fitsemigraph
グラフベースの半教師あり手法を使用したデータへのラベル付け
構文
説明
fitsemigraph は、ラベル付けされたデータ、ラベル、およびラベル付けされていないデータが与えられた、半教師ありグラフベース モデルを作成します。返されるモデルには、ラベル付けされていないデータに当てはめられたラベル、および対応するスコアが含まれます。このモデルは、オブジェクト関数 predict を使用して未観測データのラベルを予測することもできます。異なるラベル付けアルゴリズムの詳細については、アルゴリズムを参照してください。
Mdl = fitsemigraph(Tbl,ResponseVarName,UnlabeledTbl)Tbl 内のラベル付けされたデータを使用します。ここで、Tbl.ResponseVarName はラベル付けされたデータのラベルを格納しており、UnlabeledTbl 内のラベル付けされていないデータに当てはめられたラベルを返します。この関数は、オブジェクト Mdl の FittedLabels プロパティおよび LabelScores プロパティに、当てはめられたラベルおよび対応するスコアをそれぞれ保存します。
Mdl = fitsemigraph(Tbl,formula,UnlabeledTbl)formula を使用して、Tbl に含まれる変数で使用する応答変数 (ラベルのベクトル) と予測子変数を指定します。この関数は、これらの変数を使用して、UnlabeledTbl 内のデータにラベルを付けます。
Mdl = fitsemigraph(Tbl,Y,UnlabeledTbl)Tbl 内の予測子データと Y 内のラベルを使用して、UnlabeledTbl 内のデータにラベルを付けます。
Mdl = fitsemigraph(X,Y,UnlabeledX)X 内の予測子データと Y 内のラベルを使用して、UnlabeledX 内のデータにラベルを付けます。
Mdl = fitsemigraph(___,Name,Value)
例
グラフベースの半教師あり手法を使用して、ラベル付けされていないデータにラベルを当てはめます。
ラベル付けされたデータの観測値をランダムに 60 個生成し、その観測値が 20 個ずつ 3 つのクラスに属するようにします。
rng('default') % For reproducibility labeledX = [randn(20,2)*0.25 + ones(20,2); randn(20,2)*0.25 - ones(20,2); randn(20,2)*0.5]; Y = [ones(20,1); ones(20,1)*2; ones(20,1)*3];
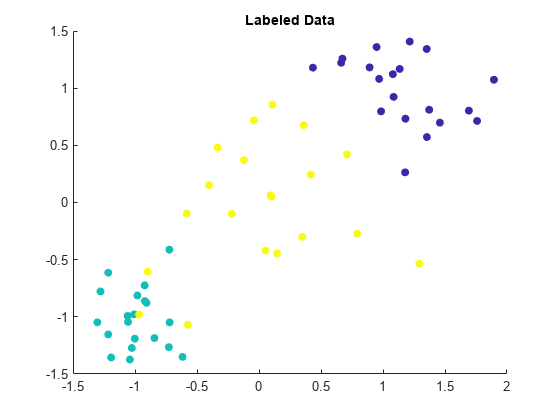
散布図を使用して、ラベル付けされたデータを可視化します。同じクラスに属する観測値は同じ色で示します。データは 3 つのクラスターに分割されていますが、わずかにオーバーラップしていることに注意してください。
scatter(labeledX(:,1),labeledX(:,2),[],Y,'filled') title('Labeled Data')
ラベル付けされていないデータの観測値を追加でランダムに 300 個生成し、各クラスに 100 個ずつ属するようにします。検証のため、ラベル付けされていないデータの真のラベルを追跡します。
unlabeledX = [randn(100,2)*0.25 + ones(100,2);
randn(100,2)*0.25 - ones(100,2);
randn(100,2)*0.5];
trueLabels = [ones(100,1); ones(100,1)*2; ones(100,1)*3];グラフベースの半教師あり手法を使用して、ラベル付けされていないデータにラベルを当てはめます。関数 fitsemigraph は SemiSupervisedGraphModel オブジェクトを返します。このオブジェクトの FittedLabels プロパティにはラベル付けされていないデータに当てはめられたラベルが、LabelScores プロパティには関連するラベル スコアが含まれます。
Mdl = fitsemigraph(labeledX,Y,unlabeledX)
Mdl =
SemiSupervisedGraphModel with properties:
FittedLabels: [300×1 double]
LabelScores: [300×3 double]
ClassNames: [1 2 3]
ResponseName: 'Y'
CategoricalPredictors: []
Method: 'labelpropagation'
Properties, Methods
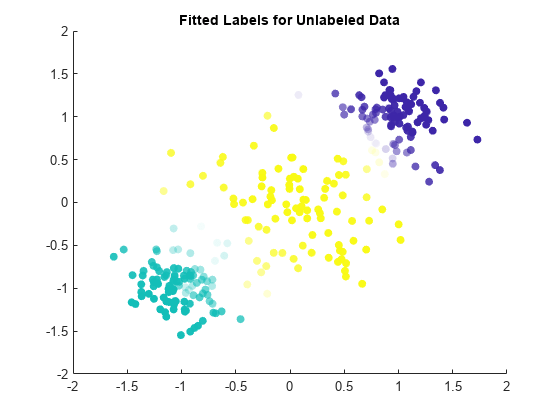
散布図を使用して、当てはめられたラベルの結果を可視化します。当てはめられたラベルを使用して観測値の色を設定し、最大のラベル スコアを使用して観測値の透明度を設定します。透明度が低い観測値には、高い信頼度のラベルを付けます。クラスターの境界付近に位置している観測値には、低い信頼度のラベルが付いていることに注意してください。
maxLabelScores = max(Mdl.LabelScores,[],2); rescaledScores = rescale(maxLabelScores,0.05,0.95); scatter(unlabeledX(:,1),unlabeledX(:,2),[],Mdl.FittedLabels,'filled', ... 'MarkerFaceAlpha','flat','AlphaData',rescaledScores); title('Fitted Labels for Unlabeled Data')
ラベル付けされていないデータの真のラベルを使用して、ラベル付けの精度を判断します。
numWrongLabels = sum(trueLabels ~= Mdl.FittedLabels)
numWrongLabels = 10
unlabeledX 内の 300 個の観測値のうち、誤ったラベルが付けられた観測値はわずか 10 個です。
グラフベースの半教師あり手法を使用して、ラベル付けされていないデータにラベルを当てはめます。最近傍グラフのタイプを指定します。
patients データ セットを読み込みます。変数 Distolic、Gender などから table を作成します。各観測値、つまり table の行では、Smoker 値をその観測値のラベルとして扱います。
load patients
Tbl = table(Diastolic,Gender,Height,Systolic,Weight,Smoker);観測値の 20% にのみラベルが付けられているものとします。このシナリオを再作成するために、ラベル付けされた観測値を 20 個無作為に抽出し、それを table unlabeledTbl に保存します。残りの観測値からラベルを削除し、それを table unlabeledTbl に保存します。例の終わりでラベルの当てはめの精度を確認するため、ラベル付けされていないデータの真のラベルを変数 trueLabels に保持します。
rng('default') % For reproducibility of the sampling [labeledTbl,Idx] = datasample(Tbl,20,'Replace',false); unlabeledTbl = Tbl; unlabeledTbl(Idx,:) = []; trueLabels = unlabeledTbl.Smoker; unlabeledTbl.Smoker = [];
グラフベースの半教師あり手法を使用して、ラベル付けされていないデータにラベルを当てはめます。相互型の最近傍グラフを使用します。このグラフでは、互いに最近傍である 2 点が接続されます。数値予測子を標準化するための指定を行います。関数 fitsemigraph が返すオブジェクトの FittedLabels プロパティには、ラベル付けされていないデータに当てはめられたラベルが含まれます。
Mdl = fitsemigraph(labeledTbl,'Smoker',unlabeledTbl,'KNNGraphType','mutual', ... 'Standardize',true); fittedLabels = Mdl.FittedLabels;
誤ってラベルが付けられた観測値を特定するため、保存済みのラベル付けされていないデータの真のラベルを、グラフベースの半教師あり手法で返された当てはめ済みのラベルと比較します。
wrongIdx = (trueLabels ~= fittedLabels); wrongTbl = unlabeledTbl(wrongIdx,:);
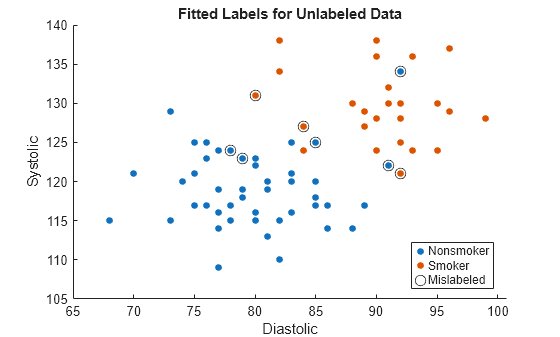
ラベル付けされていないデータに当てはめられたラベルの結果を可視化します。誤ってラベルが付けられた観測値は、プロット内で円で囲まれます。
gscatter(unlabeledTbl.Diastolic,unlabeledTbl.Systolic, ... fittedLabels) hold on plot(wrongTbl.Diastolic,wrongTbl.Systolic, ... 'ko','MarkerSize',8) xlabel('Diastolic') ylabel('Systolic') legend('Nonsmoker','Smoker','Mislabeled') title('Fitted Labels for Unlabeled Data')
入力引数
名前と値の引数
出力引数
詳細
アルゴリズム
参照
[1] Zhou, Dengyong, Olivier Bousquet, Thomas Navin Lal, Jason Weston, and Bernhard Schölkopf. “Learning with Local and Global Consistency.” Advances in Neural Information Processing Systems 16 (NIPS). 2003.
[2] Zhu, Xiaojin, and Zoubin Ghahramani. “Learning from Labeled and Unlabeled Data with Label Propagation.” CMU CALD tech report CMU-CALD-02-107. 2002.
[3] Zhu, Xiaojin, Zoubin Ghahramani, and John Lafferty. “Semi-Supervised Learning Using Gaussian Fields and Harmonic Functions.” The Twentieth International Conference on Machine Learning (ICML). 2003.
バージョン履歴
R2020b で導入