視覚言語モデル
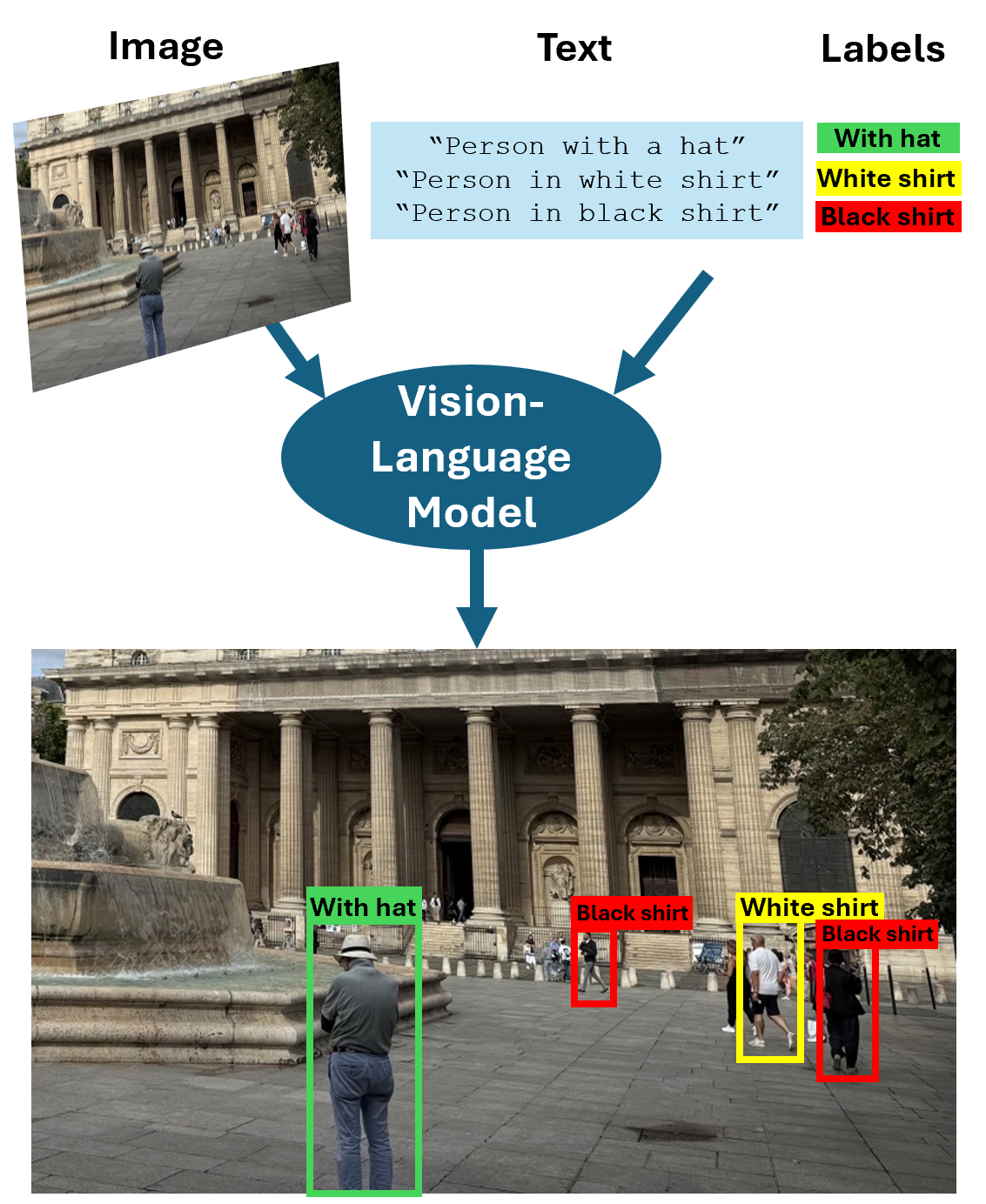
視覚言語モデル (VLM) は、イメージとテキストを入力として受け取り、テキスト出力を生成したり、対応する注釈付きの境界ボックスを返したりできるマルチモーダル モデルであり、オブジェクト検出や視覚的グラウンディングなどのタスクを可能にします。これらのモデルは、イメージやビデオ内の視覚コンテンツを解析し、付随するテキストを処理し、視覚データとテキスト データの間の相関関係を特定することができます。これらは、言語の文脈の中で視覚情報を解釈する、さまざまなタスクを可能にしますが、これは真の理解に基づいているのではなく、予測アルゴリズムを使用したものです。Computer Vision Toolbox™ は、CLIP、Grounding DINO、Moondream など、以下の用途向けに、事前学習済みの VLM を複数提供しています。
イメージ キャプションの生成 — イメージの説明テキストを生成します。
画像検索 — テキストの説明に最もよく一致するイメージを、事前定義されたイメージ セットから特定します。
オブジェクト検出 — テキストベースのクエリに基づいてイメージ内のオブジェクトを検出します。
イメージ分類 — テキスト カテゴリに基づいてイメージを分類します。
さらに、VLM を使用し、イメージ ラベラー アプリとビデオ ラベラー アプリで説明テキスト プロンプトを使用して、グラウンド トゥルースに自動的にラベル付けできます。開始するには、Get Started with Vision-Language Modelsを参照してください。
関数
トピック
開始
- Get Started with Vision-Language Models
Use vision-language models for multimodal tasks such as image captioning, zero-shot classification, and image search.
注目の例

Automatically Search and Label Video Frames Using VLMs
Automatically search and detect objects based on natural language text queries using vision-language models (VLMs).
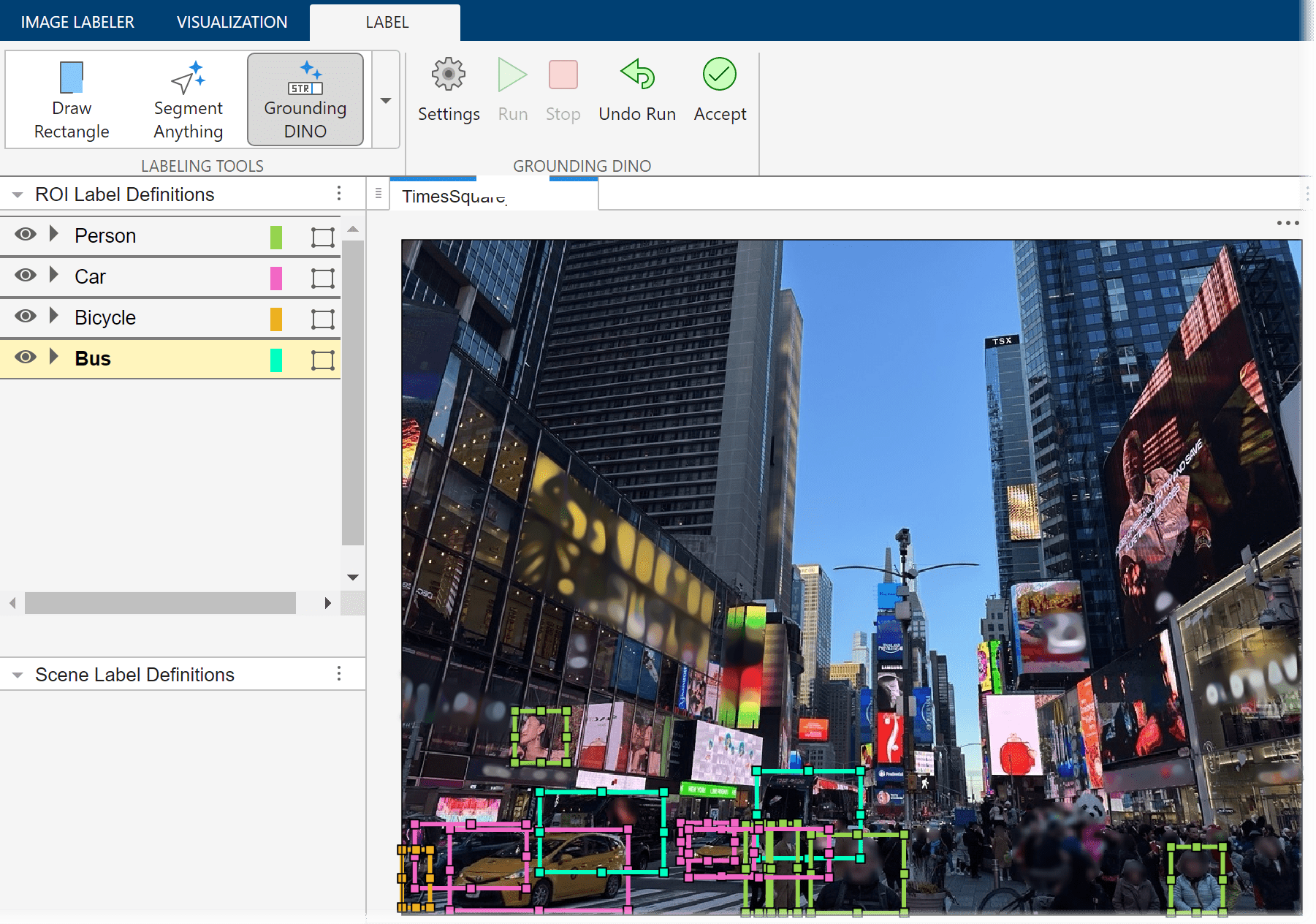
Automatically Label Ground Truth Using Vision-Language Model
Automatically label ground truth images for object detection using the Grounding DINO vision-language model (VLM).
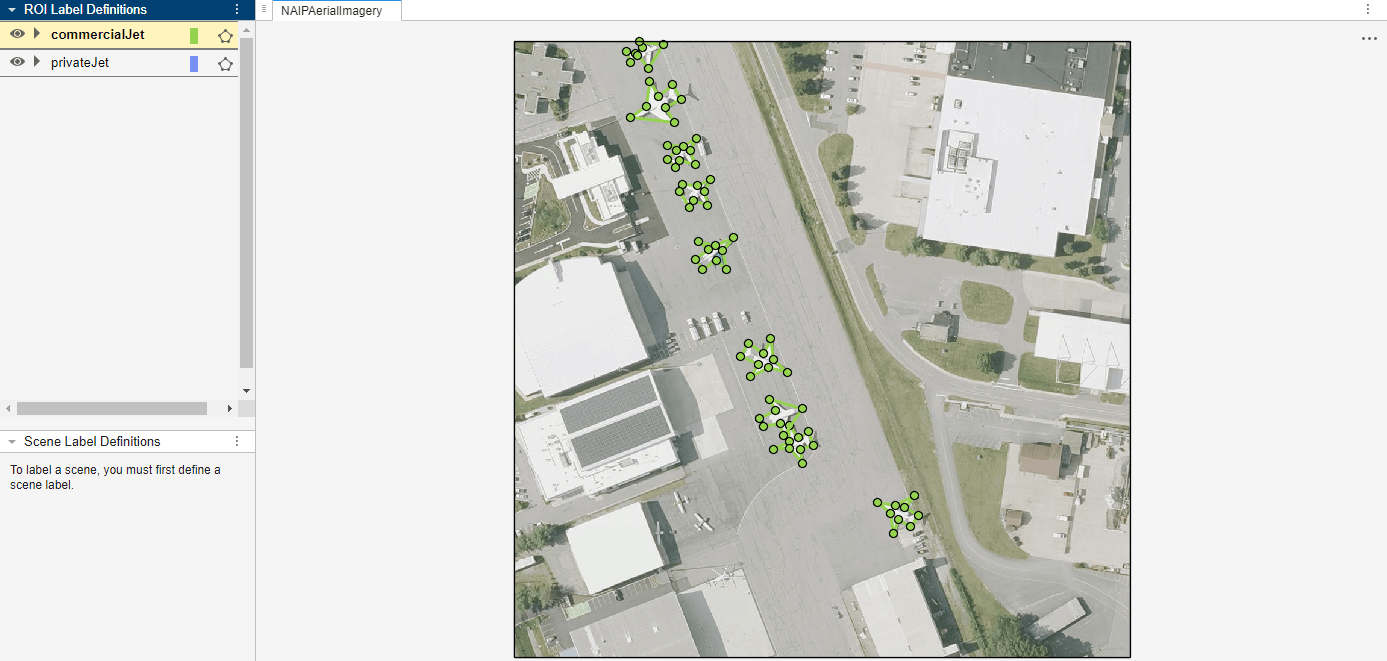
Automate Ground Truth Polygon Labeling Using Grounded SAM Model
Combine Grounding DINO and the Segment Anything Model 2 (SAM 2) to automatically produce polygon labels using the Video Labeler app.
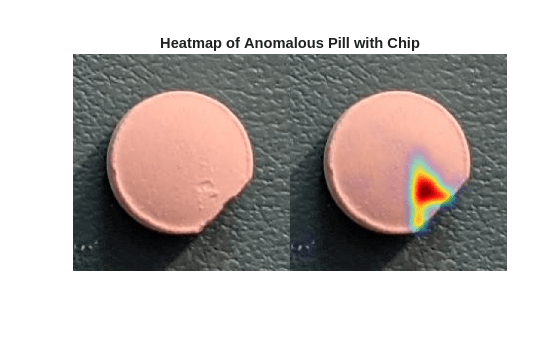
Detect Industrial Defects Using Zero-Shot AnomalyCLIP
Detect and localize industrial production defects in pill images using an AnomalyCLIP anomaly detection network.