OneClassSVM
説明
外れ値の検出および新規性の検出に 1 クラス サポート ベクター マシン モデル オブジェクト OneClassSVM を使用します。
外れ値検出 (学習データ中の異常を検出) — 関数
ocsvmを使用して、学習データ中の異常を検出します。関数ocsvmは、OneClassSVMオブジェクトに学習させ、学習データの異常インジケーターおよびスコアを返します。新規性の検出 (汚染されていない学習データで新規のデータの異常を検出) — 汚染されていない学習データ (外れ値がないデータ) を
ocsvmに渡してOneClassSVMオブジェクトを作成し、このオブジェクトおよび新規データをオブジェクト関数isanomalyに渡して新規のデータの異常を検出します。関数isanomalyは、新規データの異常インジケーターおよびスコアを返します。
作成
関数 ocsvm を使用して OneClassSVM オブジェクトを作成します。
プロパティ
オブジェクト関数
isanomaly | 1 クラス サポート ベクター マシン (SVM) を使用したデータ中の異常の検出 |
incrementalLearner | Convert one-class SVM model to incremental learner |
gather | GPU からの Statistics and Machine Learning Toolbox オブジェクトのプロパティの収集 |
例
関数 ocsvm を使用して、外れ値 (学習データ中の異常) を検出します。
標本データ セット NYCHousing2015 を読み込みます。
load NYCHousing2015データ セットには、2015 年のニューヨーク市における不動産の売上に関する情報を持つ 10 の変数が含まれます。データ セットの概要を表示します。
summary(NYCHousing2015)
double
Values:
Min 1
Median 3
Max 5
NEIGHBORHOOD: 91446×1 cell array of character vectors
BUILDINGCLASSCATEGORY: 91446×1 cell array of character vectors
RESIDENTIALUNITS: 91446×1 double
Values:
Min 0
Median 1
Max 8759
COMMERCIALUNITS: 91446×1 double
Values:
Min 0
Median 0
Max 612
LANDSQUAREFEET: 91446×1 double
Values:
Min 0
Median 1700
Max 2.9306e+07
GROSSSQUAREFEET: 91446×1 double
Values:
Min 0
Median 1056
Max 8.9422e+06
YEARBUILT: 91446×1 double
Values:
Min 0
Median 1939
Max 2016
SALEPRICE: 91446×1 double
Values:
Min 0
Median 3.3333e+05
Max 4.1111e+09
SALEDATE: 91446×1 datetime
Values:
Min 01-Jan-2015
Median 09-Jul-2015
Max 31-Dec-2015
SALEDATE 列は datetime 配列です。ocsvm ではサポートされていません。datetime 値の月番号および日番号用の列を作成し、SALEDATE 列を削除します。
[~,NYCHousing2015.MM,NYCHousing2015.DD] = ymd(NYCHousing2015.SALEDATE); NYCHousing2015.SALEDATE = [];
NYCHousing2015 用に 1 クラス SVM モデルに学習させます。学習観測値に含まれている異常の比率を 0.1 に指定し、最初の変数 (BOROUGH) をカテゴリカル予測子として指定します。最初の変数は数値配列であるため、この変数をカテゴリカル変数として指定しない限り、ocsvm により連続変数であると仮定されます。また、予測子によってスケールが大きく異なるため、StandardizeData を true に指定して入力データを標準化します。ヒューリスティック手法を使用して適切なカーネル スケール パラメーターが選択されるように、KernelScale を "auto" に設定します。
rng("default") % For reproducibility [Mdl,tf,scores] = ocsvm(NYCHousing2015,ContaminationFraction=0.1, ... CategoricalPredictors=1,StandardizeData=true, ... KernelScale="auto");
Mdl は OneClassSVM オブジェクトです。ocsvm は、学習データ NYCHousing2015 の異常インジケーター (tf) および異常スコア (scores) も返します。
スコア値のヒストグラムをプロットします。指定した比率に対応するスコアのしきい値に垂直線を作成します。
histogram(scores) xline(Mdl.ScoreThreshold,"r-",["Threshold" Mdl.ScoreThreshold])
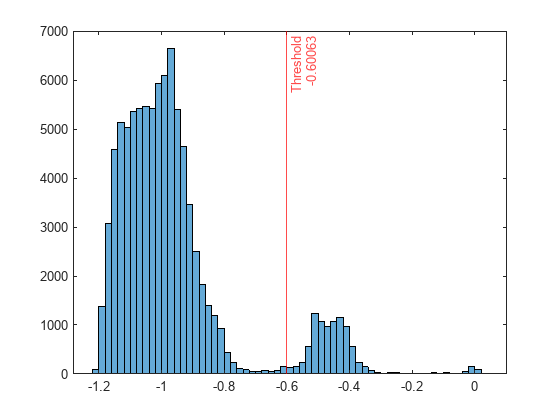
異なる汚染の比率 (たとえば 0.01) で異常を識別する場合は、新しい 1 クラス SVM モデルに学習させることができます。
rng("default") % For reproducibility [newMdl,newtf,scores] = ocsvm(NYCHousing2015, ... ContaminationFraction=0.01,CategoricalPredictors=1, ... KernelScale="auto");
異なるスコアのしきい値 (たとえば -0.7) で異常を識別する場合は、OneClassSVM オブジェクト、学習データ、および新しいしきい値を関数 isanomaly に渡せます。
[newtf,scores] = isanomaly(Mdl,NYCHousing2015,ScoreThreshold=-0.7);
汚染の比率またはスコアのしきい値を変更すると異常インジケーターのみが変更され、異常スコアは影響を受けないことに注意してください。したがって、ocsvm または isanomaly を使用して異常スコアを再度計算しない場合、既存のスコア値で新しい異常インジケーターを取得できます。
学習データ中の異常の比率を 0.01 に変更します。
newContaminationFraction = 0.01;
関数quantileを使用して、新しいスコアのしきい値を求めます。
newScoreThreshold = quantile(scores,1-newContaminationFraction)
newScoreThreshold = -0.3745
新しい異常インジケーターを取得します。
newtf = scores > newScoreThreshold;
関数 ocsvm を使用して、汚染されていない学習観測値用の OneClassSVM オブジェクトを作成します。次に、オブジェクトおよび新規データをオブジェクト関数 isanomaly に渡して、新規性 (新規データ中の異常) を検出します。
census1994.mat に保存されている 1994 年の国勢調査データを読み込みます。このデータ セットは、個人の年収が $50,000 を超えるかどうかを予測するための、米国勢調査局の人口統計データから構成されます。
load census1994census1994 には学習データ セット adultdata およびテスト データ セット adulttest が含まれています。
ocsvm は、欠損値のある観測値は使用しません。データ セットの欠損値を削除すると、メモリ消費が減って学習が高速化します。
adultdata = rmmissing(adultdata); adulttest = rmmissing(adulttest);
adultdata 用に 1 クラス SVM に学習させます。adultdata には外れ値が含まれていないと仮定します。StandardizeData を true に指定して入力データを標準化し、KernelScale を "auto" に設定して、関数でヒューリスティック手法を使用して適切なカーネル スケール パラメーターを選択できるようにします。
rng("default") % For reproducibility [Mdl,~,s] = ocsvm(adultdata,StandardizeData=true,KernelScale="auto");
Mdl は、OneClassSVM オブジェクトです。名前と値の引数 ContaminationFraction を 0 を超える値として指定していない場合、ocsvm はすべての学習観測値を正常な観測値として扱います。この関数によりスコアのしきい値が最大のスコア値に設定されます。しきい値を表示します。
Mdl.ScoreThreshold
ans = 0.0322
学習済みの 1 クラス SVM モデルを使用して、adulttest 内の異常を見つけます。モデルに学習させるときに StandardizeData=true を指定したため、関数 isanomaly は、Mu プロパティと Sigma プロパティに格納されている学習データの予測子の平均と標準偏差をそれぞれ使用して入力データを標準化します。
[tf_test,s_test] = isanomaly(Mdl,adulttest);
関数 isanomaly は、adulttest の異常インジケーター tf_test およびスコア s_test を返します。既定では、isanomaly はしきい値 (Mdl.ScoreThreshold) を超えるスコアをもつ観測値を異常として識別します。
異常スコア s および s_test のヒストグラムを作成します。異常スコアのしきい値に垂直線を作成します。
h1 = histogram(s,NumBins=50,Normalization="probability"); hold on h2 = histogram(s_test,h1.BinEdges,Normalization="probability"); xline(Mdl.ScoreThreshold,"r-",join(["Threshold" Mdl.ScoreThreshold])) h1.Parent.YScale = 'log'; h2.Parent.YScale = 'log'; legend("Training Data","Test Data",Location="north") hold off

テスト データ中にある異常の観測値のインデックスを表示します。
find(tf_test)
ans = 0×1 empty double column vector
テスト データの異常スコア分布は学習データの異常スコア分布と類似しているため、isanomaly は既定のしきい値でテスト データ中にある異常を検出しません。名前と値のペア ScoreThreshold を使用して、異なるしきい値を指定できます。例については、異常スコアのしきい値の指定を参照してください。