強化学習デザイナーを使用したエージェントの設計と学習
この例では、強化学習デザイナーを使用して、離散行動空間をもつ環境用の DQN エージェントの設計および学習を行う方法を示します。
強化学習デザイナー アプリを開く
強化学習デザイナー アプリを開きます。
reinforcementLearningDesigner

初期状態では、アプリにエージェントや環境が読み込まれていません。
カートポール環境のインポート
強化学習デザイナーを使用する場合、MATLAB® ワークスペースから環境をインポートしたり、事前定義済みの環境を作成したりできます。詳細については、強化学習デザイナーでの MATLAB 環境の読み込みと強化学習デザイナーでの Simulink 環境の読み込みを参照してください。
この例では、事前定義済みの離散カートポール MATLAB 環境を使用します。この環境をインポートするには、[強化学習] タブの [環境] セクションで [新規]、[離散型カート ポール] を選択します。

アプリの [環境] ペインに、インポートした Discrete CartPole 環境が追加されます。環境の名前を変更するには、環境のテキストをクリックします。セッション内に複数の環境をインポートすることもできます。
観測空間と行動空間の次元を表示するには、環境のテキストをクリックします。アプリの [プレビュー] ペインに次元が表示されます。
![The Preview pane shows the dimensions of the state and action spaces being [4 1] and [1 1], respectively](app_dqn_cartpole_03b.png)
この環境には、連続した 4 次元の観測空間 (カートとポール両方の位置と速度) と、取り得る 2 つの力 (-10 N または 10 N) で構成される離散的な 1 次元の行動空間があります。この環境は、離散カートポールの平衡化のための既定の DQN エージェントの学習の例で使用されています。事前定義済み制御システム環境の詳細については、Use Predefined Control System Environmentsを参照してください。
インポートされた環境用の DQN エージェントの作成
エージェントを作成するには、[強化学習] タブの [エージェント] セクションで [新規] をクリックします。[エージェントの作成] ダイアログ ボックスで、エージェント名、環境、学習アルゴリズムを指定します。既定のエージェント構成では、インポートされた環境と DQN アルゴリズムが使用されます。この例では、隠れユニットの数を 256 から 20 に変更します。エージェントの作成の詳細については、Create Agents Using Reinforcement Learning Designerを参照してください。

[OK] をクリックします。
アプリは新しいエージェントを [エージェント] ペインに追加し、対応する [agent1] ドキュメントを開きます。
[ハイパーパラメーター] セクションの [クリティック オプティマイザーのオプション] で [学習率] を 0.0001 に設定します。

DQN エージェントの機能の概要を確認し、エージェントの観測仕様とアクション仕様を表示するには、[概要] をクリックします。

強化学習デザイナーで DQN エージェントを作成すると、エージェントは既定の深層ニューラル ネットワーク構造をそのクリティックに使用します。クリティック ネットワークを表示するには、[DQN エージェント] タブの [クリティック] で [ネットワークの解析] を選択します。
深層学習ネットワーク アナライザーが開き、クリティックの構造が表示されます。

深層学習ネットワーク アナライザーを閉じます。
代わりに、既存のネットワークを変更するには、[DQN エージェント] タブの [クリティック] で [ネットワークのカスタマイズ] を選択します。
ディープ ネットワーク デザイナーが開き、クリティックの構造が表示されます。ユーザーはこの構造を変更することができます。
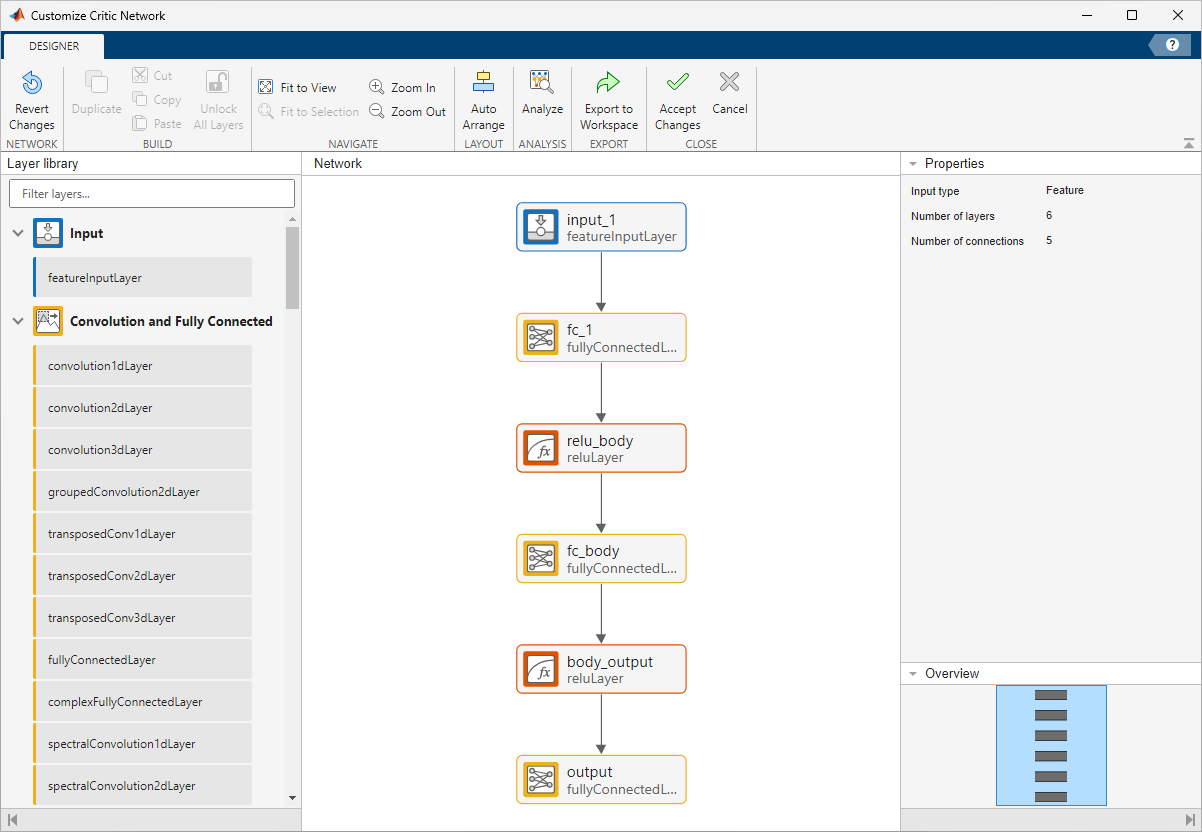
ディープ ネットワーク デザイナーを閉じます。
エージェントの学習
エージェントに学習させるには、[学習] タブで、エージェントに学習させるためのオプションをまず指定します。学習オプションの指定については、Specify Simulation Options in Reinforcement Learning Designerを参照してください。
この例では、[最大エピソード数] を 1000 に設定して学習エピソードの最大数を指定します。他の学習オプションについては、既定値を使用します。既定の停止条件は、エピソードごとの平均ステップ数 (過去 5 エピソードにわたる) が 500 を超えた場合です。

学習を開始するには、[学習] をクリックします。
学習が実行されている間、アプリは [学習セッション] タブを開き、[学習結果] ドキュメントに学習の進行状況を表示します。
学習中はいつでも、[停止] または [学習を停止] ボタンをクリックして学習を中断し、コマンド ラインで他の操作を実行できます。

このとき、[学習セッション] タブの [再開]、[確定]、および [キャンセル] ボタンで、学習を再開するか、学習結果を確定するか (学習結果と学習済みのエージェントがアプリに保存される)、学習を完全にキャンセルするかを選択できます。
学習を再開するには、[再開] をクリックします。

ここで、学習は、エピソードあたりの平均ステップ数が 500 になったときに停止します。
メモ
学習の履歴と結果は、ハードウェア、ソフトウェア、および乱数発生器の具体的な構成によって異なるため、完全に再現できるとは限りません。詳細については、Results Reproducibilityを参照してください。
学習結果を確定するには、[確定] をクリックします。アプリの [エージェント] ペインに、学習済みエージェント agent1_Trained が追加されます。
エージェントのシミュレーションおよびシミュレーション結果の検証
学習済みのエージェントをシミュレーションするには、[シミュレーション] タブで、[エージェント] ドロップダウン リストの agent1_Trained を選択してから、シミュレーション オプションを設定します。この例では、既定のエピソード数 (10) と最大エピソード長 (500) を使用します。シミュレーション オプションの指定の詳細については、Specify Simulation Options in Reinforcement Learning Designerを参照してください。

エージェントをシミュレーションするには、[シミュレーション] をクリックします。
アプリで [シミュレーション セッション] タブが開きます。シミュレーションが完了すると、[シミュレーション結果] ドキュメントに各エピソードの報酬および報酬の平均値と標準偏差が表示されます。

3 つのエピソードで、エージェントは最大報酬の 500 に到達できませんでした。これは、学習済みエージェントのロバスト性がさまざまな初期条件に対して向上する可能性があることを示唆しています。この場合、たとえば [ウィンドウの長さの平均] を 5 ではなく 10 に選択するなどしてエージェントに長く学習させることで、より優れたロバスト性が得られます。また、BatchSize や TargetUpdateFrequency などの一部の DQN エージェント オプションを変更して、より高速でロバストな学習を促進することもできます。
シミュレーション結果を解析するには、[シミュレーション データの検証] をクリックします。これにより、シミュレーション データ インスペクターが開きます。詳細については、シミュレーション データ インスペクター (Simulink)を参照してください。
また、前のセッションで読み込んだ可能性のあるデータをシミュレーション データ インスペクターから事前にクリアするオプションもあります。これを行うには、[シミュレーション データの検証] で [シミュレーション データのクリアおよび検証] を選択します。

シミュレーション データ インスペクターでは、各シミュレーション エピソードのために保存された信号を表示できます。
既定では、上部のプロット領域が選択されています。最初のエピソード中の最初の状態 (カートの位置) を表示するには、[Run 1: Simulation Result] をクリックし、変数 CartPoleStates を開いて CartPoleStates(1,1) を選択します。カートが約 390 秒後に境界の外に出たため、シミュレーションが終了しました。

上部のプロット領域にも報酬を表示するには、変数 Reward を選択します。縦軸の単位もそれに応じて変化することに注意してください。
中央のプロット領域をクリックし、3 番目の状態 (ポールの角度) を選択します。次に、下部の領域をクリックして 2 番目と 4 番目の状態 (カートの速度とポールの角度の微分) を選択します。

同じ環境で DQN エージェントに学習させる関連する例については、離散カートポールの平衡化のための既定の DQN エージェントの学習を参照してください。
シミュレーション データ インスペクターを閉じます。
シミュレーション結果を確定するには、[シミュレーション セッション] タブで [確定] をクリックします。
アプリの [結果] ペインに、シミュレーション結果の構造体 experience1 が追加されます。
エージェントのエクスポートおよびセッションの保存
学習済みのエージェントを選択し、対応する [agent1_Trained] ドキュメントを開くには、[エージェント] ペインで agent1_Trained をダブル クリックします。

次に、学習済みのエージェントを MATLAB ワークスペースにエクスポートするには、[強化学習] タブの [エクスポート] で学習済みのエージェントを選択します。

アプリのセッションを保存するには、[強化学習] タブで [セッションを保存] をクリックします。今後、中断したところから作業を再開するには、強化学習デザイナーでセッションを開くことができます。
コマンド ラインでのエージェントのシミュレーション
MATLAB コマンド ラインでエージェントをシミュレーションするには、まずカートポール環境を読み込みます。
env = rlPredefinedEnv("CartPole-Discrete");このカートポール環境は、シミュレーション中や学習中にシステムがどのように動作するかを確認できる環境ビジュアライザーを備えています。
環境をプロットし、アプリから前回エクスポートした学習済みエージェントを使用してシミュレーションを実行します。
plot(env) xpr2 = sim(env,agent1_Trained);
シミュレーション中、ビジュアライザーはカートとポールの動きを表示します。このシミュレーションでは、学習済みのエージェントがシステムを安定させることができています。

最後に、シミュレーションの累積報酬を表示します。
sum(xpr2.Reward)
env = 500
予想どおり、累計報酬は 500 です。
参考
アプリ
関数
トピック
- 離散カートポールの平衡化のための既定の DQN エージェントの学習
- Tune Hyperparameters Using Reinforcement Learning Designer
- ディープ ネットワーク デザイナーを使用した DQN エージェントの作成およびイメージ観測値を使用した学習
- 強化学習デザイナーでの MATLAB 環境の読み込み
- 強化学習デザイナーでの Simulink 環境の読み込み
- Create Agents Using Reinforcement Learning Designer
- Specify Training Options in Reinforcement Learning Designer
- Specify Simulation Options in Reinforcement Learning Designer
- 深層 Q ネットワーク (DQN) エージェント
- Train Reinforcement Learning Agents