plot
棒グラフを使用したシャープレイ値のプロット
説明
plot( は、explainer)shapley オブジェクト explainer のシャープレイ値を使用して横棒グラフを作成します。
explainerにクエリ点が 1 つだけ格納されている場合は、棒グラフにシャープレイ値が表示されます。これらの値はオブジェクトのShapleyプロパティに格納されています。各バーは、クエリ点 (explainer.) についての blackbox モデル (QueryPointsexplainer.) 内の各特徴量 (予測子) のシャープレイ値を示します。BlackboxModelexplainerにクエリ点が複数格納されている場合は、棒グラフに平均絶対シャープレイ値が表示されます。これらの値はオブジェクトのMeanAbsoluteShapleyプロパティに格納されています。それぞれの予測子 (explainer.BlackboxModelが分類モデルの場合はそれぞれのクラス) について、explainer.QueryPointsのすべてのクエリ点で平均化したシャープレイ値の絶対値が平均絶対シャープレイ値になります。 (R2024a 以降)
plot( では、1 つ以上の名前と値の引数を使用して追加オプションを指定します。たとえば、explainer,Name=Value)NumImportantPredictors=5 と指定すると、絶対シャープレイ値 (クエリ点が 1 つの場合) または平均絶対シャープレイ値 (クエリ点が複数の場合) が大きい上位 5 つの特徴量のシャープレイ値がプロットされます。
plot( は、ターゲットの座標軸 ax,___)ax にプロットを表示します。ax は、前の任意の構文で最初の引数として指定します。 (R2023b 以降)
b = plot(___)Bar オブジェクトまたは Bar オブジェクトの配列を返します。b は、オブジェクトの作成後にそのプロパティ (Bar のプロパティ) をクエリまたは変更するのに使用します。
例
分類モデルの学習を行い、shapley オブジェクトを作成します。次に、オブジェクト関数 plot を使用して、シャープレイ値をプロットします。
CreditRating_Historical データ セットを読み込みます。データ セットには、顧客 ID、顧客の財務比率、業種ラベル、および信用格付けが格納されています。
tbl = readtable("CreditRating_Historical.dat");table の最初の 3 行を表示します。
head(tbl,3)
ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ _____ _____ _______ ________ _____ ________ ______
62394 0.013 0.104 0.036 0.447 0.142 3 {'BB'}
48608 0.232 0.335 0.062 1.969 0.281 8 {'A' }
42444 0.311 0.367 0.074 1.935 0.366 1 {'A' }
関数fitcecocを使用して、信用格付けの blackbox モデルに学習させます。tbl 内の 2 ~ 7 列目の変数を予測子変数として使用します。クラス名を指定してクラスの順序を設定することが推奨されます。
blackbox = fitcecoc(tbl,"Rating", ... PredictorNames=tbl.Properties.VariableNames(2:7), ... CategoricalPredictors="Industry", ... ClassNames={'AAA','AA','A','BBB','BB','B','CCC'});
最後の観測値の予測を説明する shapley オブジェクトを作成します。計算を高速にするために、shapley は tbl の予測子データから 100 個の観測値をサブサンプリングしてシャープレイ値を計算します。
queryPoint = tbl(end,:)
queryPoint=1×8 table
ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ _____ _____ _______ ________ ____ ________ ______
73104 0.239 0.463 0.065 2.924 0.34 2 {'AA'}
explainer = shapley(blackbox,tbl,QueryPoints=queryPoint);
分類モデルの場合、shapley は各クラスの予測クラス スコアを使用してシャープレイ値を計算します。Shapley プロパティの値を表示します。
explainer.Shapley
ans=6×8 table
Predictor AAA AA A BBB BB B CCC
__________ _________ __________ __________ __________ ___________ __________ __________
"WC_TA" 0.061172 0.023988 0.0085073 -0.0019268 -0.03895 -0.056012 -0.051658
"RE_TA" 0.16878 0.089521 0.048741 -0.021252 -0.10389 -0.22968 -0.30796
"EBIT_TA" 0.0013159 0.00051165 0.00039115 1.1425e-05 -0.00090913 -0.0016812 -0.0014235
"MVE_BVTD" 1.351 1.271 0.51796 -0.27612 -0.86555 -1.0915 -0.8458
"S_TA" -0.012304 -0.0083217 0.00019836 -0.0026384 -2.257e-05 0.0017866 -0.0026664
"Industry" -0.11427 -0.053759 0.0058104 0.090519 0.11176 0.13811 0.18671
Shapley プロパティには、クラスごとにすべての特徴量のシャープレイ値が格納されています。
関数 plot を使用して予測クラスのシャープレイ値をプロットします。
plot(explainer)
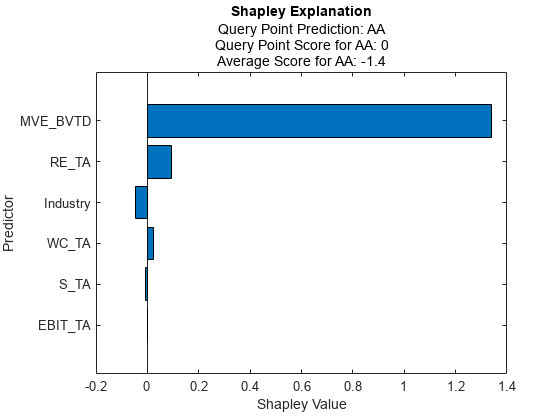
横棒グラフは、絶対値で並べ替えられた、すべての変数のシャープレイ値を示します。各シャープレイ値は、クエリ点についてのスコアに関して対応する変数が原因で生じた予測クラスの平均スコアからの偏差を説明します。
explainer.BlackboxModel ですべてのクラス名を指定して、すべてのクラスのシャープレイ値をプロットします。
plot(explainer,ClassNames=explainer.BlackboxModel.ClassNames)
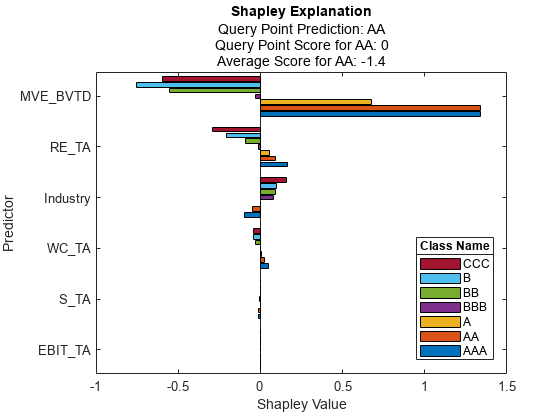
回帰モデルの学習を行い、shapley オブジェクトを作成します。オブジェクト関数 fit を使用して、指定したクエリ点のシャープレイ値を計算します。次に、オブジェクト関数 plot を使用して、予測子のシャープレイ値をプロットします。関数 plot を呼び出すときにプロットする重要な予測子の数を指定します。
carbig データ セットを読み込みます。このデータ セットには、1970 年代と 1980 年代初期に製造された自動車の測定値が格納されています。
load carbigAcceleration、Cylinders などの予測子変数と応答変数 MPG が格納された table を作成します。
tbl = table(Acceleration,Cylinders,Displacement, ...
Horsepower,Model_Year,Weight,MPG);学習セットの欠損値を削除すると、メモリ消費量を減らして関数 fitrkernel の学習速度を向上させることができます。tbl の欠損値を削除します。
tbl = rmmissing(tbl);
関数fitrkernelを使用して MPG の blackbox モデルの学習を行います。変数 Cylinders と Model_Year をカテゴリカル予測子として指定します。残りの予測子を標準化します。
rng("default") % For reproducibility mdl = fitrkernel(tbl,"MPG",CategoricalPredictors=[2 5], ... Standardize=true);
shapley オブジェクトを作成します。mdl には学習データが含まれていないため、データ セット tbl を指定します。
explainer = shapley(mdl,tbl)
explainer =
BlackboxModel: [1×1 RegressionKernel]
QueryPoints: []
BlackboxFitted: []
Shapley: []
X: [392×7 table]
CategoricalPredictors: [2 5]
Method: "interventional-kernel"
Intercept: 23.2474
NumSubsets: 64
explainer は、学習データ tbl を X プロパティに格納します。既定では、shapley は X のデータから 100 個の観測値をサブサンプリングし、それらのインデックスを SampledObservationIndices プロパティに格納します。
tbl の最初の観測値についてすべての予測子変数のシャープレイ値を計算します。計算を高速化するために、fit オブジェクト関数は、X のすべてではなく、抽出された観測値を使用してシャープレイ値を計算します。
queryPoint = tbl(1,:)
queryPoint=1×7 table
Acceleration Cylinders Displacement Horsepower Model_Year Weight MPG
____________ _________ ____________ __________ __________ ______ ___
12 8 307 130 70 3504 18
explainer = fit(explainer,queryPoint);
回帰モデルの場合、fit は予測応答を使用してシャープレイ値を計算し、それらを shapley オブジェクトの Shapley プロパティに格納します。Shapley プロパティの値を表示します。
explainer.Shapley
ans=6×2 table
Predictor Value
______________ ________
"Acceleration" -0.33821
"Cylinders" -0.97631
"Displacement" -1.1425
"Horsepower" -0.62927
"Model_Year" -0.17268
"Weight" -0.87595
関数 plot を使用して、クエリ点のシャープレイ値をプロットします。予測応答について上位 5 つの重要な予測子のみをプロットするように指定します。
plot(explainer,NumImportantPredictors=5)

横棒グラフは、絶対値で並べ替えられた、5 つの最も重要な予測子のシャープレイ値を示します。各シャープレイ値は、クエリ点についての予測に関して対応する変数が原因で生じた平均からの偏差を説明します。
分類モデルの学習を行い、shapley オブジェクトを作成します。オブジェクト関数 plot を使用して、複数のクエリ点の平均絶対シャープレイ値をプロットします。その後、いずれかのクエリ点のシャープレイ値をプロットします。
CreditRating_Historical データ セットを読み込みます。データ セットには、顧客 ID、顧客の財務比率、業種ラベル、および信用格付けが格納されています。
tbl = readtable("CreditRating_Historical.dat");table の最初の 3 行を表示します。
head(tbl,3)
ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ _____ _____ _______ ________ _____ ________ ______
62394 0.013 0.104 0.036 0.447 0.142 3 {'BB'}
48608 0.232 0.335 0.062 1.969 0.281 8 {'A' }
42444 0.311 0.367 0.074 1.935 0.366 1 {'A' }
関数 fitcecoc を使用して、信用格付けの blackbox モデルに学習させます。tbl 内の 2 ~ 7 列目の変数を予測子変数として使用します。クラス名を指定してクラスの順序を設定することが推奨されます。
blackbox = fitcecoc(tbl,"Rating", ... PredictorNames=tbl.Properties.VariableNames(2:7), ... CategoricalPredictors="Industry", ... ClassNames={'AAA','AA','A','BBB','BB','B','CCC'});
複数のクエリ点の予測を説明する shapley オブジェクトを作成します。計算を高速にするために、shapley は blackbox の予測子データから 100 個の観測値をサブサンプリングしてシャープレイ値を計算します。fit オブジェクト関数の呼び出しで、抽出された観測値をクエリ点として指定します。
rng("default") % For reproducibility explainer = shapley(blackbox); queryPoints = explainer.X(explainer.SampledObservationIndices,:); explainer = fit(explainer,queryPoints);
分類モデルの場合、fit 関数は各クラスの予測クラス スコアを使用してシャープレイ値を計算します。複数のクエリ点を指定すると、各予測子と各クラスについての平均絶対シャープレイ値が関数で計算されます。
explainer.MeanAbsoluteShapley
ans=6×8 table
Predictor AAA AA A BBB BB B CCC
__________ _________ __________ _________ _________ _________ _________ _________
"WC_TA" 0.055977 0.034453 0.027338 0.023902 0.036098 0.054763 0.054931
"RE_TA" 0.12468 0.10314 0.10787 0.087013 0.090298 0.17123 0.2552
"EBIT_TA" 0.0015598 0.00095166 0.0011936 0.0010499 0.0010047 0.0018817 0.0017712
"MVE_BVTD" 0.84966 0.68785 0.66198 0.94501 1.3672 1.5715 1.2161
"S_TA" 0.025009 0.0095605 0.010606 0.014469 0.0017235 0.0075275 0.012529
"Industry" 0.076169 0.085926 0.063854 0.046528 0.053801 0.11261 0.11829
たとえば、explainer.MeanAbsoluteShapley.AAA(1) の値は、予測子 WC_TA とクラス AAA の絶対シャープレイ値の queryPoints のすべての観測値での平均になります。
explainer.MeanAbsoluteShapley.AAA(1)
ans = 0.0560
オブジェクト関数 plot を使用して、平均絶対シャープレイ値をプロットします。
plot(explainer)
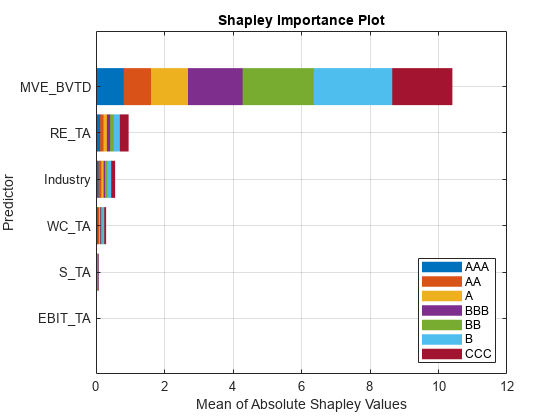
それぞれのクラスについて、予測子 MVE_BVTD の平均絶対シャープレイ値が最も大きくなっています。
最初のクエリ点を選択し、そのクエリ点についてのクラス予測を調べます。
queryPoint = explainer.QueryPoints(1,:)
queryPoint=1×6 table
WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry
_____ _____ _______ ________ _____ ________
0.197 0.471 0.067 2.304 0.602 1
queryPointPrediction = explainer.BlackboxFitted(1)
queryPointPrediction = 1×1 cell array
{'A'}
名前と値の引数 QueryPointIndices を使用して、クエリ点のシャープレイ値をプロットします。クエリ点の予測クラス (A) の色と一致するようにバーの色を変更します。
b = plot(explainer,QueryPointIndices=1); b.FaceColor = [0.9290 0.6940 0.1250];

このクエリ点について、予測子 MVE_BVTD は、クラス A の予測スコアの平均からの最大偏差を説明しています。