半教師あり学習手法を使用したデータのラベル付け
この例では、グラフベースおよび自己学習の半教師あり学習手法を使用してデータにラベルを付ける方法を示します。
半教師あり学習は、すべての学習データにラベルが付けられる教師あり学習と、真のラベルが未知である教師なし学習の特徴を組み合わせたものです。つまり、一部の学習観測値はラベル付けされていますが、大部分はラベル付けされていません。半教師あり学習手法は、データの基になっている構造を活用して、ラベル付けされていないデータにラベルを当てはめようとします。
Statistics and Machine Learning Toolbox™ には、次のような分類用の半教師あり学習関数が用意されています。
fitsemigraphは、ラベル付けされた観測値とラベル付けされていない観測値をノードとして使用して類似度グラフを作成し、ラベル付けされていない観測値に対し、ラベル付けされた観測値からラベル情報を分布させます。fitsemiselfは、データで分類器に反復的に学習させます。最初に、関数はラベル付けされたデータのみで分類器に学習させ、次にその分類器を使用してラベル付けされていないデータのラベル予測を行います。fitsemiselfは予測のスコアを提供し、スコアが特定のしきい値を超えている場合にその予測を分類器の次の学習サイクルの真のラベルとして扱います。このプロセスが、ラベル予測が収束するまで繰り返されます。
データの生成
2 つの半月形状からデータを生成します。グラフベースおよび自己学習の半教師あり手法を使用して、新しい点がどの月に属するかを判定します。
カスタム関数 twomoons (この例の終わりに掲載) を作成します。この関数は 1 つの入力引数 n を取り、組み合わされた次の 2 つの半月のそれぞれに n 個の点を作成します。上側の月は下部が凹んでおり、下側の月は上部が凹んでいます。
関数 twomoons を使用して、40 個のラベル付きデータ点から成るセットを生成します。X の各点は、2 つの月のいずれかにあり、対応する月のラベルがベクトル label に格納されています。
rng('default') % For reproducibility [X,label] = twomoons(20);
散布図を使用して点を可視化します。同じ月に属する点は同色で示します。
scatter(X(:,1),X(:,2),[],label,'filled') title('Labeled Data')

関数 twomoons を使用して、400 個のラベル付けされていないデータ点から成るセットを生成します。newX の各点は、2 つの月のいずれかに属しますが、対応する月のラベルは未知です。
newX = twomoons(200);
グラフベースの手法を使用したデータのラベル付け
グラフベースの半教師あり手法を使用して、newX のラベル付けされていないデータにラベルを付けます。既定の設定では、fitsemigraph は X および newX のデータから類似度グラフを作成し、ラベル伝播手法を使用して、newX にラベルを当てはめます。
graphMdl = fitsemigraph(X,label,newX)
graphMdl =
SemiSupervisedGraphModel with properties:
FittedLabels: [400×1 double]
LabelScores: [400×2 double]
ClassNames: [1 2]
ResponseName: 'Y'
CategoricalPredictors: []
Method: 'labelpropagation'
Properties, Methods
関数は SemiSupervisedGraphModel オブジェクトを返します。オブジェクトの FittedLabels プロパティにはラベル付けされていないデータに当てはめられたラベルが格納され、LabelScores プロパティには関連付けられたラベルのスコアが格納されます。
散布図を使用して、当てはめられたラベルの結果を可視化します。当てはめられたラベルをもとに点の色を設定し、最大のラベル スコアをもとに点の透明度を設定します。透明度が低い点には、高い信頼度のラベルを付けます。
maxGraphScores = max(graphMdl.LabelScores,[],2); rescaledGraphScores = rescale(maxGraphScores,0.05,0.95); scatter(newX(:,1),newX(:,2),[],graphMdl.FittedLabels,'filled', ... 'MarkerFaceAlpha','flat','AlphaData',rescaledGraphScores); title(["Fitted Labels for Unlabeled Data","(Graph-Based)"])

この方法では、newX の点に正確にラベルを付けているようです。2 つの月は視覚的に区別され、最も不確実であるとラベル付けされた点は 2 つの形状の境界に位置しています。
自己学習手法を使用したデータのラベル付け
自己学習の半教師あり手法を使用して、newX のラベル付けされていないデータにラベルを付けます。既定の設定では、fitsemiself は、ガウス カーネルでサポート ベクター マシン (SVM) モデルを使用して、データのラベル付けを反復的に行います。
selfSVMMdl = fitsemiself(X,label,newX)
selfSVMMdl =
SemiSupervisedSelfTrainingModel with properties:
FittedLabels: [400×1 double]
LabelScores: [400×2 double]
ClassNames: [1 2]
ResponseName: 'Y'
CategoricalPredictors: []
Learner: [1×1 classreg.learning.classif.CompactClassificationSVM]
Properties, Methods
関数は SemiSupervisedSelfTrainingModel オブジェクトを返します。オブジェクトの FittedLabels プロパティにはラベル付けされていないデータに当てはめられたラベルが格納され、LabelScores プロパティには関連付けられたラベルのスコアが格納されます。
散布図を使用して、当てはめられたラベルの結果を可視化します。前と同じように、当てはめられたラベルをもとに点の色を設定し、最大のラベル スコアをもとに点の透明度を設定します。
maxSVMScores = max(selfSVMMdl.LabelScores,[],2); rescaledSVMScores = rescale(maxSVMScores,0.05,0.95); scatter(newX(:,1),newX(:,2),[],selfSVMMdl.FittedLabels,'filled', ... 'MarkerFaceAlpha','flat','AlphaData',rescaledSVMScores); title(["Fitted Labels for Unlabeled Data","(Self-Training: SVM)"])

SVM 学習器を使用するこの手法でも、newX の点に正確にラベルを付けているようです。2 つの月は視覚的に区別され、最も不確実であるとラベル付けされた点は 2 つの形状の境界に位置しています。
しかし、一部の学習器では、ラベル付けされていないデータへのラベル付けが有効でないことがあります。たとえば、既定の SVM モデルの代わりにツリー モデルを使用して、newX のデータにラベルを付けます。
selfTreeMdl = fitsemiself(X,label,newX,'Learner','tree');
当てはめられたラベルの結果を可視化します。
maxTreeScores = max(selfTreeMdl.LabelScores,[],2); rescaledTreeScores = rescale(maxTreeScores,0.05,0.95); scatter(newX(:,1),newX(:,2),[],selfTreeMdl.FittedLabels,'filled', ... 'MarkerFaceAlpha','flat','AlphaData',rescaledTreeScores); title(["Fitted Labels for Unlabeled Data","(Self-Training: Tree)"])
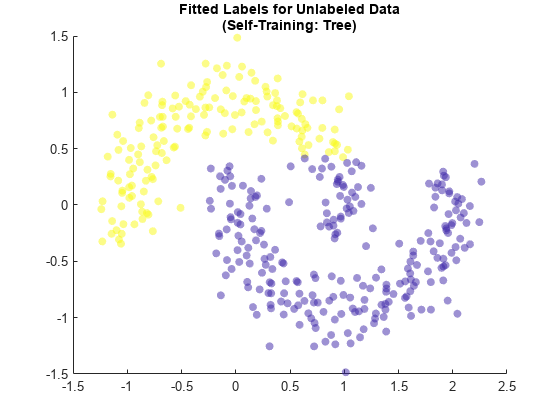
木学習器を使用したこの手法では、上側の月の点の多くに誤ったラベルが付けられています。自己学習の半教師あり手法を使用する場合、基となる学習器はデータの構造に適したものを使用するようにしてください。
次のコードは、関数 twomoons を作成します。
function [X,label] = twomoons(n) % Generate two moons, with n points in each moon. % Specify the radius and relevant angles for the two moons. noise = (1/6).*randn(n,1); radius = 1 + noise; angle1 = pi + pi/10; angle2 = pi/10; % Create the bottom moon with a center at (1,0). bottomTheta = linspace(-angle1,angle2,n)'; bottomX1 = radius.*cos(bottomTheta) + 1; bottomX2 = radius.*sin(bottomTheta); % Create the top moon with a center at (0,0). topTheta = linspace(angle1,-angle2,n)'; topX1 = radius.*cos(topTheta); topX2 = radius.*sin(topTheta); % Return the moon points and their labels. X = [bottomX1 bottomX2; topX1 topX2]; label = [ones(n,1); 2*ones(n,1)]; end