predict
半教師ありグラフベース分類器を使用した新しいデータのラベル付け
説明
例
ラベル付けされたデータとラベル付けされていないデータの両方を使用して、SemiSupervisedGraphModel オブジェクトに学習させます。学習済みのモデルを使用して新しいデータにラベルを付けます。
ラベル付けされたデータの観測値をランダムに 15 個生成し、その観測値が 5 個ずつ 3 つのクラスに属するようにします。
rng('default') % For reproducibility labeledX = [randn(5,2)*0.25 + ones(5,2); randn(5,2)*0.25 - ones(5,2); randn(5,2)*0.5]; Y = [ones(5,1); ones(5,1)*2; ones(5,1)*3];
ラベル付けされていないデータの観測値を追加でランダムに 300 個生成し、各クラスに 100 個ずつ属するようにします。
unlabeledX = [randn(100,2)*0.25 + ones(100,2);
randn(100,2)*0.25 - ones(100,2);
randn(100,2)*0.5];グラフベースの半教師あり手法を使用して、ラベル付けされていないデータにラベルを当てはめます。ラベル付けアルゴリズムとしてラベル拡散を指定し、自動的に選択されるカーネル スケール係数を使用します。関数 fitsemigraph は SemiSupervisedGraphModel オブジェクトを返します。このオブジェクトの FittedLabels プロパティにはラベル付けされていないデータに当てはめられたラベルが、LabelScores プロパティには関連するラベル スコアが含まれます。
Mdl = fitsemigraph(labeledX,Y,unlabeledX,'Method','labelspreading', ... 'KernelScale','auto')
Mdl =
SemiSupervisedGraphModel with properties:
FittedLabels: [300×1 double]
LabelScores: [300×3 double]
ClassNames: [1 2 3]
ResponseName: 'Y'
CategoricalPredictors: []
Method: 'labelspreading'
Properties, Methods
新しいデータの観測値をランダムに 150 個生成し、各クラスに 50 個ずつ属するようにします。検証のために、新しいデータの真のラベルを追跡します。
newX = [randn(50,2)*0.25 + ones(50,2);
randn(50,2)*0.25 - ones(50,2);
randn(50,2)*0.5];
trueLabels = [ones(50,1); ones(50,1)*2; ones(50,1)*3];SemiSupervisedGraphModel オブジェクトの関数 predict を使用して、新しいデータのラベルを予測します。混同行列を使用して、真のラベルを予測ラベルと比較します。
predictedLabels = predict(Mdl,newX); confusionchart(trueLabels,predictedLabels)
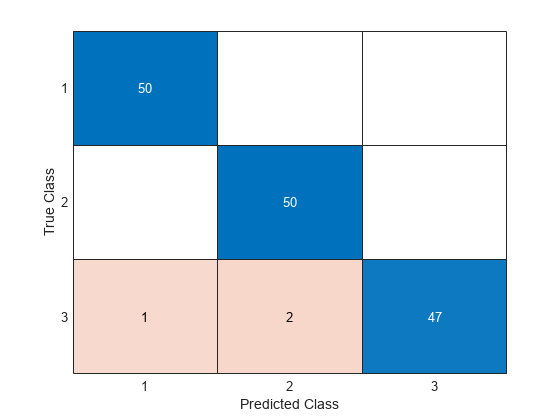
newX 内の 150 個の観測値のうち、誤りのラベルが付けられた観測値はわずか 3 個です。
入力引数
出力引数
詳細
アルゴリズム
ラベル付けされていない学習データにラベルを当てはめるために、fitsemigraph は、ラベル付けされた観測値とラベル付けされていない観測値の両方をノードとして使用して類似度グラフを作成し、ラベル伝播またはラベル拡散のいずれかを使用して、ラベル付けされた観測値からのラベル情報をラベル付けされていない観測値に分布させます。生成される SemiSupervisedGraphModel オブジェクトの FittedLabels プロパティと LabelScores プロパティに、ラベル付けされていないデータに当てはめられたラベルとラベル スコアがそれぞれ格納されます。
新しい観測値 x のラベルを予測するために、関数 predict は隣接する観測値スコアの加重平均を使用して x のラベル スコア、つまり を計算します。
Fx の最大スコアの列は、x の予測クラス ラベルに対応します。詳細は、[1]を参照してください。
参照
[1] Delalleau, Olivier, Yoshua Bengio, and Nicolas Le Roux. “Efficient Non-Parametric Function Induction in Semi-Supervised Learning.” Proceedings of the Tenth International Workshop on Artificial Intelligence and Statistics. 2005.
バージョン履歴
R2020b で導入