isanomaly
構文
説明
tf = isanomaly(LOFObj,Tbl)LocalOutlierFactor オブジェクト LOFObj を使用して table Tbl 内の異常を検出し、Tbl の対応する行で異常が検出された場合に要素が true になる logical 配列 tf を返します。関数 lof に table を渡して LOFObj を作成した場合、この構文を使用する必要があります。
tf = isanomaly(___,Name=Value)scoreThreshold=0.50.5 を超える観測値が isanomaly で異常として識別されます。
例
関数 lof を使用して、汚染されていない学習観測値用の LocalOutlierFactor オブジェクトを作成します。次に、オブジェクトおよび新規データをオブジェクト関数 isanomaly に渡して、新規性 (新規データ中の異常) を検出します。
census1994.mat に保存されている 1994 年の国勢調査データを読み込みます。このデータ セットは、個人の年収が $50,000 を超えるかどうかを予測するための、米国勢調査局の人口統計データから構成されます。
load census1994census1994 には学習データ セット adultdata およびテスト データ セット adulttest が含まれています。LocalOutlierFactor オブジェクトに学習させるには、予測子データはすべて連続、またはすべて categorical のいずれかでなければなりません。adultdata および adulttest から非数値変数を削除します。
adultdata = adultdata(:,vartype("numeric")); adulttest = adulttest(:,vartype("numeric"));
adultdata 用に局所外れ値因子モデルに学習させます。adultdata には外れ値が含まれていないと仮定します。
[Mdl,tf,s] = lof(adultdata);
Mdl は LocalOutlierFactor オブジェクトです。lof は、学習データ adultdata の異常インジケーター tf および異常スコア s も返します。名前と値の引数 ContaminationFraction を 0 を超える値として指定していない場合、lof はすべての学習観測値を正常な観測値として扱います。つまり tf の値はすべて logical 0 (false) となります。この関数によりスコアのしきい値が最大のスコア値に設定されます。しきい値を表示します。
Mdl.ScoreThreshold
ans = 28.6719
学習済みの局所外れ値因子モデルを使用して、adulttest 内の異常を見つけます。
[tf_test,s_test] = isanomaly(Mdl,adulttest);
関数 isanomaly は、adulttest の異常インジケーター tf_test およびスコア s_test を返します。既定では、isanomaly はしきい値 (Mdl.ScoreThreshold) を超えるスコアをもつ観測値を異常として識別します。
異常スコア s および s_test のヒストグラムを作成します。異常スコアのしきい値に垂直線を作成します。
h1 = histogram(s,NumBins=50,Normalization="probability"); hold on h2 = histogram(s_test,h1.BinEdges,Normalization="probability"); xline(Mdl.ScoreThreshold,"r-",join(["Threshold" Mdl.ScoreThreshold])) h1.Parent.YScale = 'log'; h2.Parent.YScale = 'log'; legend("Training Data","Test Data",Location="north") hold off
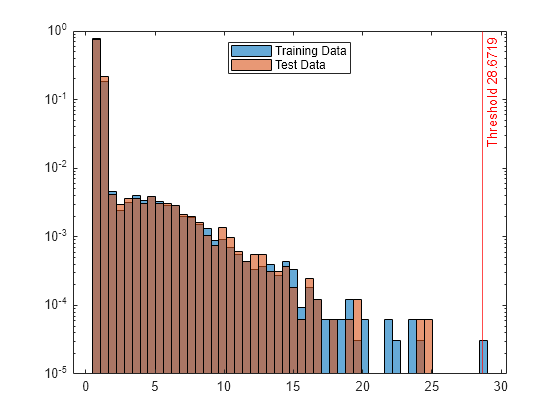
テスト データ中にある異常の観測値のインデックスを表示します。
find(tf_test)
ans = 0×1 empty double column vector
テスト データの異常スコア分布は学習データの異常スコア分布と類似しているため、isanomaly は既定のしきい値でテスト データ中にある異常を検出しません。名前と値のペア ScoreThreshold を使用して、異なるしきい値を指定できます。例については、異常スコアのしきい値の指定を参照してください。
isanomaly の名前と値の引数 ScoreThreshold を使用して、異常スコアのしきい値を指定します。
census1994.mat に保存されている 1994 年の国勢調査データを読み込みます。このデータ セットは、個人の年収が $50,000 を超えるかどうかを予測するための、米国勢調査局の人口統計データから構成されます。
load census1994census1994 には学習データ セット adultdata およびテスト データ セット adulttest が含まれています。
adultdata および adulttest から非数値変数を削除します。
adultdata = adultdata(:,vartype("numeric")); adulttest = adulttest(:,vartype("numeric"));
adultdata 用に局所外れ値因子モデルに学習させます。
[Mdl,tf,scores] = lof(adultdata);
スコア値のヒストグラムをプロットします。既定のスコアのしきい値の位置に垂直線を作成します。
h = histogram(scores,NumBins=50,Normalization="probability"); h.Parent.YScale = 'log'; xline(Mdl.ScoreThreshold,"r-",join(["Threshold" Mdl.ScoreThreshold]))
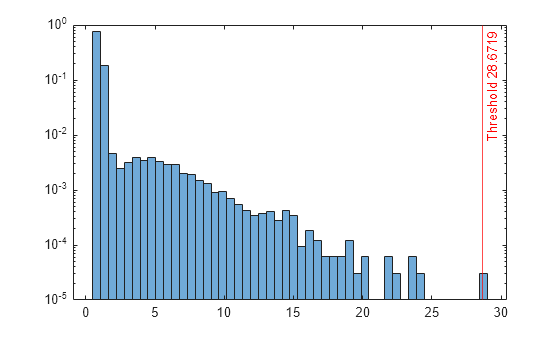
学習済みの局所外れ値因子モデルを使用して、テスト データ内の異常を見つけます。局所外れ値因子モデルの学習時に取得された既定のしきい値とは異なるしきい値を使用します。
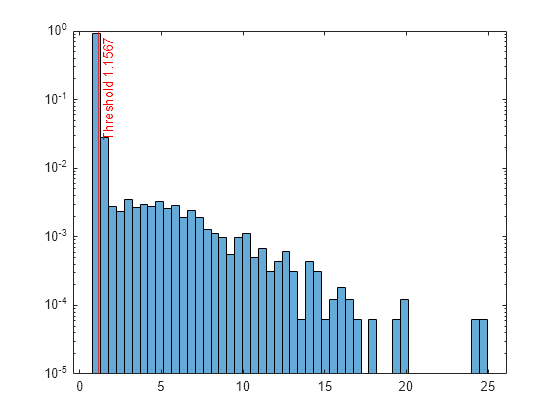
まず、関数isoutlierを使用してスコアのしきい値を調べます。
[~,~,U] = isoutlier(scores)
U = 1.1567
名前と値の引数 ScoreThreshold の値を U として指定します。
[tf_test,scores_test] = isanomaly(Mdl,adulttest,ScoreThreshold=U); h = histogram(scores_test,NumBins=50,Normalization="probability"); h.Parent.YScale = 'log'; xline(U,"r-",join(["Threshold" U]))
外れ値が含まれている標本データ セットを生成します。関数 isanomaly を使用して標本データの周りの点の異常スコアを計算し、異常スコアの等高線図を作成します。次に、適合率-再現率曲線をプロットして、学習済みの局所外れ値モデルの性能をチェックします。
ガウス型コピュラを使用して、二変量分布からランダムなデータ点を生成します。
rng("default") rho = [1,0.05;0.05,1]; n = 1000; u = copularnd("Gaussian",rho,n);
無作為に選択された 5% の観測値にノイズを追加して、それらの観測値を外れ値にします。
noise = randperm(n,0.05*n); true_tf = false(n,1); true_tf(noise) = true; u(true_tf,1) = u(true_tf,1)*5;
関数 lof を使用して局所外れ値因子モデルに学習させます。学習観測値に含まれている異常の比率を 0.05 に設定します。パフォーマンス向上のために、SearchMethod、NumNeighbors、Distance などの名前と値の引数を指定して、局所外れ値因子アルゴリズムのオプションを変更することもできます。ここでは、使用する最近傍の個数を 40 と指定します。
[LOFObj,tf,scores] = lof(u,ContaminationFraction=0.05,NumNeighbors=40);
学習済みの局所外れ値因子モデルと関数 isanomaly を使用して、学習観測値の周りの 2 次元グリッド座標の異常スコアを計算します。
l1 = linspace(min(u(:,1),[],1),max(u(:,1),[],1)); l2 = linspace(min(u(:,2),[],1),max(u(:,2),[],1)); [X1,X2] = meshgrid(l1,l2); [~,scores_grid] = isanomaly(LOFObj,[X1(:),X2(:)]); scores_grid = reshape(scores_grid,size(X1,1),size(X2,2));
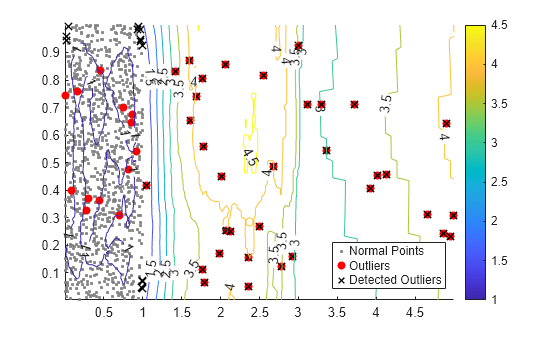
学習観測値の散布図と異常スコアの等高線図を作成します。真の外れ値と lof で検出された外れ値にフラグを付けます。
idx = setdiff(1:1000,noise); scatter(u(idx,1),u(idx,2),[],[0.5 0.5 0.5],".") hold on scatter(u(noise,1),u(noise,2),"ro","filled") scatter(u(tf,1),u(tf,2),60,"kx",LineWidth=1) contour(X1,X2,scores_grid,"ShowText","on") legend(["Normal Points" "Outliers" "Detected Outliers"],Location="best") colorbar hold off
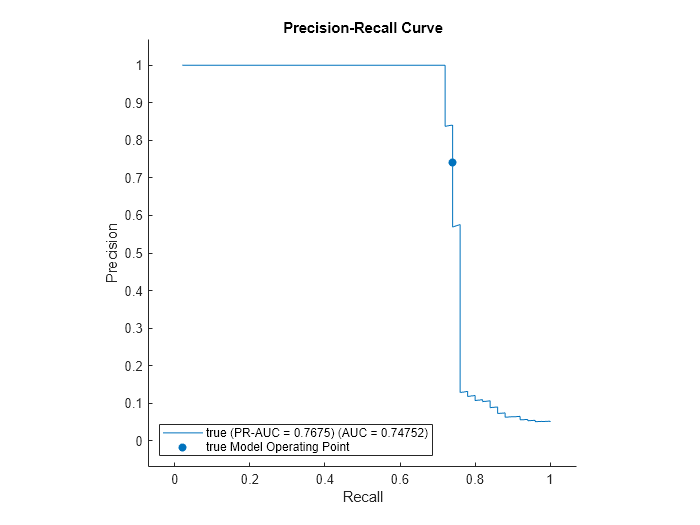
適合率-再現率曲線をプロットし、曲線の下の領域 (AUC) の値を計算して、学習済みの局所外れ値因子モデルの性能をチェックします。rocmetricsオブジェクトを作成します。rocmetrics では、既定では偽陽性率と真陽性率 (つまり再現率) が計算されます。名前と値の引数 AdditionalMetrics を指定して、適合率の値 (つまり陽性の予測値) を追加で計算します。
rocObj = rocmetrics(true_tf,scores,true,AdditionalMetrics="PositivePredictiveValue");rocmetrics の関数 plot を使用して曲線をプロットします。"y" 軸のメトリクスを適合率 (つまり陽性の予測値)、"x" 軸のメトリクスを再現率 (つまり真陽性率) として指定します。LOFObj.ScoreThreshold に対応するモデル操作点に塗りつぶされた円を表示します。関数 trapz の台形法を使用して適合率-再現率曲線の下の領域を計算し、その値を凡例に表示します。
r = plot(rocObj,YAxisMetric="PositivePredictiveValue",XAxisMetric="TruePositiveRate"); hold on idx = find(rocObj.Metrics.Threshold>=LOFObj.ScoreThreshold,1,'last'); scatter(rocObj.Metrics.TruePositiveRate(idx), ... rocObj.Metrics.PositivePredictiveValue(idx), ... [],r.Color,"filled") xyData = rmmissing([r.XData r.YData]); auc = trapz(xyData(:,1),xyData(:,2)); legend(join([r.DisplayName " (AUC = " string(auc) ")"],""),"true Model Operating Point") xlabel("Recall") ylabel("Precision") title("Precision-Recall Curve") hold off
入力引数
名前と値の引数
出力引数
詳細
アルゴリズム
TblまたはXの各観測値について局所外れ値因子の値 (scores) を計算するために、isanomalyは、LocalOutlierFactorオブジェクトのXプロパティに格納されている学習観測値の中から k 最近傍を探索します。isanomalyは、Tblに含まれているNaN、''(空の文字ベクトル)、""(空の string)、<missing>、<undefined>の値とXに含まれているNaN値を欠損値と見なします。isanomalyは、欠損値のある観測値は使用しません。isanomalyは、欠損値のある観測値に異常スコアNaNおよび異常インジケーターfalse(logical 0) を割り当てます。
参照
[1] Breunig, Markus M., et al. “LOF: Identifying Density-Based Local Outliers.” Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, 2000, pp. 93–104.