SemiSupervisedGraphModel
分類用の半教師ありグラフベース モデル
説明
関数 fitsemigraph を使用すると、グラフベースの半教師あり手法でラベル付けされていないデータにラベルを付けられます。結果となる SemiSupervisedGraphModel オブジェクトには、ラベル付けされていない観測値に当てはめられたラベル (FittedLabels) とそのスコア (LabelScores) が含まれます。また、SemiSupervisedGraphModel オブジェクトを分類器として使用して、ラベル付けされたデータとラベル付けされていないデータの両方で学習させ、関数 predict を使って新しいデータを分類することもできます。
作成
SemiSupervisedGraphModel オブジェクトの作成には fitsemigraph を使用します。
プロパティ
オブジェクト関数
predict | 半教師ありグラフベース分類器を使用した新しいデータのラベル付け |
例
グラフベースの半教師あり手法を使用して、ラベル付けされていないデータにラベルを当てはめます。
ラベル付けされたデータの観測値をランダムに 60 個生成し、その観測値が 20 個ずつ 3 つのクラスに属するようにします。
rng('default') % For reproducibility labeledX = [randn(20,2)*0.25 + ones(20,2); randn(20,2)*0.25 - ones(20,2); randn(20,2)*0.5]; Y = [ones(20,1); ones(20,1)*2; ones(20,1)*3];
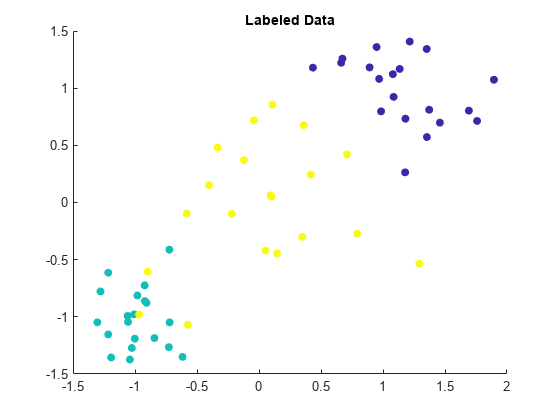
散布図を使用して、ラベル付けされたデータを可視化します。同じクラスに属する観測値は同じ色で示します。データは 3 つのクラスターに分割されていますが、わずかにオーバーラップしていることに注意してください。
scatter(labeledX(:,1),labeledX(:,2),[],Y,'filled') title('Labeled Data')
ラベル付けされていないデータの観測値を追加でランダムに 300 個生成し、各クラスに 100 個ずつ属するようにします。検証のため、ラベル付けされていないデータの真のラベルを追跡します。
unlabeledX = [randn(100,2)*0.25 + ones(100,2);
randn(100,2)*0.25 - ones(100,2);
randn(100,2)*0.5];
trueLabels = [ones(100,1); ones(100,1)*2; ones(100,1)*3];グラフベースの半教師あり手法を使用して、ラベル付けされていないデータにラベルを当てはめます。関数 fitsemigraph は SemiSupervisedGraphModel オブジェクトを返します。このオブジェクトの FittedLabels プロパティにはラベル付けされていないデータに当てはめられたラベルが、LabelScores プロパティには関連するラベル スコアが含まれます。
Mdl = fitsemigraph(labeledX,Y,unlabeledX)
Mdl =
SemiSupervisedGraphModel with properties:
FittedLabels: [300×1 double]
LabelScores: [300×3 double]
ClassNames: [1 2 3]
ResponseName: 'Y'
CategoricalPredictors: []
Method: 'labelpropagation'
Properties, Methods
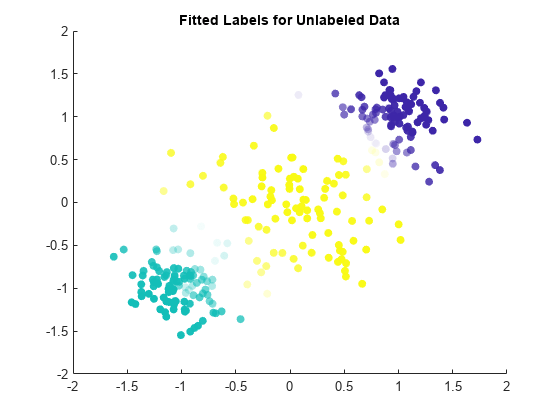
散布図を使用して、当てはめられたラベルの結果を可視化します。当てはめられたラベルを使用して観測値の色を設定し、最大のラベル スコアを使用して観測値の透明度を設定します。透明度が低い観測値には、高い信頼度のラベルを付けます。クラスターの境界付近に位置している観測値には、低い信頼度のラベルが付いていることに注意してください。
maxLabelScores = max(Mdl.LabelScores,[],2); rescaledScores = rescale(maxLabelScores,0.05,0.95); scatter(unlabeledX(:,1),unlabeledX(:,2),[],Mdl.FittedLabels,'filled', ... 'MarkerFaceAlpha','flat','AlphaData',rescaledScores); title('Fitted Labels for Unlabeled Data')
ラベル付けされていないデータの真のラベルを使用して、ラベル付けの精度を判断します。
numWrongLabels = sum(trueLabels ~= Mdl.FittedLabels)
numWrongLabels = 10
unlabeledX 内の 300 個の観測値のうち、誤ったラベルが付けられた観測値はわずか 10 個です。
ラベル付けされたデータとラベル付けされていないデータの両方を使用して、SemiSupervisedGraphModel オブジェクトに学習させます。学習済みのモデルを使用して新しいデータにラベルを付けます。
ラベル付けされたデータの観測値をランダムに 15 個生成し、その観測値が 5 個ずつ 3 つのクラスに属するようにします。
rng('default') % For reproducibility labeledX = [randn(5,2)*0.25 + ones(5,2); randn(5,2)*0.25 - ones(5,2); randn(5,2)*0.5]; Y = [ones(5,1); ones(5,1)*2; ones(5,1)*3];
ラベル付けされていないデータの観測値を追加でランダムに 300 個生成し、各クラスに 100 個ずつ属するようにします。
unlabeledX = [randn(100,2)*0.25 + ones(100,2);
randn(100,2)*0.25 - ones(100,2);
randn(100,2)*0.5];グラフベースの半教師あり手法を使用して、ラベル付けされていないデータにラベルを当てはめます。ラベル付けアルゴリズムとしてラベル拡散を指定し、自動的に選択されるカーネル スケール係数を使用します。関数 fitsemigraph は SemiSupervisedGraphModel オブジェクトを返します。このオブジェクトの FittedLabels プロパティにはラベル付けされていないデータに当てはめられたラベルが、LabelScores プロパティには関連するラベル スコアが含まれます。
Mdl = fitsemigraph(labeledX,Y,unlabeledX,'Method','labelspreading', ... 'KernelScale','auto')
Mdl =
SemiSupervisedGraphModel with properties:
FittedLabels: [300×1 double]
LabelScores: [300×3 double]
ClassNames: [1 2 3]
ResponseName: 'Y'
CategoricalPredictors: []
Method: 'labelspreading'
Properties, Methods
新しいデータの観測値をランダムに 150 個生成し、各クラスに 50 個ずつ属するようにします。検証のために、新しいデータの真のラベルを追跡します。
newX = [randn(50,2)*0.25 + ones(50,2);
randn(50,2)*0.25 - ones(50,2);
randn(50,2)*0.5];
trueLabels = [ones(50,1); ones(50,1)*2; ones(50,1)*3];SemiSupervisedGraphModel オブジェクトの関数 predict を使用して、新しいデータのラベルを予測します。混同行列を使用して、真のラベルを予測ラベルと比較します。
predictedLabels = predict(Mdl,newX); confusionchart(trueLabels,predictedLabels)
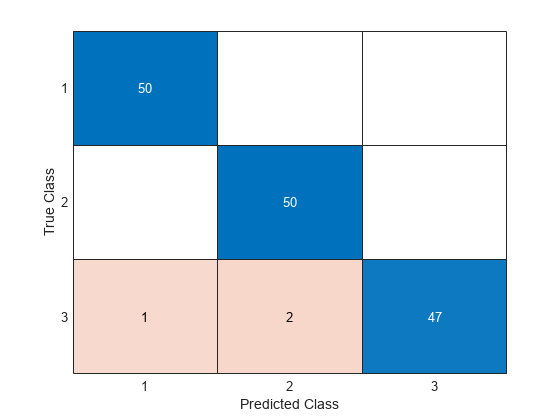
newX 内の 150 個の観測値のうち、誤りのラベルが付けられた観測値はわずか 3 個です。
ヒント
lime、shapley、partialDependence、plotPartialDependenceなどの解釈可能性機能を使用して、予測に対する予測子の寄与の程度を解釈できます。カスタム関数を定義し、解釈可能性関数に渡す必要があります。カスタム関数は、ラベル (limeの場合)、単一クラスのスコア (shapleyの場合)、および 1 つ以上のクラスのスコア (partialDependenceとplotPartialDependenceの場合) を返す必要があります。例については、関数ハンドルを使用したモデルの指定を参照してください。
バージョン履歴
R2020b で導入