows how to use interpretability techniques to investigate the predictions of a deep neural network trained to classify audio data.
- Accelerate Audio Deep Learning Using GPU-Based Feature Extraction
Leverage GPUs for feature extraction to decrease the time required to train an audio deep learning model.
- AI for Speech Command Recognition (Audio Toolbox)
Build, train, compress, and deploy a deep learning model for speech command recognition.
- ステップ 1: Train Deep Learning Network for Speech Command Recognition (Audio Toolbox)
- ステップ 2: Prune and Quantize Speech Command Recognition Network (Audio Toolbox)
- ステップ 3: Apply Speech Command Recognition Network in Simulink (Audio Toolbox)
- ステップ 4: Apply Speech Command Recognition Network in Smart Speaker Simulink Model (Audio Toolbox)
- ステップ 5: Deploy Smart Speaker Model on Raspberry Pi (Audio Toolbox)
関連情報
注目の例

Compress Machine Fault Recognition Neural Network Using Projection
Compress a pretrained acoustics-based machine fault recognition neural network using projection and principal component analysis.
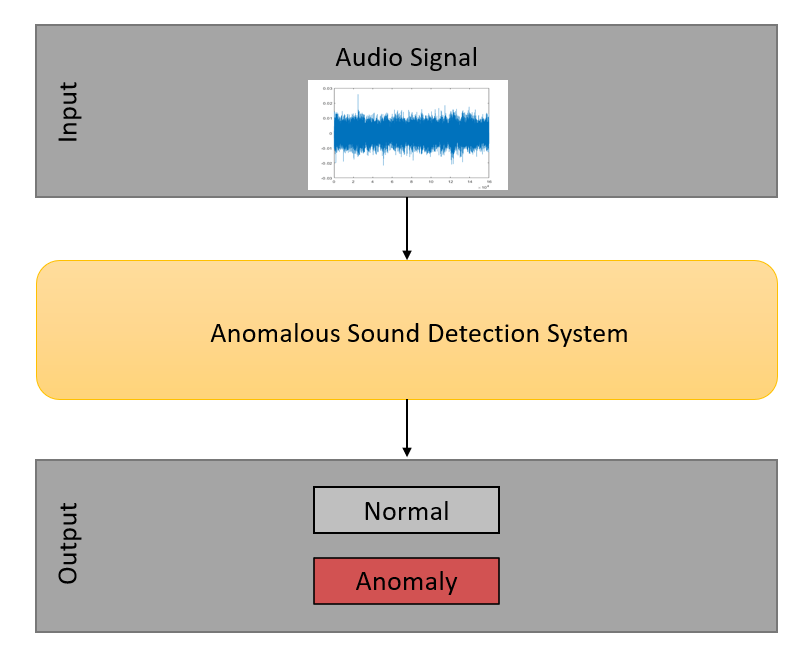
Audio-Based Anomaly Detection for Machine Health Monitoring
Design an autoencoder neural network to perform anomaly detection for machine sounds using unsupervised learning.
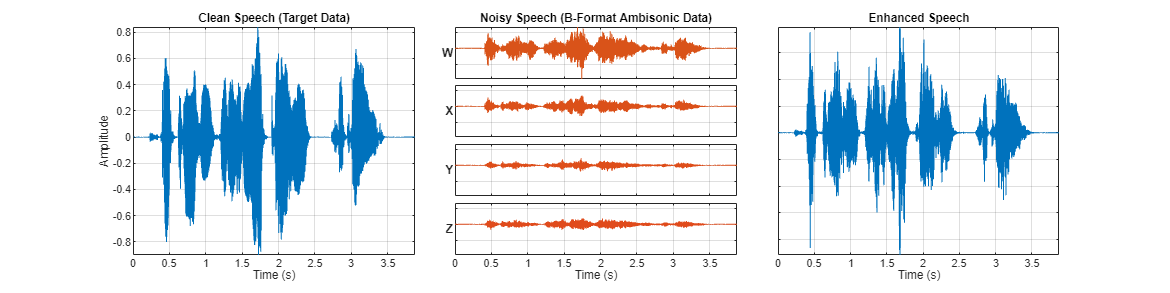
3-D Speech Enhancement Using Trained Filter and Sum Network
Perform speech enhancement using a pretrained filter and sum network (FaSNet) with ambisonic data.

3-D Sound Event Localization and Detection Using Trained Recurrent Convolutional Neural Network
Perform 3-D sound event localization and detection using a pretrained deep learning model.
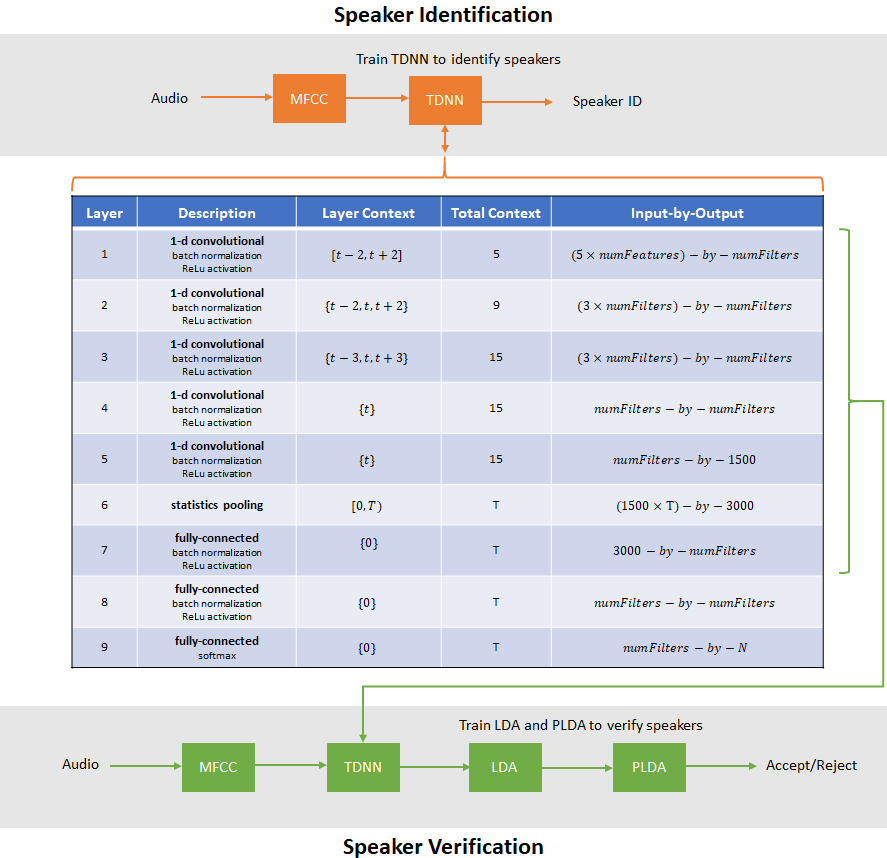
Speaker Recognition Using x-vectors
Develop an x-vector system to perform speaker recognition.
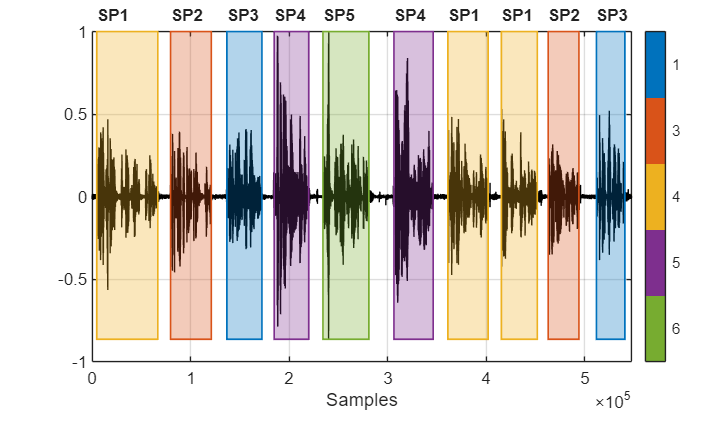
Speaker Diarization Using x-vectors
Speaker diarization is the process of partitioning an audio signal into segments according to speaker identity. It answers the question "who spoke when" without prior knowledge of the speakers and, depending on the application, without prior knowledge of the number of speakers.

深層学習を使用した音声コマンド認識モデルの学習
この例では、オーディオに存在する音声コマンドを検出する深層学習モデルに学習させる方法を説明します。この例では、Speech Commands Dataset [1] を使用して、一連のコマンドを認識する畳み込みニューラル ネットワークに学習させます。

MFCC ネットワークと LSTM ネットワークを使用したノイズ内のキーワード スポッティング
この例では、深層学習ネットワークを使用してノイズを含む音声からキーワードを特定する方法を説明します。特に、この例では、双方向長短期記憶 (BiLSTM) ネットワークとメル周波数ケプストラム係数 (MFCC) を使用します。

深層学習ネットワークを使用した音声のノイズ除去
この例では、深層学習ネットワークを使用して音声信号をノイズ除去する方法を説明します。例は、同じタスクに適用された 2 つのタイプのネットワーク (全結合と畳み込み) を比較します。

音声合成の敵対的生成ネットワーク (GAN) の学習
この例では、敵対的生成ネットワーク (GAN) に学習させ、そのネットワークを使用して音声を生成する方法を説明します。

深層学習を使用したノイズに含まれる音声区間の検出
この例では、事前学習済みの深層学習モデルを使用して、SNR が低い環境内でバッチとストリーミングによる音声区間検出 (VAD) を実行します。モデルとその学習方法の詳細については、Train Voice Activity Detection in Noise Model Using Deep Learning (Audio Toolbox)を参照してください。

音声感情認識
この例では、BiLSTM ネットワークを使用した単純な音声感情認識 (SER) システムについて説明します。まず、データセットをダウンロードし、各ファイルについて学習済みのネットワークをテストします。ネットワークは、小規模なドイツ語のデータベースで学習済みです [1]。

後期融合を使用した音響シーン認識
この例では、音響シーン認識のためのマルチモデル後期融合システムを作成する方法を説明します。この例では、メル スペクトログラムと、ウェーブレット散乱によるアンサンブル分類器を使用して、畳み込みニューラル ネットワーク (CNN) に学習させます。ここでは TUT データセットを使用して学習と評価を行います [1]。

エンドツーエンドの話者分離モデルの学習
話者に依存しない音声分離にエンドツーエンドの深層学習ネットワークを使用する。
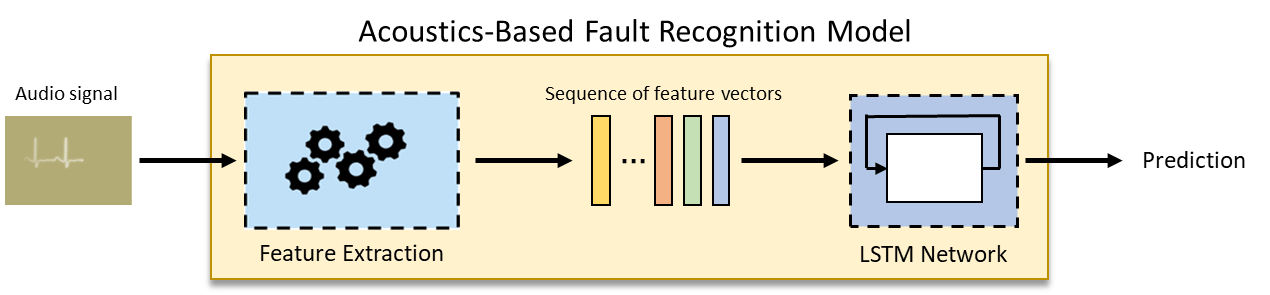
Acoustics-Based Machine Fault Recognition
Develop a deep learning model to detect faults in an air compressor and package the system to operate on streaming data.

Audio Event Classification Using TensorFlow Lite on Raspberry Pi
Perform audio event classification on Raspberry Pi® using the YAMNet pretrained deep neural network from the TensorFlow™ Lite library.

Keyword Spotting in Noise Code Generation on Raspberry Pi
Demonstrates code generation for keyword spotting using a Bidirectional Long Short-Term Memory (BiLSTM) network and mel frequency cepstral coefficient (MFCC) feature extraction on Raspberry Pi®. MATLAB® Coder™ with Deep Learning Support enables the generation of a standalone executable (.elf) file on Raspberry Pi. Communication between MATLAB (.mlx) file and the generated executable file occurs over asynchronous User Datagram Protocol (UDP). The incoming speech signal is displayed using a timescope. A mask is shown as a blue rectangle surrounding spotted instances of the keyword, YES. For more details on MFCC feature extraction and deep learning network training, visit Keyword Spotting in Noise Using MFCC and LSTM Networks (Audio Toolbox).

デスクトップでの音声コマンド認識コードの生成
この例では、音声コマンド認識のために特徴抽出と畳み込みニューラル ネットワーク (CNN) を展開する方法を示します。この例では、生成されたコードは MATLAB 実行可能ファイル (MEX) 関数であり、予測された音声コマンドと時間領域信号および聴覚スペクトログラムを表示する MATLAB スクリプトによって呼び出されます。オーディオの前処理およびネットワーク学習の詳細については、Train Deep Learning Network for Speech Command Recognition (Audio Toolbox)を参照してください。

Acoustics-Based Machine Fault Recognition Code Generation
Generate a MATLAB® standalone executable for acoustics-based machine fault recognition.

Speech Command Recognition on Raspberry Pi Using Simulink
Deploy feature extraction and a convolutional neural network for speech command recognition on Raspberry Pi.