crosstab
クロス集計
構文
説明
tbl = crosstab(___,Name=Value)
例
異なる 3 つの値と 4 つの値を含む 2 つの標本データ ベクトルを作成します。
x = [1 1 2 3 1]; y = [1 2 5 3 1];
x と y をクロス集計します。
table = crosstab(x,y)
table = 3×4
2 1 0 0
0 0 0 1
0 0 1 0
table の行は x の 3 つの異なる値に対応し、列は y の 4 つの異なる値に対応しています。
2 つの独立したベクトル x1 および x2 を生成します。各ベクトルは 1:3 の範囲で離散一様分布する 50 個の乱数を含んでいます。
rng default; % for reproducibility x1 = unidrnd(3,50,1); x2 = unidrnd(3,50,1);
x1 と x2 をクロス集計します。
[table,chi2,p] = crosstab(x1,x2)
table = 3×3
1 6 7
5 5 2
11 7 6
chi2 = 7.5449
p = 0.1097
返される p 値は 0.1097 です。これは 5% の有意水準において、table が各次元で独立しているという帰無仮説を、crosstab が棄却できないことを示しています。
標本データを読み込みます。1970 ~ 1982 年の間の大型自動車に関する測定値が含まれています。
load carbigモデルの年度 (when) と生産国 (org) に基づいて 4 気筒の自動車 (cyl4) のデータをクロス集計します。
[table,chi2,p,labels] = crosstab(cyl4,when,org);
labels を使用して、データの期間の後半に米国で製造された 4 気筒の自動車の台数に対する table のインデックスの位置を特定します。
labels
labels=3×3 cell array
{'Other' } {'Early'} {'USA' }
{'Four' } {'Mid' } {'Europe'}
{0×0 double} {'Late' } {'Japan' }
labels の最初の列は cyl4 のデータに対応し、table の行 2 に4 気筒の自動車のデータが格納されていることを示しています。labels の 2 番目の列は when のデータに対応し、期間の後半に製造された自動車のデータは、table の列 3 に格納されていることを示しています。labels の 3 番目の列は org のデータに対応し、米国で製造された自動車のデータは table の 3 番目の次元の位置 1 に格納されていることを示しています。
つまり、table(2,3,1) には、期間の後半に米国で製造された 4 気筒の自動車の台数が格納されていることになります。
table(2,3,1)
ans = 38
このデータは、期間の後半に米国で製造された 4 気筒の自動車が 38 台であることを示しています。
グループ化変数を読み込み、グループ化変数の table を表示します。
load grouping_variables.mat
datatbldatatbl=4×3 table
x y z
___ ___ ___
NaN NaN 5
5 1 5
1 2 1
5 3 NaN
datatbl は、x、y、z の 3 つのグループ化変数の値が格納された table です。3 つのすべての変数に NaN 値が含まれています。
datatbl のグループ化変数を使用してクロス集計表を生成します。NaN のエントリのカウントを含めます。
tbl = crosstab(datatbl,IncludeMissingGroups=true)
tbl=36×4 table
x y z Counts
___ ___ _ ______
1 1 1 0
5 1 1 0
NaN 1 1 0
1 2 1 1
5 2 1 0
NaN 2 1 0
1 3 1 0
5 3 1 0
NaN 3 1 0
1 NaN 1 0
5 NaN 1 0
NaN NaN 1 0
1 1 5 0
5 1 5 1
NaN 1 5 0
1 2 5 0
⋮
クロス集計表 tbl には、NaN 値を含むグループ化変数の値の一意の組み合わせごとに、それぞれのカウントが含まれています。table の各行が一意の組み合わせに対応し、最後の列にそれぞれの組み合わせのカウントが格納されます。
データから分割表を作成し、ヒートマップ チャートで table を可視化します。
病院データを読み込みます。
load hospitalhospital データセット配列には病院患者 100 人の、姓、性別、年齢、体重、喫煙状況、収縮期および拡張期の血圧測定値を含めたデータがあります。
データ セット配列を MATLAB® table に変換します。
Tbl = dataset2table(hospital);
喫煙者と非喫煙者を性別でグループ化した 2 行 2 列の分割表を作成し、喫煙状況が性別と独立しているかどうかを判定します。
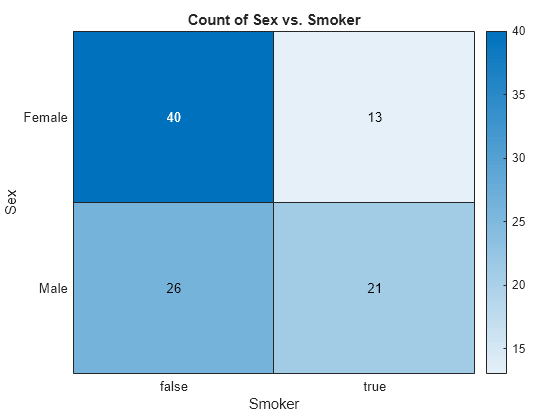
[conttbl,chi2,p,labels] = crosstab(Tbl.Sex,Tbl.Smoker)
conttbl = 2×2
40 13
26 21
chi2 = 4.5083
p = 0.0337
labels = 2×2 cell
{'Female'} {'0'}
{'Male' } {'1'}
生成される分割表 conttbl の行は患者の性別に対応し、行 1 には女性、行 2 には男性のデータが含まれています。列は患者の喫煙状況に対応し、列 1 には非喫煙者、列 2 には喫煙者のデータが含まれています。返された結果 chi2 = 4.5083 は独立性に対するピアソンのカイ二乗検定のカイ二乗検定統計量の値です。検定の 値は p = 0.0337 です。これは 5% の有意水準において、性別と喫煙状況が独立しているという帰無仮説を棄却できることを示しています。
ヒートマップで分割表を可視化します。 軸上に喫煙状況をプロットし、 軸上に性別をプロットします。
heatmap(Tbl,'Smoker','Sex')
入力引数
名前と値の引数
出力引数
アルゴリズム
crosstabはgrp2idxを使用して正の整数を異なる値に割り当てます。tbl(i,j)はインデックス数です。ここでgrp2idx(x1)はiで、grp2idx(x2)はjです。grp2idx(x1)とgrp2idx(x2)の数値順序がtblの行と列の順序を決めます。この場合、
tbl(i,j,...,n)の返された値はインデックス数です。ここで、grp2idx(x1)はi、grp2idx(x2)はj、grp2idx(x3)はk、以降も同様です。crosstabは、大きな標本サイズに対して漸近的に有効な式を使用して、カイ二乗検定統計量の p 値を計算します。小さい標本、または極めて不均等な周辺分布をもつ標本の場合、近似の精度は低くなります。標本に変数が 2 つしか含まれておらず、各変数に 2 つの水準がある場合、代わりにfishertestを使用できます。この関数は、フィッシャーの正確確率検定を実行するもので、大きな標本分布の仮定に依存しません。