predict
構文
説明
例
補助関数の HelperRegrGenerator と HelperConceptDriftGenerator をそれぞれ使用して、ランダムな概念データと概念ドリフト発生器を作成します。
concept1 = HelperRegrGenerator(NumFeatures=100,NonZeroFeatures=[1,20,40,50,55], ... FeatureCoefficients=[4,5,10,-2,-6],NoiseStd=1.1,TableOutput=false); concept2 = HelperRegrGenerator(NumFeatures=100,NonZeroFeatures=[10,20,45,56,80], ... FeatureCoefficients=[4,5,10,-2,-6],NoiseStd=1.1,TableOutput=false); driftGenerator = HelperConceptDriftGenerator(concept1,concept2,15000,1000);
HelperRegrGenerator は、関数の呼び出しで指定された回帰用の特徴量と特徴量係数を使用してストリーミング データを生成します。この関数は、各ステップで正規分布から予測子を抽出します。その後、関数は特徴量係数と予測子の値を使用して、平均がゼロで指定のノイズ標準偏差をもつ正規分布からランダム ノイズを追加することで応答を計算します。そのデータがインクリメンタル学習器で使用するために行列として返されます。
HelperConceptDriftGenerator は、概念ドリフトを確立します。このオブジェクトでは、シグモイド関数 1./(1+exp(-4*(numobservations-position)./width)) を使用して、データ生成時に 1 つ目のストリームが選択される確率を判定します [3]。この例では、位置の引数が 15000 で、幅の引数が 1000 です。観測値の数が位置の値から幅の半分を引いた値を超えると、データ生成時に 1 つ目のストリームから抽出される確率が低下します。このシグモイド関数により、一方のストリームからもう一方への滑らかな遷移が実現します。幅の値が大きいほど、両方のストリームがほぼ等しい確率で選択される遷移期間が大きいことを示します。
回帰用のインクリメンタル ドリフト認識モデルを次のように開始します。
回帰用のインクリメンタル線形モデルを作成します。線形回帰モデルのタイプとソルバーのタイプを指定します。
移動平均による Hoeffding 境界のドリフト検出法 (HDDMA) を使用するインクリメンタルな概念ドリフト検出器を開始します。
インクリメンタル線形モデルと概念ドリフト検出器を使用して、インクリメンタル ドリフト認識モデルをインスタンス化します。学習期間を 6000 個の観測値として指定します。
baseMdl = incrementalRegressionLinear(Learner="leastsquares",Solver="sgd",EstimationPeriod=1000,Standardize=false); dd = incrementalConceptDriftDetector("hddma",Alternative="greater",InputType="continuous",WarmupPeriod=1000); idaMdl = incrementalDriftAwareLearner(baseMdl,DriftDetector=dd,TrainingPeriod=6000);
データ ストリームの作成用に各チャンクの変数の数と反復回数を事前に割り当てます。
numObsPerChunk = 10; numIterations = 4000;
ドリフト ステータスとドリフト時間を追跡する変数、および回帰誤差を格納する変数を事前に割り当てます。
dstatus = zeros(numIterations,1); statusname = strings(numIterations,1); driftTimes = []; ce = array2table(zeros(numIterations,2),VariableNames=["Cumulative" "Window"]);
それぞれ 10 個の観測値の入力チャンクを使用してデータ ストリームをシミュレートし、インクリメンタル ドリフト認識学習を実行します。各反復で次を行います。
予測子データとラベルをシミュレートし、補助関数
hgenerateを使用してドリフト発生器を更新します。updateMetricsを呼び出してパフォーマンス メトリクスを更新し、fitを呼び出してインクリメンタル ドリフト認識モデルを入力データに当てはめます。可視化のためにドリフト ステータスと回帰誤差を追跡して記録します。
rng(12); % For reproducibility for j = 1:numIterations % Generate data [driftGenerator,X,Y] = hgenerate(driftGenerator,numObsPerChunk); % Update performance metrics and fit idaMdl = updateMetrics(idaMdl,X,Y); idaMdl = fit(idaMdl,X,Y); % Record drift status and regression error statusname(j) = string(idaMdl.DriftStatus); ce{j,:} = idaMdl.Metrics{"MeanSquaredError",:}; if idaMdl.DriftDetected dstatus(j) = 2; driftTimes(end+1) = j; elseif idaMdl.WarningDetected dstatus(j) = 1; else dstatus(j) = 0; end end
ドリフト ステータスと反復回数の関係をプロットします。
figure() gscatter(1:numIterations,dstatus,statusname,'gmr','o',5,'on',"Iteration","Drift Status","filled")

累積とウィンドウごとの回帰誤差をプロットします。ウォームアップ期間と学習期間、およびドリフトが発生した時点をマークします。
figure() h = plot(ce.Variables); xlim([0 numIterations]) ylim([0 20]) ylabel("Mean Squared Error") xlabel("Iteration") xline((idaMdl.MetricsWarmupPeriod+idaMdl.BaseLearner.EstimationPeriod)/numObsPerChunk,"g-.","Estimation Period + Warmup Period",LineWidth=1.5) xline((idaMdl.MetricsWarmupPeriod+idaMdl.BaseLearner.EstimationPeriod)/numObsPerChunk+driftTimes,"g-.","Estimation Period + Warmup Period",LineWidth=1.5) xline(idaMdl.TrainingPeriod/numObsPerChunk,"b-.","Training Period",LabelVerticalAlignment="middle",LineWidth=1.5) xline(driftTimes,"m--","Drift",LabelVerticalAlignment="middle",LineWidth=1.5) legend(h,ce.Properties.VariableNames) legend(h,Location="best")
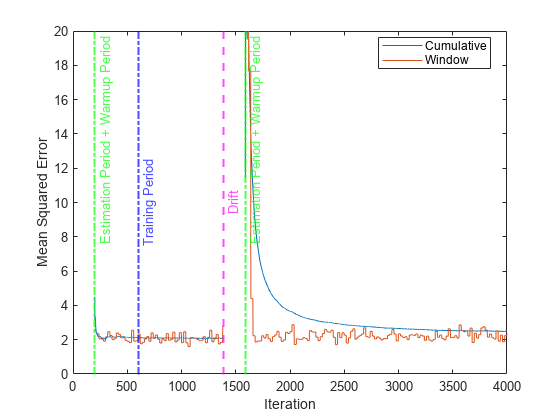
ドリフトの検出後、関数 fit は関数 reset を呼び出してインクリメンタル ドリフト認識学習器、つまりベース学習器とドリフト検出器をリセットします。関数 updateMetrics は、idaMdl.BaseLearner.EstimationPeriod+idaMdl.MetricsWarmupPeriod の観測値を待ってからモデルのパフォーマンス メトリクスの更新を再開します。
新しいデータを生成します。列の予測子変数を再配向します。
[driftGenerator,X,Y] = hgenerate(driftGenerator,500); X = X';
新しいデータで応答を予測します。予測子変数の方向を指定します。
yhat = predict(idaMdl,X,ObservationsIn="columns");残差を計算してプロットします。
res = Y - yhat; plot(res) ylabel("Residuals") xlabel("New data points")
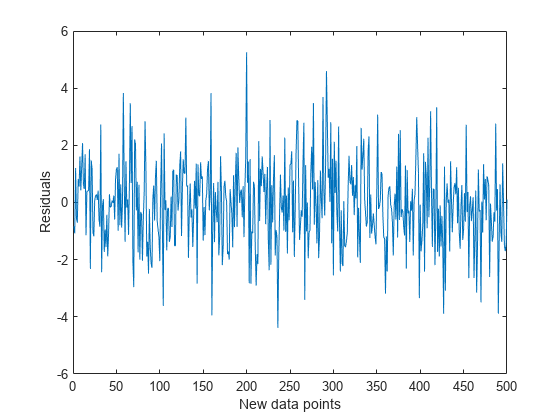
残差は、新しいデータで 0 を中心に対称的に広がっています。
HelperSineGenerator を使用してランダムな概念データを作成し、HelperConceptDriftGenerator を使用して概念ドリフト発生器を作成します。
concept1 = HelperSineGenerator("ClassificationFunction",1,"IrrelevantFeatures",true,"TableOutput",false); concept2 = HelperSineGenerator("ClassificationFunction",3,"IrrelevantFeatures",true,"TableOutput",false); driftGenerator = HelperConceptDriftGenerator(concept1,concept2,15000,1000);
ClassificationFunction が 1 の場合、HelperSineGenerator は "x1" < "sin(x2)" を満たすすべての点に 1 のラベルを付け、それ以外に 0 のラベルを付けます。ClassificationFunction が 3 の場合はその逆になります。つまり、HelperSineGenerator は、"x1" >= "sin(x2)" を満たすすべての点に 1 のラベルを付け、それ以外に 0 のラベルを付けます。
HelperConceptDriftGenerator は、概念ドリフトを確立します。このオブジェクトでは、シグモイド関数 1./(1+exp(-4*(numobservations-position)./width)) を使用して、データ生成時に 1 つ目のストリームが選択される確率を判定します [1]。この例では、位置の引数が 15000 で、幅の引数が 1000 です。観測値の数が位置の値から幅の半分を引いた値を超えると、データ生成時に 1 つ目のストリームから抽出される確率が低下します。このシグモイド関数により、一方のストリームからもう一方への滑らかな遷移が実現します。幅の値が大きいほど、両方のストリームがほぼ等しい確率で選択される遷移期間が大きいことを示します。
インクリメンタル ドリフト認識モデルを次のようにインスタンス化します。
バイナリ分類用のインクリメンタル単純ベイズ分類モデルを作成します。
移動平均による Hoeffding 境界のドリフト検出法 (HDDMA) を使用するインクリメンタルな概念ドリフト検出器を開始します。
インクリメンタル線形モデルと概念ドリフト検出器を使用して、インクリメンタル ドリフト認識モデルをインスタンス化します。学習期間を 5000 個の観測値として指定します。
BaseLearner = incrementalClassificationLinear(Solver="sgd"); dd = incrementalConceptDriftDetector("hddma"); idaMdl = incrementalDriftAwareLearner(BaseLearner,DriftDetector=dd,TrainingPeriod=5000);
データ ストリームの作成用に各チャンクの変数の数と反復回数を事前に割り当てます。
numObsPerChunk = 10; numIterations = 4000;
ドリフト ステータスとドリフト時間を追跡する変数、および分類誤差を格納する変数を事前に割り当てます。
dstatus = zeros(numIterations,1); statusname = strings(numIterations,1); ce = array2table(zeros(numIterations,2),VariableNames=["Cumulative" "Window"]); driftTimes = [];
それぞれ 10 個の観測値の入力チャンクを使用してデータ ストリームをシミュレートし、インクリメンタル ドリフト認識学習を実行します。各反復で次を行います。
予測子データとラベルをシミュレートし、補助関数
hgenerateを使用してドリフト発生器を更新します。updateMetricsAndFitを呼び出して、パフォーマンス メトリクスを更新し、インクリメンタル ドリフト認識モデルを入力データに当てはめます。可視化のためにドリフト ステータスと分類誤差を追跡して記録します。
rng(12); % For reproducibility for j = 1:numIterations % Generate data [driftGenerator,X,Y] = hgenerate(driftGenerator,numObsPerChunk); % Update performance metrics and fit idaMdl = updateMetricsAndFit(idaMdl,X,Y); % Record drift status and classification error statusname(j) = string(idaMdl.DriftStatus); ce{j,:} = idaMdl.Metrics{"ClassificationError",:}; if idaMdl.DriftDetected dstatus(j) = 2; driftTimes(end+1) = j; elseif idaMdl.WarningDetected dstatus(j) = 1; else dstatus(j) = 0; end end
累積とウィンドウごとの分類誤差をプロットします。ウォームアップ期間と学習期間、およびドリフトが発生した時点をマークします。
h = plot(ce.Variables); xlim([0 numIterations]) ylim([0 0.08]) ylabel("Classification Error") xlabel("Iteration") xline((idaMdl.BaseLearner.EstimationPeriod+idaMdl.MetricsWarmupPeriod)/numObsPerChunk,"g-.","Estimation + Warmup Period",LineWidth=1.5) xline(idaMdl.TrainingPeriod/numObsPerChunk,"b-.","Training Period",LabelVerticalAlignment="middle",LineWidth=1.5) xline(driftTimes,"m--","Drift",LabelVerticalAlignment="middle",LineWidth=1.5) legend(h,ce.Properties.VariableNames) legend(h,Location="best")

ドリフト ステータスと反復回数の関係をプロットします。
gscatter(1:numIterations,dstatus,statusname,'gmr','o',4,'on',"Iteration","Drift Status","Filled")

500 個の観測値からなる新しいデータを生成します。新しいデータのクラス ラベルと分類スコアを予測します。
numnewdata = 500; [driftGenerator,X,Y] = hgenerate(driftGenerator,numnewdata); [yhat,cscores] = predict(idaMdl,X);
ROC を計算して結果をプロットします。
roc = rocmetrics(Y,cscores,idaMdl.BaseLearner.ClassNames); plot(roc)

関数 plot は、各クラスの ROC 曲線をプロットし、モデル操作点に塗りつぶされた円のマーカーを表示します。凡例に各曲線のクラスの名前と AUC の値が表示されます。バイナリ分類問題では、2 つの ROC 曲線は対称であり、AUC の値は同じになります。
モデルの精度を計算します。
accuracy = sum(Y==yhat)/500
accuracy = 0.9780
モデルは新しいクラス ラベルを高い精度で予測しています。
入力引数
出力引数
参照
バージョン履歴
R2022b で導入