incrementalOneClassSVM
One-class support vector machine (SVM) model for incremental anomaly detection
Since R2023b
Description
The incrementalOneClassSVM function creates an
incrementalOneClassSVM model object, which represents a one-class SVM model for
incremental anomaly detection.
Unlike other Statistics and Machine Learning Toolbox™ model objects, incrementalOneClassSVM can be called directly. Also,
you can specify learning options, such as the mini-batch size for each learning cycle, the
learning rate, and whether to standardize the predictor data before fitting the model to data.
After you create an incrementalOneClassSVM object, it is prepared for incremental
learning (see Incremental Learning for Anomaly Detection).
incrementalOneClassSVM is best suited for incremental learning. For a traditional
approach to anomaly detection when all the data is provided in advance, see ocsvm.
Note
Incremental learning functions support only numeric input predictor data. You must
prepare an encoded version of categorical data to use incremental learning functions. Use
dummyvar to convert each categorical variable
to a dummy variable. For more details, see Dummy Variables.
Creation
You can create an incrementalOneClassSVM model object in several ways:
Call the function directly — Configure incremental learning options, or specify learner-specific options, by calling
incrementalOneClassSVMdirectly. This approach is best when you do not have data yet or you want to start incremental learning immediately.Convert a traditionally trained model — To initialize a one-class SVM model for incremental learning using the model parameters of a trained
OneClassSVMmodel object, you can convert the traditionally trained model to anincrementalOneClassSVMmodel object by passing it to theincrementalLearnerfunction.Call an incremental learning function —
fitaccepts a configuredincrementalOneClassSVMmodel object and data as input, and returns anincrementalOneClassSVMmodel object updated with information learned from the input model and data.
Description
Mdl = incrementalOneClassSVMMdl for anomaly
detection. Properties of a default model contain placeholders for unknown model
parameters. You must train a default model before you can use it to detect
anomalies.
Mdl = incrementalOneClassSVM(Name=Value)incrementalOneClassSVM(ContaminationFraction=0.1,ScoreWarmupPeriod=1000)
sets the anomaly contamination fraction to 0.1 and the score warm-up
period to 1000.
Name-Value Arguments
Properties
Object Functions
Examples
Create a default one-class support vector machine (SVM) model for incremental anomaly detection.
Mdl = incrementalOneClassSVM; Mdl.ScoreWarmupPeriod
ans = 0
Mdl.ContaminationFraction
ans = 0
Mdl is an incrementalOneClassSVM model object. All its properties are read-only. By default, the software sets the score warm-up period to 0 and the anomaly contamination fraction to 0.
Mdl must be fit to data before you can use it to perform any other operations.
Load Data
Load the 1994 census data stored in census1994.mat. The data set consists of demographic data from the US Census Bureau.
load census1994.matincrementalOneClassSVM does not support categorical predictors and does not use observations with missing values. Remove missing values in the data to reduce memory consumption and speed up training. Remove the categorical predictors.
adultdata = rmmissing(adultdata); adultdata = removevars(adultdata,["workClass","education","marital_status", ... "occupation","relationship","race","sex","native_country","salary"]);
Fit Incremental Model
Fit the incremental model Mdl to the data in the adultdata table by using the fit function. Because ScoreWarmupPeriod = 0, fit returns scores and detects anomalies immediately after fitting the model for the first time. To simulate a data stream, fit the model in chunks of 100 observations at a time. At each iteration:
Process 100 observations.
Overwrite the previous incremental model with a new one fitted to the incoming observations.
Store
medianscore, the median score value of the data chunk, to see how it evolves during incremental learning.Store
allscores, the score values for the fitted observations.Store
threshold, the score threshold value for anomalies, to see how it evolves during incremental learning.Store
numAnom, the number of detected anomalies in the data chunk.
n = numel(adultdata(:,1)); numObsPerChunk = 100; nchunk = floor(n/numObsPerChunk); medianscore = zeros(nchunk,1); threshold = zeros(nchunk,1); numAnom = zeros(nchunk,1); allscores = []; % Incremental fitting rng(0,"twister"); % For reproducibility for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; Mdl = fit(Mdl,adultdata(idx,:)); [isanom,scores] = isanomaly(Mdl,adultdata(idx,:)); medianscore(j) = median(scores); allscores = [allscores scores']; numAnom(j) = sum(isanom); threshold(j) = Mdl.ScoreThreshold; end
Mdl is an incrementalOneClassSVM model object trained on all the data in the stream. The fit function fits the model to the data chunk, and the isanomaly function returns the observation scores and the indices of observations in the data chunk with scores above the score threshold value.
Analyze Incremental Model During Training
Plot the anomaly score for every observation.
plot(allscores,".-") xlabel("Observation") ylabel("Score") xlim([0 n])
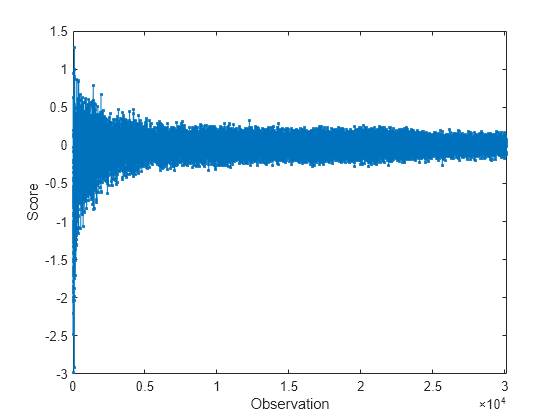
At each iteration, the software calculates a score value for each observation in the data chunk. A negative score value with large magnitude indicates a normal observation, and a large positive value indicates an anomaly.
To see how the score threshold and median score per data chunk evolve during training, plot them on separate tiles.
figure tiledlayout(2,1); nexttile plot(medianscore,".-") ylabel("Median Score") xlabel("Iteration") xlim([0 nchunk]) nexttile plot(threshold,".-") ylabel("Score Threshold") xlabel("Iteration") xlim([0 nchunk])
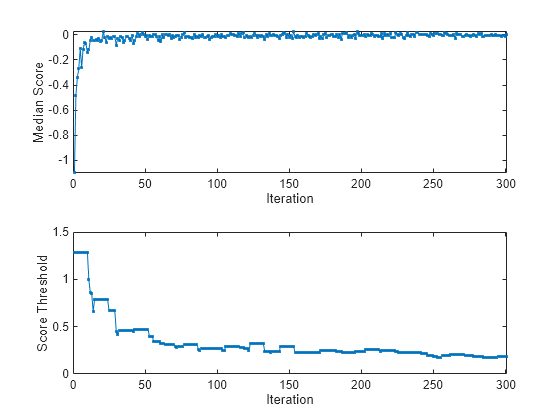
finalScoreThreshold=Mdl.ScoreThreshold
finalScoreThreshold = 0.1799
The median score is negative for the first several iterations, then rapidly approaches zero. The anomaly score threshold immediately rises from its (default) starting value of 0 to 1.3, and then gradually approaches 0.18. Because ContaminationFraction = 0, incrementalOneClassSVM treats all training observations as normal observations, and at each iteration sets the score threshold to the maximum score value in the data chunk.
totalAnomalies = sum(numAnom)
totalAnomalies = 0
No anomalies are detected at any iteration, because ContaminationFraction = 0.
Prepare an incremental one-class SVM model by specifying an anomaly contamination fraction of 0.001, and standardize the data using an initial estimation period of 2000 observations. Specify a score warm-up period of 10,000 observations, during which the fit function updates the score threshold and trains the model but does not return scores or detect anomalies.
Mdl = incrementalOneClassSVM(ContaminationFraction=0.001, ... StandardizeData=true,EstimationPeriod=2000, ... ScoreWarmupPeriod=10000);
Mdl is an incrementalOneClassSVM model object. All its properties are read-only. Mdl must be fit to data before you can use it to perform any other operations.
Load Data
Load the 1994 census data stored in census1994.mat. The data set consists of demographic data from the US Census Bureau.
load census1994.matincrementalOneClassSVM does not support categorical predictors and does not use observations with missing values. Remove missing values in the data to reduce memory consumption and speed up training. Remove the categorical predictors.
adultdata = rmmissing(adultdata); Xtrain = removevars(adultdata,["workClass","education","marital_status", ... "occupation","relationship","race","sex","native_country","salary"]);
Fit Incremental Model and Detect Anomalies
Fit the incremental model Mdl to the data by using the fit function. To simulate a data stream, fit the model in chunks of 100 observations at a time. Because EstimationPeriod = 2000 and ScoreWarmupPeriod = 10000, fit returns scores and detects anomalies only after 120 iterations. At each iteration:
Process 100 observations.
Overwrite the previous incremental model with a new one fitted to the incoming observations.
Store
meanscore, the mean score value of the data chunk, to see how it evolves during incremental learning.Store
threshold, the score threshold value for anomalies, to see how it evolves during incremental learning.Store
numAnom, the number of detected anomalies in the chunk, to see how it evolves during incremental learning.
n = numel(Xtrain(:,1)); numObsPerChunk = 100; nchunk = floor(n/numObsPerChunk); meanscore = zeros(nchunk,1); threshold = zeros(nchunk,1); numAnom = zeros(nchunk,1); % Incremental fitting rng("default"); % For reproducibility for j = 1:nchunk ibegin = min(n,numObsPerChunk*(j-1) + 1); iend = min(n,numObsPerChunk*j); idx = ibegin:iend; [Mdl,tf,scores] = fit(Mdl,Xtrain(idx,:)); meanscore(j) = mean(scores); numAnom(j) = sum(tf); threshold(j) = Mdl.ScoreThreshold; end
Mdl is an incrementalOneClassSVM model object trained on all the data in the stream.
Analyze Incremental Model During Training
To see how the mean score, score threshold, and number of detected anomalies per chunk evolve during training, plot them on separate tiles.
tiledlayout(3,1); nexttile plot(meanscore) ylabel("Mean Score") xlabel("Iteration") xlim([0 nchunk]) xline(Mdl.EstimationPeriod/numObsPerChunk,"r-.") xline((Mdl.EstimationPeriod+Mdl.ScoreWarmupPeriod)/numObsPerChunk,"r") nexttile plot(threshold) ylabel("Score Threshold") xlabel("Iteration") xlim([0 nchunk]) xline(Mdl.EstimationPeriod/numObsPerChunk,"r-.") xline((Mdl.EstimationPeriod+Mdl.ScoreWarmupPeriod)/numObsPerChunk,"r") nexttile plot(numAnom,"+") ylabel("Anomalies") xlabel("Iteration") xlim([0 nchunk]) ylim([0 max(numAnom)+0.2]) xline(Mdl.EstimationPeriod/numObsPerChunk,"r-.") xline((Mdl.EstimationPeriod+Mdl.ScoreWarmupPeriod)/numObsPerChunk,"r")
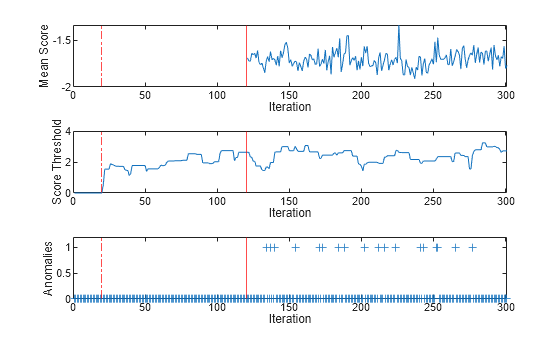
During the estimation period, fit estimates means and standard deviations using the observations, and does not fit the model or update the score threshold. During the warm-up period, the fit function fits the model and updates the score threshold, but returns all scores as NaN and all anomaly values as false. After the warm-up period, fit returns the observation scores and the indices of observations with scores above the score threshold value. A negative score value with large magnitude indicates a normal observation, and a large positive value indicates an anomaly.
totalAnomalies=sum(numAnom)
totalAnomalies = 18
anomfrac= totalAnomalies/(n-Mdl.EstimationPeriod-Mdl.ScoreWarmupPeriod)
anomfrac = 9.9108e-04
The software detected 18 anomalies after the warm-up and estimation periods. The contamination fraction after the estimation and warm-up periods is approximately 0.001.
More About
Algorithms
References
Version History
Introduced in R2023b