このページは機械翻訳を使用して翻訳されました。最新版の英語を参照するには、ここをクリックします。
デュアルサミングノードDFEのHDLを生成する
この例では、SerDes Toolbox™ のブロックを使用して、アーキテクチャ的に代表的な 100 Gb/s デュアル サミング ノード DFE PAM4 SerDes レシーバー モデル用のビット精度の決定フィードバック イコライザー (DFE) 適応エンジンを設計する方法を示します。このビット精度の DFE 適応エンジンは、ASIC または FPGA での実装に適した合成可能な RTL コードを生成します。DFE モデルの実装を代表するデータパスにより、適応エンジンは主要な設計面を反映できるようになります。PAM4 しきい値回復、DFE タップ重み調整、およびクロック位相感度。
例には次のセクションが含まれます。
適応エンジンを抽象的なシステムレベルの Simulink® モデルからビット精度の RTL 対応 Simulink モデルに進化させる手順。
ビット精度の Simulink モデルから HDL Coder™ を使用した合成可能な RTL コードへの適応エンジンの自動変換。
Verilog でシミュレートされた RTL コードと Simulink でシミュレートされたビット精度のモデル間のテスト ベクトルを比較することによる適応エンジン設計の検証。
例の概要
歴史的に、SerDes 設計では単一加算ノード DFE トポロジが使用されていました。SerDes データ レートの増加により、DFE のタイミング制約が厳しくなり、設計マージンが縮小し、代替の DFE トポロジが必要になります。そのようなトポロジの 1 つが、デュアル サミング ノード DFE です。このDFEは1つではなく2つの加算ノードを使用します。各加算ノードは、入力シンボルを半分の速度で均等化することでタイミング制約を緩和し、回路の複雑さと面積の増加を犠牲にしてクロックレートを低減します[1]。この例では、アーキテクチャ的に代表的なデュアル サミング ノード DFE PAM4 受信機モデルを使用して、ハードウェア実装に対応した現実的な適応エンジンを設計する方法を示します。同時に、このモデルは IBIS-AMI モデルの表現を改良します。
モデルの概要
デュアル サミング ノード DFE Simulink モデル、DualSummingNodeSerdes.slx にアクセスするには、この例に付属するプロジェクトを開きます。この SerDes モデルはこの例の開始点であり、Architectural 100G Dual-Summing-Node-DFE PAM4 SerDes Receiver Model (SerDes Toolbox) にあるモデルと一致します。
openProject('dual_summing_node_hdl_proj'); 
以下に示す抽象的なシステム レベルの適応エンジン モデルは、Rx/DualSummingNodeDFECDR にあります。DFECDR サブシステムは次のブロックで構成されています。
DFE_analog– デュアルサミングノードDFEPD_analog– 位相検出器LF1– ループフィルターVCO1– 電圧制御発振器 (VCO)ADAPT– DFE適応エンジン

デュアル サミング ノード DFE モデルの適応エンジンは、信号レベルを回復し、サンプラーしきい値を設定し、DFE のタップ重みを適応させます。
HDLコード生成のための適応エンジンの更新
自動 RTL コード生成を有効にするには、実装固有の詳細を使用して抽象システム レベル適応エンジン モデル (ADAPT) を更新します。RTL に適さない浮動小数点演算を同等の固定小数点演算に置き換えます。これらの手順により、抽象適応エンジン モデルが HDL Coder に適したビット精度の形式に改良されます。
ウィンドウ処理を使用してサンプル レートを下げる – 適応エンジンの処理速度を 50 Gbaud/s のボー レートから HDL 実装のより低いクロック レートに変更します。
出力制御の形式を浮動小数点から整数に変更する – 適応エンジン出力、DFE タップ重み、およびサンプラーしきい値の形式を浮動小数点から整数に変更します。簡略化されたデジタル-アナログ コンバーター (DAC) を使用して、これらの整数出力を DFE 内で必要な信号レベルに変換します。
入力シンボル アルファベットを浮動小数点から整数に変更します – 整数ベースの適応処理を有効にするには、DFE とデシリアライザーのシンボル アルファベット エンコーディングを更新します。
適応アルゴリズムを更新して整数処理を使用する – 適応アルゴリズムを変更して、ビットベクトルを入力と整数出力として活用し、固定小数点 (整数) 演算とビット単位の演算を使用して処理を実行します。
次のセクションでは、これらの変更について詳しく説明します。これらの変更の結果は、プロジェクト モデル DualSummingNodeSerdes_bitAccurate.slx に保存されます。
open_system('DualSummingNodeSerdes_bitAccurate');ウィンドウを使用してサンプルレートを下げる
システムのボーレートは、このハーフレート システムでは約 50 Gbaud/s または 25 GHz であり、適応エンジンの実速度実装には高すぎます。適応ロジックの速度を下げるために、適応エンジンは、各クロック サイクルで 1 つのサンプルを処理するのではなく、クロック サイクルごとにサンプルのウィンドウ (グループ) を並列に処理します。DFE 出力でのデータのデシリアライズにより、適応エンジンの動作速度が低下します。
まず、以下に示すように、適応ループをサンプルごとの処理からサンプルのグループ処理に変更します。DFE 出力と DFE 適応入力間のフィードバック パスに、ウィンドウ ベースの適応システム (ADAPT) とデシリアライザー (DES) の 2 つのブロックが追加されました。

デシリアライザーは通常、カスタムのアナログ/デジタル混合信号設計を使用して実装されるため、システムのボーレートで実行できます。デジタル適応エンジンをトリガーするには、分周されたクロックがデジタル適応ブロックを駆動します。以下に示す DES Simulink ブロックは、データのデシリアライズとクロック分割の両方の機能を実行します。入力およびトリガー ロジックは、サンプルごとの適応エンジンの場合と同じです。ただし、サンプルは処理されるのではなく、循環バッファにシフトされます。DEMUX MATLAB® 関数ブロックはこの循環バッファを実装します。まずバッファにサンプルを保存し、次に分割された (低減された) クロック レートでサンプルのウィンドウを適応エンジンに送ります。

デシリアライゼーション係数は、デシリアライザと適応ブロックの両方のパラメータであり、現在は 32:1 のデシリアライゼーションとクロック分割比を実現するために 32 に設定されています。トランシーバーのボーレートは 53.125 Gbaud/s なので、DFE は 53.125 GS/s のレートで決定を生成します。分割比が 32:1 の場合、適応アルゴリズムを実装するデジタル ロジックは 53.125 GHz/32 = 1.66 GHz で動作する必要があります。デシリアライゼーション率を高めることができます。デシリアライゼーション比率が 64:1 の場合、適応システムのレイテンシが増加するという代償を払って、830 MHz のデジタル ロジック速度が得られます。

この例で使用されている収束時間定数 (mu パラメータ) では、32:1 または 64:1 デシリアライザ設定の収束トレース間に顕著な違いはありません。
DFE制御形式を浮動小数点から整数に変更する
現在、適応エンジンからの出力は、DFE タップ重みとサンプラーしきい値を直接駆動する浮動小数点値です。ただし、実際のシステムでは、浮動小数点値で DFE を駆動するのではなく、DAC を使用してバイナリ コードワード (整数値) からアナログ電圧を生成します。次に、適応エンジンの出力タイプを浮動小数点から整数に変更し、DAC モデルを制御パスに挿入します。簡単にするために、タップ重みとしきい値電圧制御の両方に 8b の 2 の補数コードワードを使用します。これは、より高い解像度またはより低い解像度に対応するために変更できます。


Simulink 乗算器ブロックは DAC をモデル化します。乗算器は 8b 2 の補数コードワードを適切にスケーリングされた電圧 (浮動小数点制御) に変換します。タップ重みゲインは 0.025/128、しきい値電圧制御ゲインは 0.25/128 です。同じ適応収束時間を維持するには、MATLAB ワークスペースで定義されている適応収束設定を調整します。
muTaps = muTaps * (256 * 16); muThresholds = muThresholds * 256;
muTaps および muThreshold パラメータに変更を加えた結果、適応ブロック (ADAPT) からの出力は整数スケール [-128, 127] になりましたが、整数型ではありません。MATLAB 関数の出力タイプを修正するには:
1. vth_data しきい値の計算を MATLAB 関数に移動します。


2. プロパティ インスペクター ダイアログ ボックスを使用して、関数の出力が int8 データ型を使用するように設定します。

3. vlev および taps の割り当てを int8 にキャストします。これらの変数は、ADAPT 関数の下部にあります。
% Data buffer
vlev = int8(vstate(1 : 4));
vdat = int8(mean([vstate(1:3), vstate(2:4)], 2));
taps = int8(tstate(1 : 4));
4. DFE タップ値が電圧として表される IBIS-AMI エクスポート準拠を維持するには、IBIS-AMI タップ重み出力を DAC ゲインでスケーリングします。

収束を再度実行し、結果を確認します。結果は同じ曲線になりますが、タップとしきい値電圧の量子化による整数出力スケールを使用します。

入力シンボルのアルファベットを浮動小数点から整数に変更する
アルゴリズム適応関数を RTL エクスポート対応関数に変更するには、ビット精度の DFE およびデシリアライザー出力が必要です。現在、DFE 出力は、データ サンプラーの場合は 4 状態浮動小数点値、補助サンプラーの場合は 2 状態浮動小数点 4 エントリ ベクトルです。4 状態のシンボル アルファベットは [-1,-1/3,+1/3,+1] セットからのものであり、アルゴリズム適応機能には適していますが、ビット精度のデジタル機能には適していません。同様に、2 状態のシンボル アルファベットは [-1,+1] のセットからのものですが、これも必要なブール値でも整数値でもありません。
データサンプラーの出力値を変更する
データ サンプラー サブシステム DFE_analog/delay 8 と DFE_analog/delay 4 を変更します。以下の 2 つの図に示すように、再マッピング関数をコメント スルーして、データ スライサーの 4 状態シンボル アルファベットの出力を [-1,-1/3,+1/3,+1] から [0,1,2,3] に変更します。次に、3 入力合計の出力タイプを double 出力データ型から 2b 符号なし整数値である fixdt(0,2,0) に変更します。データ サンプラーはトリガー システムなので、decision ブロック ダイアログ ボックスを使用して、出力の初期値を [-1,-1/3,+1/3,+1] アルファベットの有効な値である -1 から、更新された出力アルファベットの有効な値である 0 に更新します。


補助サンプラーの出力値を変更する
補助サンプラーサブシステム DFE_analog/delay 3 と DFE_analog/delay 5 を変更して、[-1,1] ではなく [0,1] (ブール) の決定を出力するようにします。
cast to doubleブロックとpolynomial functionブロックを削除します。4 入力ビット連結ブロックを使用して、4 つの個別のコンパレータからのブール出力を 4b ベクトルに結合します。
vth入力ベクトルの順序を反転して、連結順序と一致するようにします。初期決定出力値を
-1から0に変更します。


Verilog モジュールの入力ポートはビット ベクターとして表現する必要があるため、ベクトル化ではなくビット連結が使用されます。ビット連結ではマルチビット RTL ポートが生成されますが、Simulink ベクトル化では複数の RTL ポートが生成されます。注意: MATLAB は Verilog ビット ベクトルを固定小数点表現と同等とみなします。4b ベクトルは fixdt(0,4,0) 値にマップされます。4b 幅の固定小数点値であれば何でも十分です。符号なしである必要はなく、小数ビットがゼロである必要もありません。
DFEタップステアリングブロックの変更
DFE は、元のシンボル アルファベット [-1,-1/3,+1/3,+1] のゼロ対称性を活用します。DFE では、サンプラーの決定が DFE タップの重みとともにフィードバックに使用され、DFE の寄与が制御されます。ただし、RTL に適した新しい決定アルファベット [0,1,2,3] はゼロ対称ではなくなりました。下の図で強調表示されている DFE タップ ステアリング ブロックを、新しい決定アルファベットと互換性があるように変更します。

正しい DFE タップ重みコンポーネントである Bit-Accurate Tap DAC は、以下に示す DFE_parts.slx ライブラリにあります。

位相検出器のデータマッピングの変更
位相検出器は、データ決定を利用してバンバン位相検出器を駆動します。位相検出器は [-1,-1/3,+1/3,+1] アルファベットを使用します。オリジナルの位相検出器の写真を以下に示します。

以下に示すように、DFE_parts.slx ライブラリの ufix2 -> dbl コンポーネントを使用して位相検出器を更新します。

デシリアライザーをベクトル化からビット連結に変更する
アルゴリズム デシリアライザーは次の処理を実行します。
4 状態のデータ サンプラー出力を 32 エントリ ベクトルにパックします。
4 エントリの 2 ステート データ サンプラー出力を 32 x 4 マトリックスにパックします。
この配置は、MATLAB ベクトル インデックスを使用して for ループで 32 個のサンプルを処理できるため、アルゴリズム モデルに適しています。ただし、32 エントリ ベクターは RTL モジュール内の個別の入力ピンにマップされます。RTL 信号はマルチビット バスにグループ化されるため、個別の入力ピンは適していません。
生成された Verilog モジュールのバス信号インターフェイスを実現するには、デシリアライザーを次のように変更します。
2bデータサンプラー出力を
fixdt(0,2,0)表現を使用して32 x 2b = 64b出力fixdt(0,64,0).にパックします。fixdt(0,4,0)表現を使用して、4bの補助出力を32 x 4bの出力fixdt(0,128,0).にパックします。
オリジナルのデシリアライザー MATLAB 関数を以下に示します。
function [dsmpls, asmpls] = buffer(dsmpl, asmpl, dr) persistent data aux count dsmpls_out asmpls_out if isempty(data) data = zeros(dr, 1); dsmpls_out = zeros(dr, 1); aux = zeros(dr, length(asmpl)); asmpls_out = zeros(dr, length(asmpl)); count = uint8(0); end if (count == 0) dsmpls_out = data; asmpls_out = aux; end count = mod(count + 1, dr); data = circshift(data, 1); data(1) = dsmpl; aux = circshift(aux, 1); aux(1, 1 : length(asmpl)) = asmpl; dsmpls = dsmpls_out(1 : dr); asmpls = asmpls_out(1 : dr, 1 : length(asmpl));
以下の関数コードと一致するように関数を変更します。
function [dsmpls, asmpls] = buffer(dsmpl, asmpl, dr) persistent data aux count dsmpls_out asmpls_out if isempty(data) aux = fi(0, 0, dr * asmpl.WordLength, 0); asmpls_out = fi(0, 0, dr * asmpl.WordLength, 0); data = fi(0, 0, dr * dsmpl.WordLength, 0); dsmpls_out = fi(0, 0, dr * dsmpl.WordLength, 0); count = uint8(0); end if (count == 0) dsmpls_out = data; asmpls_out = aux; end count = mod(count + 1, dr); if (dr == 1) data = dsmpl; aux = asmpl; else data = bitconcat(bitsliceget(data, (dr - 1) * dsmpl.WordLength), dsmpl); aux = bitconcat(bitsliceget(aux, (dr - 1) * asmpl.WordLength), asmpl); end dsmpls = dsmpls_out; asmpls = asmpls_out;
関数の入力パラメータと出力パラメータを変更します。
dsampleを変更してfixdt(0,4,0)タイプを使用します。fixdt(0,2*dr,0)タイプを使用して、dsamplesをdrのサイズから1のサイズに変更します。fixdt(0,4,0)タイプを使用して、asampleを4のサイズから1のサイズに変更します。fixdt(0,4*dr,0)タイプを使用して、asamplesを[dr,4]のサイズから1のサイズに変更します。
整数処理を使用するための適応アルゴリズムの更新
適応エンジンからの入力と出力が設定されたので、次はその内部機能に焦点を当てます。ビット精度の機能は以下に示します。
function [vlev, dlev, taps] = fcn(data, aux, int_fw, dr) persistent vstate tstate dstate if isempty(vstate) fxpt = numerictype(1, 8+int_fw, int_fw); vstate = fi(zeros(4, 1), fxpt, hdlfimath); tstate = fi(zeros(4, 1), fxpt, hdlfimath); dstate = fi(0, 0, 4, 0); end for idx = dr - 1 : -1 : 0 d = bitsliceget(bitsrl(data, 2 * idx), 2); a = bitsrl(aux, 4 * idx); % Level restore if xor(bitget(a, uint8(d) + 1), bitget(d, 2)) vstate(1 + bitxorreduce(d)) = vstate(1 + bitxorreduce(d)) + fi(fxpt.eps, fxpt, hdlfimath); else vstate(1 + bitxorreduce(d)) = vstate(1 + bitxorreduce(d)) - fi(fxpt.eps, fxpt, hdlfimath); end % Taps for tapidx = 1 : 4 if xor(bitget(dstate, tapidx), bitget(a, uint8(d) + 1)) tstate(tapidx) = tstate(tapidx) - fi(fxpt.eps, fxpt, hdlfimath); else tstate(tapidx) = tstate(tapidx) + fi(fxpt.eps, fxpt, hdlfimath); end end % Data buffer dstate = bitconcat(bitsliceget(dstate, 3), bitget(d, 2)); %% MSB end vlev = int8([vstate(1 : 2); -vstate(2 : -1 : 1)]); dlev = int8(zeros(3,1)); dlev(1) = int8(bitsra(vlev(1) + vlev(2), 1)); dlev(3) = int8(bitsra(vlev(3) + vlev(4), 1)); taps = int8(tstate(1 : 4));
vth_aux、vth_data、taps 出力ポートをダブルクリックして、トリガーされたブロック出力の初期状態を変更します。次に、下の表に示すように、初期出力の値を変更します。
端子 | 初期出力 |
vth_aux |
|
vth_データ |
|
タップ |
|
HDLアルゴリズムを生成する
適応アルゴリズムをビット精度バージョンに変換したので、RTL エクスポートの候補になります。HDL Coder は関数のエクスポートを容易にします。
次のセクションでは、ADAPT サブシステムをターゲットにするプロセスについて説明します。その成果はプロジェクト モデル DualSummingNodeSerdes_bitAccurate_for_export.slx に保存されています。
open_system('DualSummingNodeSerdes_bitAccurate_for_export');完全なモデルアップデート
HDL 生成の互換性のために次の更新を行います。
HDL Coder では、トリガーされたブロックがサブシステム内にある必要があります。ADAPT ブロックを選択し、右クリックして サブシステムとモデル参照/選択項目からサブシステムを作成 を選択してラップします。新しいサブシステムの名前をadaptに変更します。

固定小数点処理の数値を変更します。MATLAB 関数、adapt/ADAPT/MATLAB 関数をダブルクリックし、ツールストリップの [シミュレーション] タブから プロパティ インスペクター を選択します。整数オーバーフローで飽和ボックスをオフにし、固定小数点プロパティをMATLABと同じからその他を指定に変更して、テキスト フィールドに「
fimath(hdlfimath)」と入力します。

ツールストリップを開いてモデル設定を構成する
APPS メニューから HDL Coder アプリを開き、次の手順に従います。


コード生成に関心のあるサブシステムをロックするには、キャンバス上の
adaptサブシステムDualSummingNodeDFECDR/adaptを選択し、コード対象 ボックスにピン留めします。RTL コードを生成する前に、HDL コード アドバイザーを実行します。ハイパーリンクをクリックして、提案された修正を承認します。
設定 をクリックして、次の変更を行います。
HDL コード生成/ターゲット/ターゲット周波数 を 1660 に変更します。
HDL コード生成/グローバル設定/追加設定/モデル生成/生成されたモデルの選択を解除します。
コード生成/ビルド プロセス/ツールチェーンを
IBIS-AMI GNU gcc/g++に設定して、IBIS-AMI ツールチェーンを再度有効にします。シミュレーション ターゲット/詳細パラメータ/MATLAB 関数の動的メモリ割り当て を有効にして、動的メモリ割り当てのサポートを再度有効にします。
適応ブロック HDL を生成する
これで適応モデルをエクスポートする準備が整いました。モデルを RTL にエクスポートするには、HDL ツールバーから [HDL コードの生成] (上記の番号 4) をクリックします。
あるいは、コマンドラインで makehdl を呼び出すこともできます。
makehdl('DualSummingNodeSerdes_bitAccurate_for_export/Rx/DualSummingNodeDFECDR/adapt');### Begin compilation of the model 'DualSummingNodeSerdes_bitAccurate_for_export'... ### Working on the model DualSummingNodeSerdes_bitAccurate_for_export ### Generating HDL for DualSummingNodeSerdes_bitAccurate_for_export/Rx/DualSummingNodeDFECDR/adapt ### Using the config set for model DualSummingNodeSerdes_bitAccurate_for_export for HDL code generation parameters. ### Running HDL checks on the model 'DualSummingNodeSerdes_bitAccurate_for_export'. ### Working on the model 'DualSummingNodeSerdes_bitAccurate_for_export'... ### Begin Verilog Code Generation for 'DualSummingNodeSerdes_bitAccurate_for_export'. ### Working on DualSummingNodeSerdes_bitAccurate_for_export/Rx/DualSummingNodeDFECDR/adapt/ADAPT as hdl_prj/hdlsrc/DualSummingNodeSerdes_bitAccurate_for_export/ADAPT_block.v. ### Working on DualSummingNodeSerdes_bitAccurate_for_export/Rx/DualSummingNodeDFECDR/adapt as hdl_prj/hdlsrc/DualSummingNodeSerdes_bitAccurate_for_export/adapt.v. ### Code Generation for 'DualSummingNodeSerdes_bitAccurate_for_export' completed. ### Generating HTML files for code generation report at DualSummingNodeSerdes_bitAccurate_for_export_codegen_rpt.html ### Creating HDL Code Generation Check Report adapt_report.html ### HDL check for 'DualSummingNodeSerdes_bitAccurate_for_export' complete with 0 errors, 1 warnings, and 0 messages. ### HDL code generation complete.
プロセスが完了したら、生成されたトップレベル デザイン RTL を開きます。
open hdl_prj/hdlsrc/DualSummingNodeSerdes_bitAccurate_for_export/adapt.v次の点に注意してください。
1. RTL インターフェースは、最小限のインターフェース ポート セットで構成されます。
module adapt
(reset,
div_clk,
data,
aux,
vth_aux_0,
vth_aux_1,
vth_aux_2,
vth_aux_3,
vth_data_0,
vth_data_1,
vth_data_2,
taps_0,
taps_1,
taps_2,
taps_3);
2. DFE からの決定である data と aux は、ビット ベクトルとして提供されます。
input [63:0] data; // ufix64 input [127:0] aux; // ufix128
生成されたHDLアルゴリズムを検証する
この例には、Verilog モデルをシミュレートするためのテストベンチが含まれています。
HDLシミュレータを選択
HDL Coder を使用して、適応エンジンの RTL を生成します。次に、適応エンジンの Simulink 実行から保存された入力を使用して、選択した HDL シミュレーターを使用して適応エンジン HDL を実行します。
% This is a MathWorks-specific setup. You must assign PATH and % other settings specific to your environment for your chosen simulator. setup_questa(); % Uncomment one of the following supported HDL simulator choices: current_hdl_simulator = 'Questa'; % Windows or Linux % current_hdl_simulator = 'Xcelium'; % Linux only % current_hdl_simulator = 'VCS'; % Linux only % current_hdl_simulator = 'Vivado'; % Linux only
Simulink と Verilog を実行して結果を比較する
Simulink と Verilog の比較スクリプトを実行します。このスクリプトは、次のアクションを実行します。
Simulink シミュレーションを実行し、適応ブロックの入力と出力をキャプチャします。
Verilog シミュレーションで使用するために、適応ブロック入力をバイナリ ファイルに書き込みます。
生成された RTL コードと Simulink によって保存された刺激を使用して、Verilog シミュレーションを実行します。
Verilog 出力を読み込みます。
Simulink と Verilog 適応出力をプロットします。
compare_simulation
Reading pref.tcl # 2023.2 # do scripts/tb_tran_questa.do # QuestaSim-64 vlog 2023.2 Compiler 2023.04 Apr 11 2023 # Start time: 18:42:11 on Jan 13,2024 # vlog -sv hdl_prj/hdlsrc/DualSummingNodeSerdes_bitAccurate_for_export/adapt.v # -- Compiling module adapt # # Top level modules: # adapt # End time: 18:42:11 on Jan 13,2024, Elapsed time: 0:00:00 # Errors: 0, Warnings: 0 # QuestaSim-64 vlog 2023.2 Compiler 2023.04 Apr 11 2023 # Start time: 18:42:11 on Jan 13,2024 # vlog -sv hdl_prj/hdlsrc/DualSummingNodeSerdes_bitAccurate_for_export/ADAPT_block.v # -- Compiling module ADAPT_block # # Top level modules: # ADAPT_block # End time: 18:42:11 on Jan 13,2024, Elapsed time: 0:00:00 # Errors: 0, Warnings: 0 # QuestaSim-64 vlog 2023.2 Compiler 2023.04 Apr 11 2023 # Start time: 18:42:12 on Jan 13,2024 # vlog -sv hdl_tb/adapt_tb.v # -- Compiling module adapt_tb # # Top level modules: # adapt_tb # End time: 18:42:12 on Jan 13,2024, Elapsed time: 0:00:00 # Errors: 0, Warnings: 0 # vsim -c work.adapt_tb # Start time: 18:42:12 on Jan 13,2024 # ** Note: (vsim-3812) Design is being optimized... # // Questa Sim-64 # // Version 2023.2 linux_x86_64 Apr 11 2023 # // # // Copyright 1991-2023 Mentor Graphics Corporation # // All Rights Reserved. # // # // QuestaSim and its associated documentation contain trade # // secrets and commercial or financial information that are the property of # // Mentor Graphics Corporation and are privileged, confidential, # // and exempt from disclosure under the Freedom of Information Act, # // 5 U.S.C. Section 552. Furthermore, this information # // is prohibited from disclosure under the Trade Secrets Act, # // 18 U.S.C. Section 1905. # // # Loading sv_std.std # Loading work.adapt_tb(fast) # ** Note: $finish : hdl_tb/adapt_tb.v(55) # Time: 2051 ns Iteration: 1 Instance: /adapt_tb # End time: 18:42:13 on Jan 13,2024, Elapsed time: 0:00:01 # Errors: 0, Warnings: 0


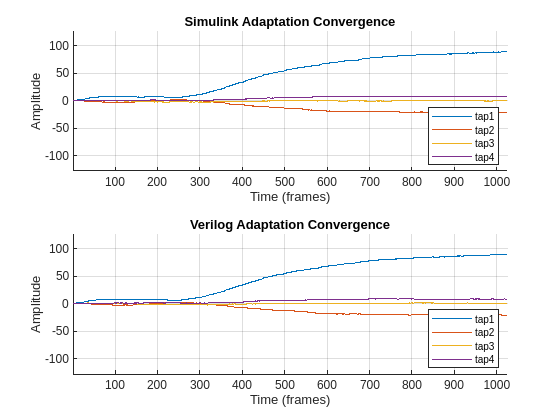
プロットは、Simulink ベースの適応とその RTL コードが 2 つの環境間で同じように動作することを示しています。
まとめ
生成された RTL は、Verilog シミュレーションで直接使用して、より大規模なシステムを構築または検証できます。生成されたコードは、合成エンジンへの入力としても使用できます。さらに、MATLAB または Simulink でエクスポートされたコードを改良して、リソースの使用率と操作の並列化を改善できます。この例では、SerDes Toolbox モデルから直接合成可能なコードを生成するためのパスを強調しています。この例では、IBIS-AMI エクスポート機能を維持しながら、抽象的なシステム レベル モデルを適応エンジンのビット精度の表現に改良します。
リファレンス
[1] S. Ibrahim および B. Razavi、「20 Gb/s システム向け低電力 CMOS イコライザー設計」、IEEE Journal of Solid-State Circuits、vol. 46、no. 6、pp. 1321-1336、2011 年 6 月、doi:10.1109/JSSC.2011.2134450.
参考
DFECDR (SerDes Toolbox)