このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
fit
クエリ点のシャープレイ値の計算
説明
newExplainer = fit(explainer,queryPoints)queryPoints) のシャープレイ値を計算し、計算したシャープレイ値を newExplainer の Shapley プロパティに格納します。shapley オブジェクト explainer には、機械学習モデルとシャープレイ値の計算オプションが格納されています。
fit は、いつ explainer を作成するかを指定する、シャープレイ値計算オプションを使用します。このオプションは、関数 fit の名前と値の引数を使用して変更できます。この関数は、新しく計算したシャープレイ値を含む shapley オブジェクト newExplainer を返します。
newExplainer = fit(explainer,queryPoints,Name=Value)UseParallel=true と指定してシャープレイ値を並列計算します。
例
回帰モデルの学習を行い、shapley オブジェクトを作成します。shapley オブジェクトを作成するときに、クエリ点を指定しなかった場合、シャープレイ値は計算されません。オブジェクト関数 fit を使用して、指定したクエリ点のシャープレイ値を計算します。次に、オブジェクト関数 plot を使用して、シャープレイ値の棒グラフを作成します。
carbig データ セットを読み込みます。このデータ セットには、1970 年代と 1980 年代初期に製造された自動車の測定値が格納されています。
load carbigAcceleration、Cylinders などの予測子変数と応答変数 MPG が格納された table を作成します。
tbl = table(Acceleration,Cylinders,Displacement, ...
Horsepower,Model_Year,Weight,MPG);学習セットの欠損値を削除すると、メモリ消費量を減らして関数 fitrkernel の学習速度を向上させることができます。tbl の欠損値を削除します。
tbl = rmmissing(tbl);
関数fitrkernelを使用して MPG の blackbox モデルの学習を行います。変数 Cylinders と Model_Year をカテゴリカル予測子として指定します。残りの予測子を標準化します。
rng("default") % For reproducibility mdl = fitrkernel(tbl,"MPG",CategoricalPredictors=[2 5], ... Standardize=true);
shapley オブジェクトを作成します。mdl には学習データが含まれないため、データ セット tbl を指定します。
explainer = shapley(mdl,tbl)
explainer =
BlackboxModel: [1×1 RegressionKernel]
QueryPoints: []
BlackboxFitted: []
Shapley: []
X: [392×7 table]
CategoricalPredictors: [2 5]
Method: "interventional-kernel"
Intercept: 23.2474
NumSubsets: 64
explainer は、学習データ tbl を X プロパティに格納します。既定では、shapley は X のデータから 100 個の観測値をサブサンプリングし、それらのインデックスを SampledObservationIndices プロパティに格納します。
tbl の最初の観測値についてすべての予測子変数のシャープレイ値を計算します。fit オブジェクト関数は、X のすべてではなく、抽出された観測値を使用してシャープレイ値を計算します。
queryPoint = tbl(1,:)
queryPoint=1×7 table
Acceleration Cylinders Displacement Horsepower Model_Year Weight MPG
____________ _________ ____________ __________ __________ ______ ___
12 8 307 130 70 3504 18
explainer = fit(explainer,queryPoint);
回帰モデルの場合、fit は予測応答を使用してシャープレイ値を計算し、それらを shapley オブジェクトの Shapley プロパティに格納します。Shapley プロパティの値を表示します。
explainer.Shapley
ans=6×2 table
Predictor Value
______________ ________
"Acceleration" -0.33821
"Cylinders" -0.97631
"Displacement" -1.1425
"Horsepower" -0.62927
"Model_Year" -0.17268
"Weight" -0.87595
関数 plot を使用して、クエリ点のシャープレイ値をプロットします。
plot(explainer)
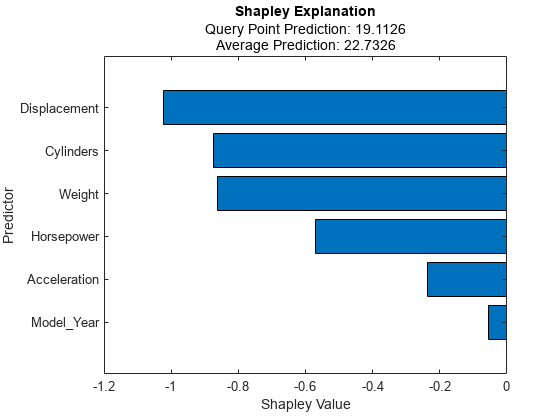
横棒グラフは、絶対値で並べ替えられた、すべての変数のシャープレイ値を示します。各シャープレイ値は、クエリ点についての予測に関して対応する変数が原因で生じた平均からの偏差を説明します。
分類モデルの学習を行い、shapley オブジェクトを作成します。その後、2 つのクエリ点のシャープレイ値を計算します。
CreditRating_Historical データ セットを読み込みます。データ セットには、顧客 ID、顧客の財務比率、業種ラベル、および信用格付けが格納されています。
tbl = readtable("CreditRating_Historical.dat");関数fitcecocを使用して、信用格付けの blackbox モデルに学習させます。tbl 内の 2 ~ 7 列目の変数を予測子変数として使用します。
blackbox = fitcecoc(tbl,"Rating", ... PredictorNames=tbl.Properties.VariableNames(2:7), ... CategoricalPredictors="Industry");
blackbox モデルを使用して、shapley オブジェクトを作成します。tbl から 1000 個の観測値を抽出してシャープレイ値を計算するように指定します。Kernel SHAP アルゴリズムの拡張機能の使用を指定します。
rng("default") % For reproducibility explainer = shapley(blackbox,tbl,Method="conditional", ... NumObservationsToSample=1000);
真の信用格付け値がそれぞれ AAA および BB となる 2 つのクエリ点を見つけます。
sampleTbl = explainer.X(explainer.SampledObservationIndices,:); queryPoints(1,:) = sampleTbl(find(strcmp(sampleTbl.Rating,"AAA"),1),:); queryPoints(2,:) = sampleTbl(find(strcmp(sampleTbl.Rating,"BB"),1),:)
queryPoints=2×8 table
ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ _____ _____ _______ ________ _____ ________ _______
39364 0.61 0.694 0.122 5.409 0.359 3 {'AAA'}
44610 0.254 0.226 0.064 0.779 0.254 5 {'BB' }
最初のクエリ点についてのシャープレイ値を計算してプロットします。
explainer1 = fit(explainer,queryPoints(1,:)); plot(explainer1)
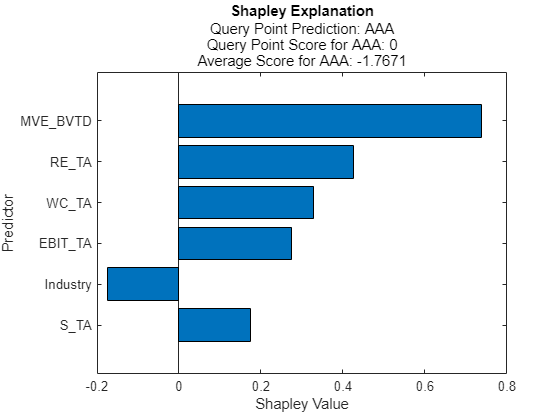
2 番目のクエリ点についてのシャープレイ値を計算してプロットします。
explainer2 = fit(explainer,queryPoints(2,:)); plot(explainer2)
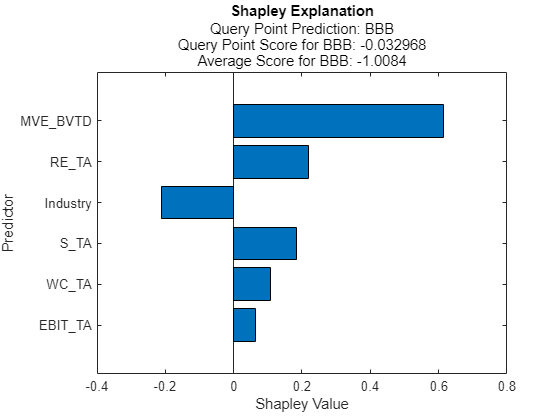
2 番目のクエリ点に関する実際の格付けは BB ですが、予測された格付けは BBB です。プロットには、予測された格付けのシャープレイ値が表示されます。
explainer1 と explainer2 にはそれぞれ、最初のクエリ点と 2 番目のクエリ点についてのシャープレイ値が含まれています。
回帰モデルの学習を行い、shapley オブジェクトを作成します。オブジェクト関数 fit を使用して、指定したクエリ点のシャープレイ値を計算します。その後、オブジェクト関数 swarmchart を使用して複数のクエリ点のシャープレイ値をプロットします。
carbig データ セットを読み込みます。このデータ セットには、1970 年代と 1980 年代初期に製造された自動車の測定値が格納されています。
load carbigAcceleration、Cylinders などの予測子変数と応答変数 MPG が格納された table を作成します。
tbl = table(Acceleration,Cylinders,Displacement, ...
Horsepower,Model_Year,Weight,MPG);学習セットの欠損値を削除すると、メモリ消費量が減り、関数 fitrkernel の学習速度の向上に役立ちます。tbl の欠損値を削除します。
tbl = rmmissing(tbl);
関数 fitrkernel を使用して MPG の blackbox モデルに学習させます。変数 Cylinders と Model_Year をカテゴリカル予測子として指定します。残りの予測子を標準化します。
rng("default") % For reproducibility mdl = fitrkernel(tbl,"MPG",CategoricalPredictors=[2 5], ... Standardize=true);
shapley オブジェクトを作成します。mdl には学習データが含まれていないため、データ セット tbl を指定します。
explainer = shapley(mdl,tbl)
explainer =
BlackboxModel: [1×1 RegressionKernel]
QueryPoints: []
BlackboxFitted: []
Shapley: []
X: [392×7 table]
CategoricalPredictors: [2 5]
Method: "interventional-kernel"
Intercept: 23.2474
NumSubsets: 64
explainer は、学習データ tbl を X プロパティに格納します。既定では、shapley は X のデータから 100 個の観測値をサブサンプリングし、それらのインデックスを SampledObservationIndices プロパティに格納します。
tbl のすべての観測値のシャープレイ値を計算します。計算を高速化するために、fit オブジェクト関数は、X のすべてではなく、抽出された観測値を使用してシャープレイ値を計算します。Parallel Computing Toolbox™ のライセンスがある場合は、名前と値の引数 UseParallel を使用して計算時間をさらに短縮できます。
explainer = fit(explainer,tbl,UseParallel=true);
回帰モデルの場合、fit は予測応答を使用してシャープレイ値を計算し、それらを shapley オブジェクトの Shapley プロパティに格納します。explainer に複数のクエリ点のシャープレイ値が格納されているため、代わりに平均絶対シャープレイ値を表示します。
explainer.MeanAbsoluteShapley
ans=6×2 table
Predictor Value
______________ _______
"Acceleration" 0.5678
"Cylinders" 0.96799
"Displacement" 0.79668
"Horsepower" 0.78681
"Model_Year" 0.86258
"Weight" 0.987
それぞれの予測子について、すべてのクエリ点で平均化したシャープレイ値の絶対値が平均絶対シャープレイ値になります。予測子 Cylinders の平均絶対シャープレイ値が最も大きく、予測子 Acceleration の平均絶対シャープレイ値が最も小さくなっています。
オブジェクト関数 swarmchart を使用してシャープレイ値を可視化します。"copper" カラーマップを使用するように指定します。
swarmchart(explainer,ColorMap="copper")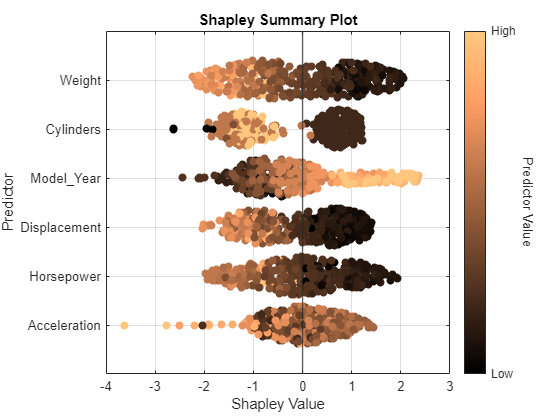
それぞれの予測子について、クエリ点のシャープレイ値が関数によって表示されます。対応する粒子群チャートにシャープレイ値の分布が表示されます。予測子の順序は、平均絶対シャープレイ値を使用して関数で決定されます。
Weight の値が小さいクエリ点は、シャープレイ値が大きい正の値になっているように見えます。つまり、それらのクエリ点については、予測子 Weight は MPG の予測される値の平均からの差が大きくなるのに寄与しています。同様に、Weight の値が大きいクエリ点は、シャープレイ値が大きい負の値になっているように見えます。つまり、それらのクエリ点については、予測子 Weight は MPG の予測される値の平均からの差が小さくなるのに寄与しています。これらの結果は、自動車の重量は MPG の値と逆の相関があるという考え方に一致しています。