このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
detectdrift
説明
DDiagnostics = detectdrift(Baseline,Target)Baseline と Target のデータ セット間の各変数のドリフトを検出し、その結果を DDiagnostics で返します。
DDiagnostics は、DriftDiagnostics オブジェクトです。
DDiagnostics = detectdrift(Baseline,Target,Name=Value)
例
2 つの変数をもつベースライン データとターゲット データを生成します。ターゲット データで 2 つ目の変数の分布パラメーターを変化させます。
rng('default') % For reproducibility baseline = [normrnd(0,1,100,1),wblrnd(1.1,1,100,1)]; target = [normrnd(0,1,100,1),wblrnd(1.2,2,100,1)];
2 つのデータ セットを比較してドリフトを調べます。
DDiagnostics = detectdrift(baseline,target)
DDiagnostics =
DriftDiagnostics
VariableNames: ["x1" "x2"]
CategoricalVariables: []
DriftStatus: ["Stable" "Drift"]
PValues: [0.2850 0.0030]
ConfidenceIntervals: [2×2 double]
MultipleTestDriftStatus: "Drift"
DriftThreshold: 0.0500
WarningThreshold: 0.1000
Properties, Methods
DDiagnostics は DriftDiagnostics オブジェクトです。detectdrift により、いくつかのオブジェクト プロパティが表示されます。
推定 "p" 値の信頼区間を表示します。
DDiagnostics.ConfidenceIntervals
ans = 2×2
0.2572 0.0006
0.3141 0.0087
1 つ目の変数について、推定 "p" 値の信頼区間の下限が警告しきい値の 0.1 より大きくなっています。そのため、1 つ目の変数のターゲット データはベースライン データと比較して安定していると detectdrift で判定されています。2 つ目の変数については、推定 "p" 値の信頼区間の上限がドリフトしきい値の 0.05 より小さくなっています。そのため、この変数のドリフト ステータスは Drift になります。これは、分布パラメーターにおけるシフトが detectdrift で検出されたことを示します。
detectdrift は、既定では多重仮説検定にボンフェローニの方法を使用します。関数は最初に警告しきい値とドリフトしきい値を "p" 値の数 (この例では 2) で除算します。その後、そのいずれかのしきい値よりも低い "p" 値があるかどうかを調べます。ここでは、2 つ目の "p" 値が修正後のドリフトしきい値よりも低いため、関数はデータ全体の MultipleTestDriftStatus を Drift に設定しています。
両方の変数について、順列の結果を可視化します。
tiledlayout(2,1); ax1 = nexttile; plotPermutationResults(DDiagnostics,ax1,Variable="x1") ax2 = nexttile; plotPermutationResults(DDiagnostics,ax2,Variable="x2")
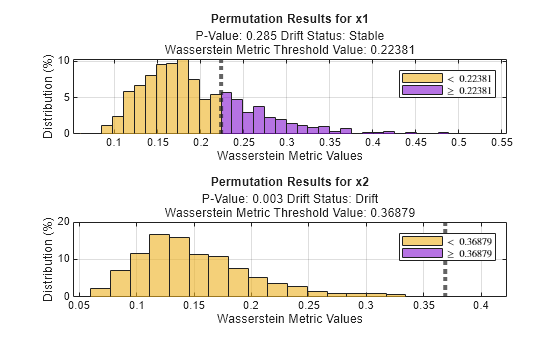
破線より右にあるバーは、しきい値を超えているメトリクス値を示しています。このしきい値は、ベースライン データとターゲット データを使用して detectdrift で計算される各変数の初期メトリクス値です。変数 x1 ではしきい値を超えているバーの数がはるかに多く、この変数についてはベースライン データとターゲット データの間に大きなドリフトがないことを示しています。
標本データを読み込みます。
load humanactivityデータ セットの詳細については、コマンド ラインで Description を入力してください。
最初の 250 個の観測値をベースライン データとして割り当て、次の 250 個をターゲット データとして割り当てます。
baseline = feat(1:250,:); target = feat(251:500,:);
警告しきい値 0.05 とドリフトしきい値 0.01 を使用して、5 番目から 10 番目までの変数についてドリフトを検定します。いずれも連続変数であるため、すべての変数にコルモゴロフ・スミルノフ メトリクスを使用します。多重検定補正として偽発見率法を指定します。
DDiagnostics = detectdrift(baseline(:,5:10),target(:,5:10),WarningThreshold=0.05, ... DriftThreshold=0.01,ContinuousMetric="ks",MultipleTestCorrection="fdr")
DDiagnostics =
DriftDiagnostics
VariableNames: ["x1" "x2" "x3" "x4" "x5" "x6"]
CategoricalVariables: []
DriftStatus: ["Drift" "Drift" "Drift" "Stable" "Warning" "Drift"]
PValues: [1.0000e-03 1.0000e-03 1.0000e-03 0.8810 0.0110 1.0000e-03]
ConfidenceIntervals: [2×6 double]
MultipleTestDriftStatus: "Drift"
DriftThreshold: 0.0100
WarningThreshold: 0.0500
Properties, Methods
推定 "p" 値の信頼区間を表示します。
DDiagnostics.ConfidenceIntervals
ans = 2×6
0.0000 0.0000 0.0000 0.8593 0.0055 0.0000
0.0056 0.0056 0.0056 0.9004 0.0196 0.0056
8 番目の変数 (変数名 x4) について、"p" 値の信頼限界の下限が警告しきい値より大きくなっています。そのため、detectdrift はこの変数のドリフト ステータスを "Stable" と判定しています。9 番目の変数 (変数名 x5) については、"p" 値の信頼限界の上限がドリフトしきい値より大きくなっていますが、警告しきい値よりは低くなっています。そのため、detectdrift はこの変数のドリフト ステータスを "Warning" と判定しています。他のすべての変数については、信頼区間がドリフトしきい値より小さいため、ドリフト ステータスは "Drift" です。多重検定補正の偽発見率法に基づいて、関数はデータ全体についてのドリフト ステータスを "Drift" と判定しています。
"p" 値と信頼区間を対応するドリフト ステータスと共に可視化します。
plotDriftStatus(DDiagnostics)
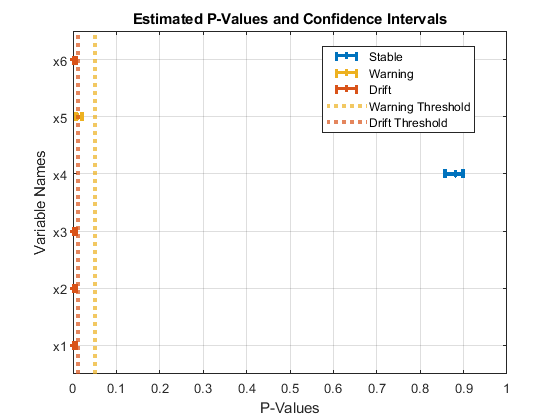
警告しきい値とドリフトしきい値に対する推定 "p" 値と信頼区間のプロットが表示されます。変数 x4 の推定 "p" 値とその信頼区間は警告しきい値より高くなっています。そのため、この変数のドリフト ステータスは "Stable" になります。x5 については、"p" 値の信頼限界の上限がドリフトしきい値より大きくなっていますが、警告しきい値よりは低くなっています。そのため、この変数のドリフト ステータスは "Warning" になります。他のすべての変数については、信頼区間がドリフトしきい値より小さいため、ドリフト ステータスは "Drift" です。
データ セット NYCHousing2015 を読み込みます。
load NYCHousing2015データ セットには、2015 年のニューヨーク市における不動産の売上に関する情報を持つ 10 の変数が含まれます。
外れ値を削除し、datetime 配列 (SALEDATE) を月番号に変換します。
idx = isoutlier(NYCHousing2015.SALEPRICE); NYCHousing2015(idx,:) = []; NYCHousing2015.SALEDATE = month(NYCHousing2015.SALEDATE);
1 月と 7 月の売上に関する情報としてベースライン データとターゲット データをそれぞれ定義します。
tbl = NYCHousing2015; baseline = tbl(tbl.SALEDATE==1,:); target = tbl(tbl.SALEDATE==7,:);
データをシャッフルします。
n = numel(baseline(:,1));
rng(1); % For reproducibility
idx = randsample(n,n);
baseline = baseline(idx,:);
n = numel(target(:,1));
idx = randsample(n,n);
target = target(idx,:);ベースライン データとターゲット データの間の潜在的なドリフトを検定します。カテゴリカル変数と各変数で使用するメトリクスを指定します。
DDiagnostics = detectdrift(baseline(1:1500,:),target(1:1500,:), ... VariableNames=["BOROUGH","BUILDINGCLASSCATEGORY","LANDSQUAREFEET","GROSSSQUAREFEET","SALEPRICE"], ... CategoricalVariables=["BOROUGH","BUILDINGCLASSCATEGORY"], ... Metrics=["Hellinger","Hellinger","ad","ks","energy"])
DDiagnostics =
DriftDiagnostics
VariableNames: ["BOROUGH" "BUILDINGCLASSCATEGORY" "LANDSQUAREFEET" "GROSSSQUAREFEET" "SALEPRICE"]
CategoricalVariables: [1 2]
DriftStatus: ["Drift" "Stable" "Drift" "Drift" "Drift"]
PValues: [0.0260 0.1440 0.0070 0.0230 0.0110]
ConfidenceIntervals: [2×5 double]
MultipleTestDriftStatus: "Drift"
DriftThreshold: 0.0500
WarningThreshold: 0.1000
Properties, Methods
detectdrift により、BUILDINGCLASSCATEGORY を除くすべての変数について、ベースライン データとターゲット データの間でドリフトが識別されています。
推定 "p" 値の信頼区間を表示します。
DDiagnostics.ConfidenceIntervals
ans = 2×5
0.0171 0.1228 0.0028 0.0146 0.0055
0.0379 0.1673 0.0144 0.0343 0.0196
SALEPRICE のヒストグラムをプロットします。
plotHistogram(DDiagnostics,Variable="SALEPRICE")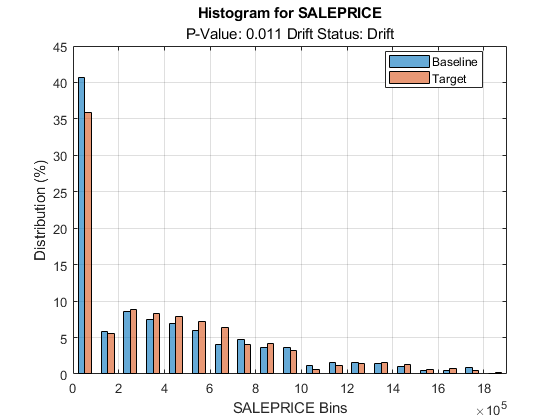
1 月と比較した 7 月の売価のシフトがヒストグラムに表示されます。
SALEPRICE のベースライン データとターゲット データについての経験累積分布関数をプロットします。
plotEmpiricalCDF(DDiagnostics,Variable="SALEPRICE")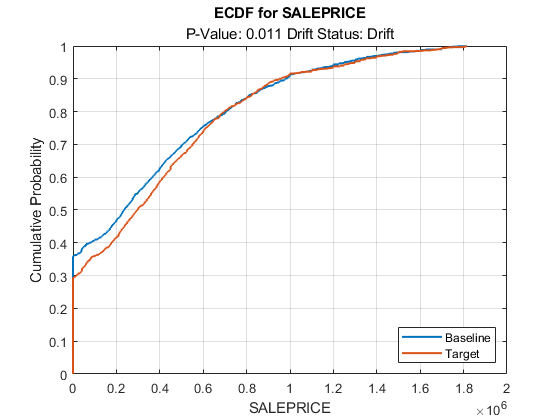
SALEPRICE の順列の結果をプロットします。
plotPermutationResults(DDiagnostics,Variable="SALEPRICE")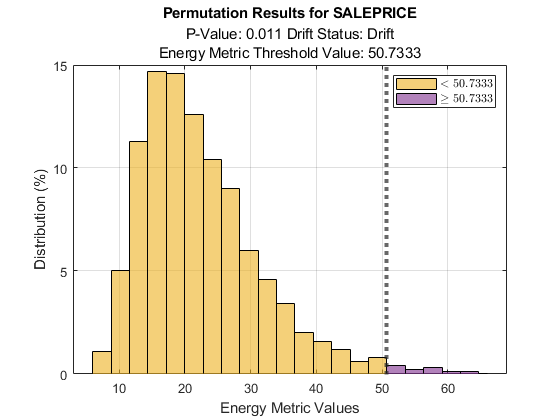
3 つの変数をもつベースライン データとターゲット データを生成します。ターゲット データで 2 つ目と 3 つ目の変数の分布パラメーターを変化させます。
rng('default') % For reproducibility baseline = [normrnd(0,1,100,1),wblrnd(1.1,1,100,1),betarnd(1,2,100,1)]; target = [normrnd(0,1,100,1),wblrnd(1.2,2,100,1),betarnd(1.7,2.8,100,1)];
"p" 値を推定せずに、ベースライン データとターゲット データの間ですべての変数の初期メトリクスを計算します。
DDiagnostics = detectdrift(baseline,target,EstimatePValues=false)
DDiagnostics =
DriftDiagnostics
VariableNames: ["x1" "x2" "x3"]
CategoricalVariables: []
Metrics: ["Wasserstein" "Wasserstein" "Wasserstein"]
MetricValues: [0.2022 0.3468 0.0559]
Properties, Methods
detectdrift により、ベースライン データとターゲット データを使用して各変数の初期メトリクス値のみが計算されます。並べ替え検定および "p" 値の推定に関連付けられたプロパティについては、空になるか NaN が格納されます。
summary(DDiagnostics)
MetricValue Metric
___________ _____________
x1 0.20215 "Wasserstein"
x2 0.34676 "Wasserstein"
x3 0.055922 "Wasserstein"
関数 summary により、初期メトリクス値と指定した各変数に使用されるメトリクスのみが表示されます。
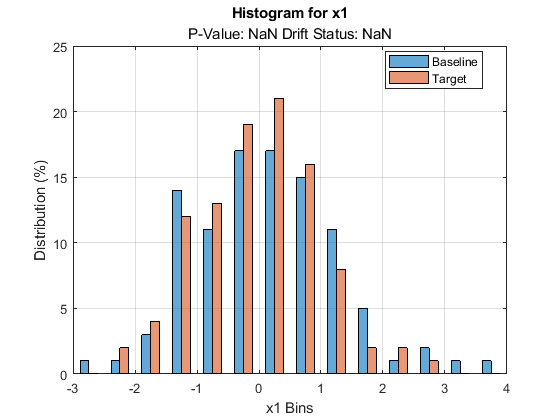
plotDriftStatus と plotPermutationResults では、"p" 値を推定せずにメトリクスを計算すると、プロットが生成されずに警告メッセージが返されます。plotEmpiricalCDF と plotHistogram では、既定では 1 つ目の変数についての ecdf とヒストグラムがそれぞれプロットされます。どちらの場合も、"p" 値および変数に関連付けられているドリフト ステータスについては NaN が返されます。
plotEmpiricalCDF(DDiagnostics)
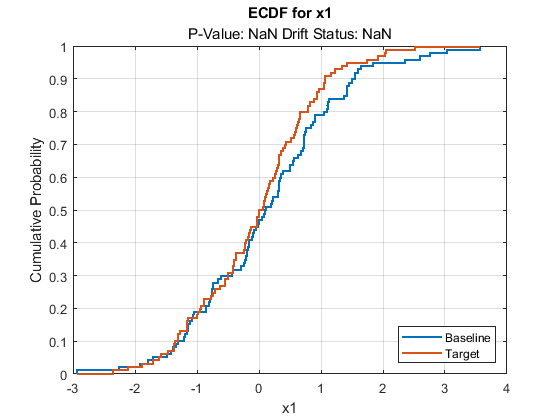
plotHistogram(DDiagnostics)
入力引数
名前と値の引数
出力引数
アルゴリズム
参照
[1] Hesterbeg,Tim, David S. Moore, Shaun Monaghan, Ashley Clipson, and Rachel Epstein. "Bootstrap Methods and Permutation Tests" in Introduction to the Practice of Statistics. 7th ed, W.H. Freeman, pp. 1–57, 2010.
[2] Benjamini, Yoav, and Yosef Hochberg. "Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing." Journal of the Royal Statistical Society, Series B (Methodological). Vol. 57, No. 1, pp. 289-300, 1995.
[3] Villani, Cédric. Topics in Optimal Transportation. Graduate Studies in Mathematics. Vol. 58, American Mathematical Society, 2000.
[4] Deza, Elena, and Michel Marie Deza. Encyclopedia of Distances, Springer Berlin Heidelberg, 2009.
拡張機能
バージョン履歴
R2022a で導入