andrewsplot
アンドリュース プロット
説明
andrewsplot( は、行列 X)X に多変量データのアンドリュース プロットを作成します。このプロットは、X 内の各観測値の連続的な曲線を表示します。詳細については、アンドリュース プロットを参照してください。
andrewsplot( は、1 つ以上の名前と値の引数を使用して追加オプションを指定します。たとえば、プロットの前に X,Name=Value)X 内のデータを標準化したり、グループ化変数を使用してデータをグループ化したりできます。
andrewsplot( は、ターゲットの座標軸 ax,___)ax にプロットを表示します。前述の任意の構文で、最初の入力引数として座標軸を指定します。
p = andrewsplot(___)Line オブジェクトの配列を返します。p は、プロットの作成後にそのプロパティを変更する場合に使用します。プロパティの一覧については、Line のプロパティを参照してください。
例
グループ化された標本データを可視化するためにアンドリュース プロットを作成します。
fisheriris データ セットを読み込みます。このデータ セットには、3 つの種のアヤメの花による 4 種類の測定値 (萼弁の長さ、萼弁の幅、花弁の長さ、花弁の幅) が含まれています。
load fisheriris行列 meas には、150 本の花についての 4 つの測定値すべてが格納されています。cell 配列 species には、150 本の花のそれぞれに対する種の名前が格納されています。
標本データを species でグループ化してアンドリュース プロットを作成します。
andrewsplot(meas,Group=species)
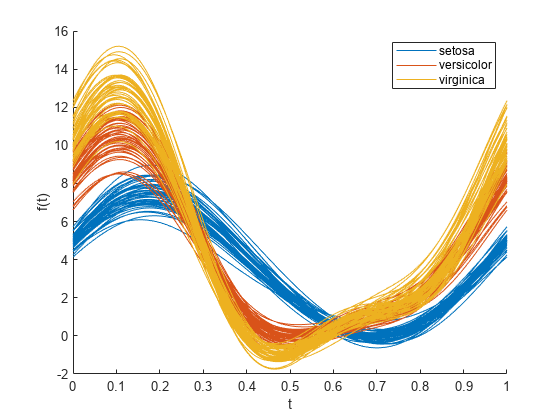
このプロットは、区間 [0,1] における平滑化関数として各観測値 (花) を表示します。各曲線の色は花の種を示します。
グループごとの中央値と四分位数のみを表示する単純化した 2 つ目のアンドリュース プロットを作成します。
andrewsplot(meas,Group=species,Quantile=0.25)
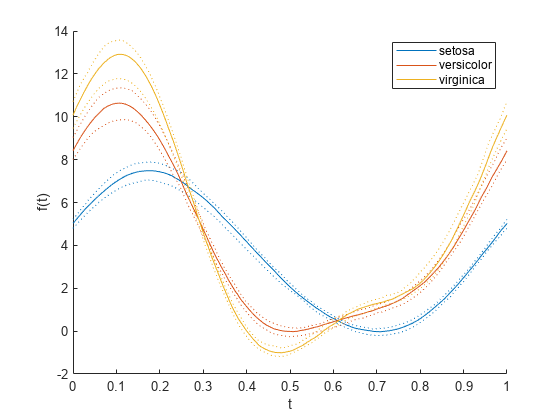
プロットでは、各グループの中央値が実線の曲線で、他の四分位数の値が同じ色の点線の曲線で示されています。
アンドリュース プロットを使用して多次元データを可視化します。まず、データをグループ化します。次に、標準化と四分位数を使用してグループの差異を確認します。
100 人の患者の医療情報を含む patients データ セットを読み込みます。1 と 0 の代わりに、Smoker と Nonsmoker というわかりやすいカテゴリ名を指定します。次に、Diastolic、Systolic、Weight、Age、および Smoker 変数を使用して table を作成します。
load patients Smoker = categorical(Smoker,logical([1 0]), ... ["Smoker","Nonsmoker"]); patientData = table(Diastolic,Systolic,Weight,Age,Smoker);
patientData の変数からアンドリュース プロットを作成します。最後の変数を使用して、データを喫煙状況ごとにグループ化します。
andrewsplot(patientData{:,1:end-1},Group=patientData.Smoker)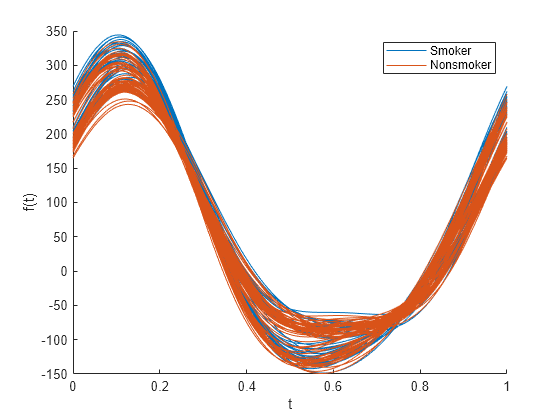
既定では、プロットは標準化されていないデータを使用します。このプロットでは、Smoker グループと Nonsmoker グループの間に大きな差異は示されません。
プロットの前に patientData 数値変数を標準化します。
andrewsplot(patientData{:,1:end-1},Group=Smoker,Standardize="on")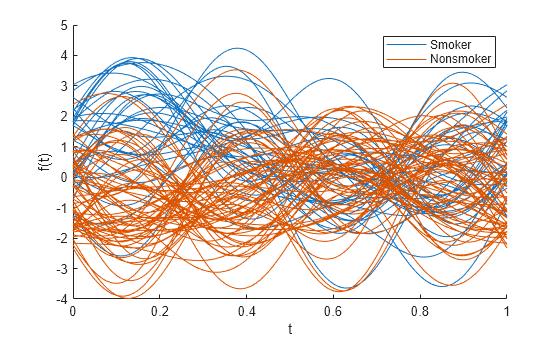
結果のアンドリュース プロットでは、Smoker グループと Nonsmoker グループの差異がより明確に示されます。このプロットは、patientData の患者ごとに 1 つずつ、100 個の曲線を示しているため、若干込み合っています。
各観測値の曲線を表示する代わりに、各グループの四分位数の曲線を示します。四分位数は、25 番目の百分位数、中央値、および 75 番目の百分位数で構成されます。
andrewsplot(patientData{:,1:end-1},Group=patientData.Smoker, ...
Standardize="on",Quantile=0.25)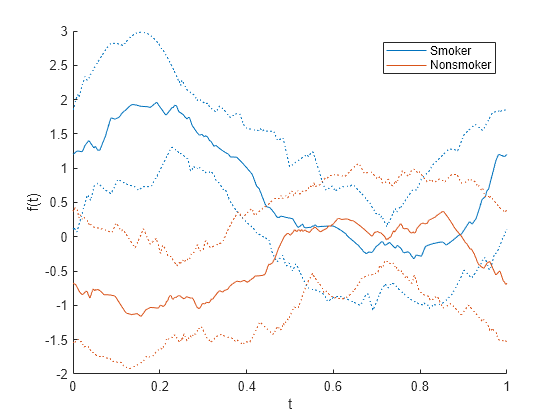
四分位数の曲線は、Smoker グループと Nonsmoker グループの差異を示しています。たとえば、約 0.25 の時点では、2 つのグループの四分位数の値は重なっていません。
アンドリュース プロットに表示されていた各関数は、係数が時間と共に変化する変数の線形結合であることを思い出してください。(アンドリュース プロットを参照。)時間 0.25 における変数の係数を計算します。この変数の線形結合はグループの区別に役立ちます。
t = 0.25; variables = patientData.Properties.VariableNames(1:end-1)
variables = 1×4 cell
{'Diastolic'} {'Systolic'} {'Weight'} {'Age'}
coefficients = [1/sqrt(2) sin(2*pi*t) cos(2*pi*t) sin(4*pi*t)]
coefficients = 1×4
0.7071 1.0000 0.0000 0.0000
時間 0.25 では、Diastolic 変数と Systolic 変数の係数は振幅が類似している正の係数で、Weight 変数と Age 変数の係数は 0 です。前のプロットは、データの標準化後に、Smoker グループの四分位数の曲線が時間 0.25 で正の値になり、Nonsmoker グループの四分位数の曲線が時間 0.25 で負の値になることを示しています。
プロットと変数の係数は、Smoker グループの患者は Diastolic と Systolic の値が高くなる傾向があることを示しており、これは patientData の Smoker グループと Nonsmoker グループを区別する方法の 1 つとなります。
アンドリュース プロットの外観を調整します。andrewsplot の呼び出しでいくつかのプロット プロパティを設定できます。プロットの作成前または作成後にその外観を指定することもできます。
fisheriris データ セットを読み込みます。このデータ セットには、3 つの種のアヤメの花による 4 種類の測定値 (萼弁の長さ、萼弁の幅、花弁の長さ、花弁の幅) が含まれています。
load fisheriris行列 meas には、150 本の花についての 4 つの測定値すべてが格納されています。cell 配列 species には、150 本の花のそれぞれに対する種の名前が格納されています。
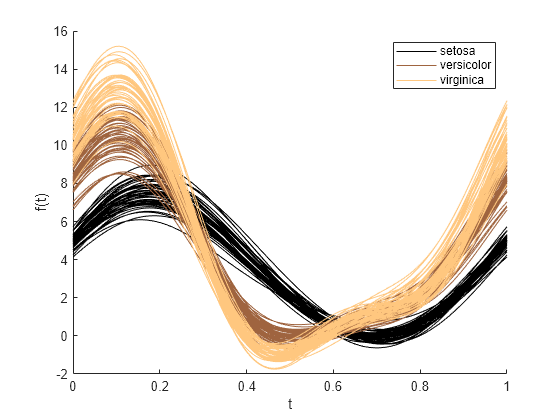
meas 内の測定値データと species 内のグループ データを使用してアンドリュース プロットを作成します。プロットの前に色の順序を設定し、グループ化されたデータの既定以外の配色 (copper) を指定します。
colororder(copper(3)) andrewsplot(meas,Group=species)
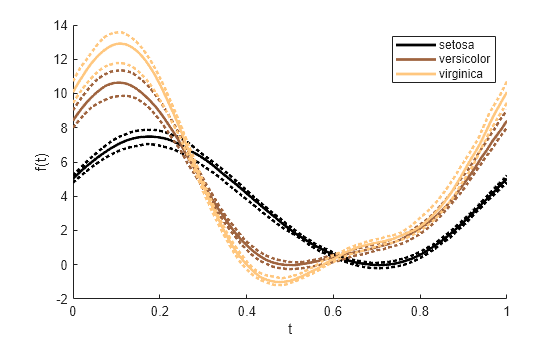
species の各グループについて、中央値、25 番目の百分位数、および 75 番目の百分位数の曲線のみをプロットします。プロット ラインを太くするために、ライン幅を 2 と指定します。andrewsplot の呼び出しで LineWidth の値を指定すると、この関数はプロット内のすべての曲線のライン幅を同じ値に設定します。
andrewsplot(meas,Group=species,Quantile=0.25,LineWidth=2)
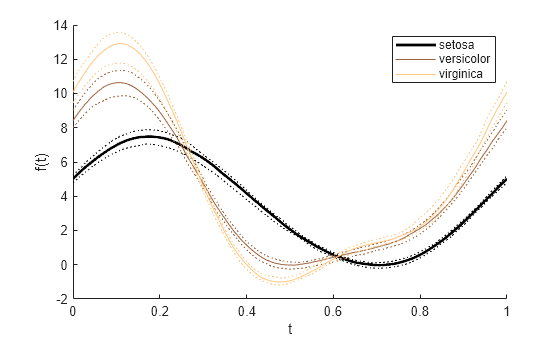
前のプロットを再作成します。ただし、setosa グループのアヤメに対する中央値の測定値を表す曲線のみ、ライン幅を太くします。まず、Line オブジェクトの配列 p を作成します。各オブジェクトはプロット内の曲線に対応します。次に、ドット表記を使用して、配列に含まれる最初の Line オブジェクトの LineWidth プロパティを変更します。
p = andrewsplot(meas,Group=species,Quantile=0.25)
p = 9×1 Line array: Line (median) Line (lower quantile) Line (upper quantile) Line (median) Line (lower quantile) Line (upper quantile) Line (median) Line (lower quantile) Line (upper quantile)
p(1).LineWidth = 2;
入力引数
名前と値の引数
出力引数
詳細
ヒント
Line のプロパティ に記載されているプロパティの場合、プロパティの名前と値を指定することによりプロットする曲線の特性を変更できます。しかし、このアプローチではプロット内の曲線すべてに変更が適用されます。プロットする特定の曲線のみを変更するには、
Lineオブジェクトを返す構文を使用し、ドット表記を使用して各オブジェクトのプロパティを個別に調整します。例については、プロットの外観の調整を参照してください。
バージョン履歴
R2006a より前に導入