Faster R-CNN 深層学習を使用したオブジェクトの検出
この例では、Faster R-CNN (Regions with Convolutional Neural Networks) オブジェクト検出器に学習させる方法を説明します。
深層学習は、ロバストなオブジェクト検出器に学習させるために使用できる強力な機械学習手法です。オブジェクト検出の深層学習手法には、Faster R-CNN や You Only Look Once (YOLO) v2 などの複数の手法が存在します。この例では、関数 trainFasterRCNNObjectDetector を使用して、Faster R-CNN 車両検出器に学習させます。詳細については、オブジェクトの検出を参照してください。
事前学習済みの検出器のダウンロード
学習の完了を待たなくて済むように、事前学習済みの検出器をダウンロードします。検出器に学習させる場合は、変数 doTraining を true に設定します。
doTraining = false; if ~doTraining && ~exist("fasterRCNNResNet50EndToEndVehicleExample.mat","file") disp("Downloading pretrained detector (118 MB)..."); pretrainedURL = "https://www.mathworks.com/supportfiles/vision/data/fasterRCNNResNet50EndToEndVehicleExample.mat"; websave("fasterRCNNResNet50EndToEndVehicleExample.mat",pretrainedURL); end
Downloading pretrained detector (118 MB)...
データ セットの読み込み
この例では、295 個のイメージを含む小さなラベル付きデータセットを使用します。これらのイメージの多くは、Caltech の Cars 1999 データ セットおよび Cars 2001 データ セットからのものです。Pietro Perona 氏によって作成されたもので、許可を得て使用しています。各イメージには、1 または 2 個のラベル付けされた車両インスタンスが含まれています。小さなデータセットは Faster R-CNN の学習手順を調べるうえで役立ちますが、実際にロバストな検出器に学習させるにはより多くのラベル付けされたイメージが必要になります。車両のイメージを解凍し、車両のグラウンド トゥルース データを読み込みます。
unzip vehicleDatasetImages.zip data = load("vehicleDatasetGroundTruth.mat"); vehicleDataset = data.vehicleDataset;
車両データは 2 列の table に保存されています。1 列目にはイメージ ファイルのパスが含まれ、2 列目には車両の境界ボックスが含まれています。
データセットは学習、検証、テスト用のセットに分割します。データの 60% を学習用に、10% を検証用に、残りを学習済みの検出器のテスト用に選択します。
rng(0) shuffledIndices = randperm(height(vehicleDataset)); idx = floor(0.6 * height(vehicleDataset)); trainingIdx = 1:idx; trainingDataTbl = vehicleDataset(shuffledIndices(trainingIdx),:); validationIdx = idx+1 : idx + 1 + floor(0.1 * length(shuffledIndices) ); validationDataTbl = vehicleDataset(shuffledIndices(validationIdx),:); testIdx = validationIdx(end)+1 : length(shuffledIndices); testDataTbl = vehicleDataset(shuffledIndices(testIdx),:);
imageDatastore および boxLabelDatastore を使用して、学習および評価中にイメージとラベル データを読み込むデータストアを作成します。
imdsTrain = imageDatastore(trainingDataTbl{:,"imageFilename"});
bldsTrain = boxLabelDatastore(trainingDataTbl(:,"vehicle"));
imdsValidation = imageDatastore(validationDataTbl{:,"imageFilename"});
bldsValidation = boxLabelDatastore(validationDataTbl(:,"vehicle"));
imdsTest = imageDatastore(testDataTbl{:,"imageFilename"});
bldsTest = boxLabelDatastore(testDataTbl(:,"vehicle"));イメージ データストアとボックス ラベル データストアを組み合わせます。
trainingData = combine(imdsTrain,bldsTrain); validationData = combine(imdsValidation,bldsValidation); testData = combine(imdsTest,bldsTest);
学習イメージとボックス ラベルのうちの 1 つを表示します。
data = read(trainingData);
I = data{1};
bbox = data{2};
annotatedImage = insertShape(I,"rectangle",bbox);
annotatedImage = imresize(annotatedImage,2);
figure
imshow(annotatedImage)
Faster R-CNN 検出ネットワークの作成
Faster R-CNN オブジェクト検出ネットワークは、特徴抽出ネットワークと、その後に続く 2 つのサブネットワークによって構成されます。通常、特徴抽出ネットワークは、ResNet-50 や Inception v3 などの事前学習済みの CNN です。特徴抽出ネットワークの後に続く 1 つ目のサブネットワークは、オブジェクト提案 (オブジェクトが存在する可能性が高いイメージ内の領域) を生成するよう学習させた領域提案ネットワーク (RPN) です。2 つ目のサブネットワークは、各オブジェクト提案の実際のクラスを予測するように学習しています。
通常、特徴抽出ネットワークは事前学習済みの CNN です (詳細については事前学習済みの深層ニューラル ネットワーク (Deep Learning Toolbox)を参照)。この例では特徴抽出に ResNet-50 を使用します。用途の要件によって、MobileNet v2 や ResNet-18 など、その他の事前学習済みのネットワークも使用できます。
fasterRCNNLayers を使用して、事前学習済みの特徴抽出ネットワークが自動的に指定された Faster R-CNN ネットワークを作成します。fasterRCNNLayers では Faster R-CNN ネットワークをパラメーター化する以下の複数の入力を指定する必要があります。
ネットワーク入力サイズ
アンカー ボックス
特徴抽出ネットワーク
最初に、ネットワーク入力サイズを指定します。ネットワーク入力サイズを選択する際には、ネットワーク自体の実行に必要な最小サイズ、学習イメージのサイズ、および選択したサイズでデータを処理することによって発生する計算コストを考慮します。可能な場合、学習イメージのサイズに近く、ネットワークに必要な入力サイズより大きいネットワーク入力サイズを選択します。例の実行にかかる計算コストを削減するには、ネットワーク入力サイズをネットワークの実行に必要な最小サイズである [224 224 3] に指定します。
inputSize = [224 224 3];
この例で使用される学習イメージは 224 行 224 列より大きいさまざまなサイズを持つため、学習前の前処理手順でイメージのサイズを変更しなければなりません。
次に、estimateAnchorBoxes を使用して、学習データ内のオブジェクトのサイズに基づいてアンカー ボックスを推定します。学習前のイメージのサイズ変更を考慮するには、アンカー ボックスを推定する学習データのサイズを変更します。transform を使用して学習データの前処理を行い、アンカー ボックスの数を定義してアンカー ボックスを推定します。
preprocessedTrainingData = transform(trainingData, @(data)preprocessData(data,inputSize)); numAnchors = 3; anchorBoxes = estimateAnchorBoxes(preprocessedTrainingData,numAnchors)
anchorBoxes = 3×2
38 29
150 125
80 77
アンカー ボックスの選択の詳細については、学習データからのアンカー ボックスの推定 (Computer Vision Toolbox™) およびアンカー ボックスによるオブジェクトの検出を参照してください。
次に、resnet50 を使用して事前学習済みの ResNet-50 モデルを読み込みます。
featureExtractionNetwork = resnet50;
特徴抽出層として "activation_40_relu" を選択します。この特徴抽出層は、係数 16 でダウンサンプリングされる特徴マップを出力します。このダウンサンプリングの量は、空間分解能と抽出される特徴の強度との適切なトレードオフです (ネットワークでさらに抽出された特徴により、より強力なイメージの特徴が符号化されますが、空間分解能は低下します)。最適な特徴抽出層を選択するには経験的解析が必要です。analyzeNetwork を使用すると、ネットワーク内に存在する可能性がある他の特徴抽出層の名前を検索できます。
featureLayer = "activation_40_relu";検出するクラスの数を定義します。
numClasses = width(vehicleDataset)-1;
Faster R-CNN オブジェクト検出ネットワークを作成します。
lgraph = fasterRCNNLayers(inputSize,numClasses,anchorBoxes,featureExtractionNetwork,featureLayer);
Deep Learning Toolbox™ から analyzeNetwork またはディープ ネットワーク デザイナーを使用してネットワークを可視化できます。
Faster R-CNN ネットワーク アーキテクチャをより詳細に制御する必要がある場合は、ディープ ネットワーク デザイナーを使用して Faster R-CNN 検出ネットワークを手動で設計します。詳細については、R-CNN、Fast R-CNN および Faster R-CNN 入門を参照してください。
データ拡張
データ拡張は、学習中に元のデータをランダムに変換してネットワークの精度を高めるために使用されます。データ拡張を使用すると、ラベル付き学習サンプルの数を実際に増やさずに、学習データをさらに多様化させることができます。
transform を使用して、イメージと関連するボックス ラベルを水平方向にランダムに反転させることによって学習データを拡張します。データ拡張は、テスト データと検証データには適用されないことに注意してください。理想的には、テスト データと検証データは元のデータを代表するもので、バイアスのない評価を行うために変更なしで使用されます。
augmentedTrainingData = transform(trainingData,@augmentData);
同じイメージを複数回読み取り、拡張された学習データを表示します。
augmentedData = cell(4,1); for k = 1:4 data = read(augmentedTrainingData); augmentedData{k} = insertShape(data{1},"rectangle",data{2}); reset(augmentedTrainingData); end figure montage(augmentedData,BorderSize=10)

学習データの前処理
拡張された学習データと検証データを前処理して学習用に準備します。
trainingData = transform(augmentedTrainingData,@(data)preprocessData(data,inputSize)); validationData = transform(validationData,@(data)preprocessData(data,inputSize));
前処理済みのデータを読み取ります。
data = read(trainingData);
イメージとボックスの境界ボックスを表示します。
I = data{1};
bbox = data{2};
annotatedImage = insertShape(I,"rectangle",bbox);
annotatedImage = imresize(annotatedImage,2);
figure
imshow(annotatedImage)
Faster R-CNN の学習
trainingOptions を使用してネットワーク学習オプションを指定します。"ValidationData" を前処理済みの検証データに設定します。"CheckpointPath" を一時的な場所に設定します。これにより、学習プロセス中に部分的に学習させた検出器を保存できます。停電やシステム障害などで学習が中断された場合に、保存したチェックポイントから学習を再開できます。
options = trainingOptions("sgdm",... MaxEpochs=10,... MiniBatchSize=2,... InitialLearnRate=1e-3,... CheckpointPath=tempdir,... ValidationData=validationData);
doTraining が true の場合、trainFasterRCNNObjectDetector を使用して Faster R-CNN オブジェクト検出器に学習させます。そうでない場合は、事前学習済みのネットワークを読み込みます。
if doTraining % Train the Faster R-CNN detector. % * Adjust NegativeOverlapRange and PositiveOverlapRange to ensure % that training samples tightly overlap with ground truth. [detector, info] = trainFasterRCNNObjectDetector(trainingData,lgraph,options, ... NegativeOverlapRange=[0 0.3], ... PositiveOverlapRange=[0.6 1]); else % Load pretrained detector for the example. pretrained = load("fasterRCNNResNet50EndToEndVehicleExample.mat"); detector = pretrained.detector; end
この例は、12 GB メモリ搭載の Nvidia(TM) Titan X GPU で検証済みです。ネットワークの学習には約 20 分かかりました。学習時間は使用するハードウェアによって異なります。
簡単なチェックとして、1 つのテスト イメージに対して検出器を実行します。イメージのサイズを変更して学習イメージと同じサイズにします。
I = imread(testDataTbl.imageFilename{3});
I = imresize(I,inputSize(1:2));
[bboxes,scores] = detect(detector,I);結果を表示します。
I = insertObjectAnnotation(I,"rectangle",bboxes,scores);
figure
imshow(I)
テスト セットを使用した検出器の評価
大規模なイメージ セットで学習済みのオブジェクト検出器を評価し、パフォーマンスを測定します。Computer Vision Toolbox™ には、平均適合率や対数平均ミス率などの一般的なメトリクスを測定するためのオブジェクト検出器評価関数 (evaluateObjectDetection) が用意されています。この例では、平均適合率メトリクスを使用してパフォーマンスを評価します。平均適合率は、検出器が正しい分類を実行できること (適合率) と検出器がすべての関連オブジェクトを検出できること (再現率) を示す単一の数値です。
学習データと同じ前処理変換をテスト データに適用します。
testData = transform(testData,@(data)preprocessData(data,inputSize));
すべてのテスト イメージに対して検出器を実行します。できるだけ多くのオブジェクトを検出するには、検出しきい値を低い値に設定します。これは、検出器の適合率を、再現率の値の全範囲にわたって評価するのに役立ちます。
detectionResults = detect(detector,testData,... Threshold=0.2,... MiniBatchSize=4);
平均適合率メトリクスを使用してオブジェクト検出器を評価します。
metrics = evaluateObjectDetection(detectionResults,testData); [precision,recall] = precisionRecall(metrics,ClassName="vehicle"); AP = averagePrecision(metrics,ClassName="vehicle");
適合率/再現率 (PR) の曲線は、さまざまなレベルの再現率における検出器の適合率を示しています。すべてのレベルの再現率で適合率が 1 になるのが理想的です。より多くのデータを使用すると平均適合率を向上できますが、学習に必要な時間が長くなる場合があります。PR 曲線をプロットします。
figure
plot(recall{:},precision{:})
xlabel("Recall")
ylabel("Precision")
grid on
title(sprintf("Average Precision = %.2f", AP))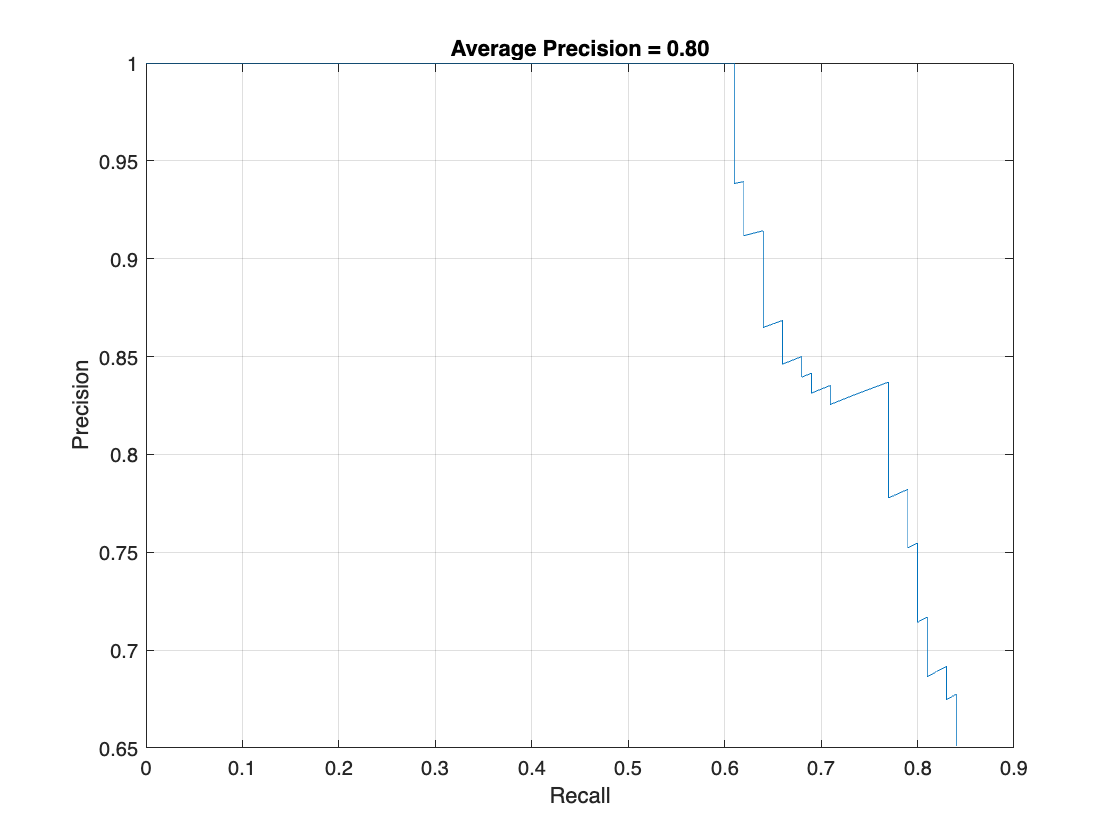
サポート関数
function data = augmentData(data) % Randomly flip images and bounding boxes horizontally. tform = randomAffine2d("XReflection",true); sz = size(data{1}); rout = affineOutputView(sz,tform); data{1} = imwarp(data{1},tform,"OutputView",rout); % Sanitize boxes, if needed. This helper function is attached as a % supporting file. Open the example in MATLAB to open this function. data{2} = helperSanitizeBoxes(data{2}); % Warp boxes. data{2} = bboxwarp(data{2},tform,rout); end function data = preprocessData(data,targetSize) % Resize image and bounding boxes to targetSize. sz = size(data{1},[1 2]); scale = targetSize(1:2)./sz; data{1} = imresize(data{1},targetSize(1:2)); % Sanitize boxes, if needed. This helper function is attached as a % supporting file. Open the example in MATLAB to open this function. data{2} = helperSanitizeBoxes(data{2}); % Resize boxes. data{2} = bboxresize(data{2},scale); end
参考文献
[1] Ren, S., K. He, R. Gershick, and J. Sun. "Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks." IEEE Transactions of Pattern Analysis and Machine Intelligence. Vol. 39, Issue 6, June 2017, pp. 1137-1149.
[2] Girshick, R., J. Donahue, T. Darrell, and J. Malik. "Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation." Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, June 2014, pp. 580-587.
[3] Girshick, R. "Fast R-CNN." Proceedings of the 2015 IEEE International Conference on Computer Vision. Santiago, Chile, Dec. 2015, pp. 1440-1448.
[4] Zitnick, C. L., and P. Dollar. "Edge Boxes: Locating Object Proposals from Edges." European Conference on Computer Vision. Zurich, Switzerland, Sept. 2014, pp. 391-405.
[5] Uijlings, J. R. R., K. E. A. van de Sande, T. Gevers, and A. W. M. Smeulders. "Selective Search for Object Recognition." International Journal of Computer Vision. Vol. 104, Number 2, Sept. 2013, pp. 154-171.
参考
trainingOptions (Deep Learning Toolbox) | fasterRCNNObjectDetector | trainFasterRCNNObjectDetector | detect | insertObjectAnnotation | evaluateObjectDetection
トピック
- 深層学習を使用したオブジェクト検出入門
- オブジェクト検出器の選択
- R-CNN 深層学習を使用したオブジェクト検出器の学習
- MATLAB による深層学習 (Deep Learning Toolbox)