代理分岐
ある観測値について最適な分割予測子の値が欠落している場合、代理分岐を使用するよう指定すると、最適な代理予測子を使用して左または右の子ノードに観測値が送られます。欠損データがある場合、木および木のアンサンブルに代理分岐が含まれていると、予測性能が向上します。この例では、代理分岐がある決定木を使用して、欠損値が含まれているデータの予測精度を向上させる方法を示します。
標本データの読み込み
ionosphere データ セットを読み込みます。
load ionosphereデータ セットを学習セットとテスト セットに分割します。データの 30% をテスト用にホールドアウトします。
rng('default') % For reproducibility cv = cvpartition(Y,'Holdout',0.3);
学習データとテスト データを指定します。
Xtrain = X(training(cv),:); Ytrain = Y(training(cv)); Xtest = X(test(cv),:); Ytest = Y(test(cv));
テスト セットの値の半分が欠損しているものとします。テスト セットの値の半分を NaN に設定します。
Xtest(rand(size(Xtest))>0.5) = NaN;
ランダム フォレストの学習
代理分岐を使用せずに、150 本の分類木のランダム フォレストに学習をさせます。
templ = templateTree('Reproducible',true); % For reproducibility of random predictor selections Mdl = fitcensemble(Xtrain,Ytrain,'Method','Bag','NumLearningCycles',150,'Learners',templ);
代理分岐を使用する決定木テンプレートを作成します。代理分岐を使用する木では、欠損データが含まれている予測子がある場合でも、観測値全体が破棄されることはありません。
templS = templateTree('Surrogate','On','Reproducible',true);
テンプレート templS を使用してランダム フォレストに学習をさせます。
Mdls = fitcensemble(Xtrain,Ytrain,'Method','Bag','NumLearningCycles',150,'Learners',templS);
精度の検証
代理分岐を使用した予測と代理分岐を使用しない予測の精度を検証します。
両方のアプローチを使用して、応答を予測し混同行列チャートを作成します。
Ytest_pred = predict(Mdl,Xtest);
figure
cm = confusionchart(Ytest,Ytest_pred);
cm.Title = 'Model Without Surrogates';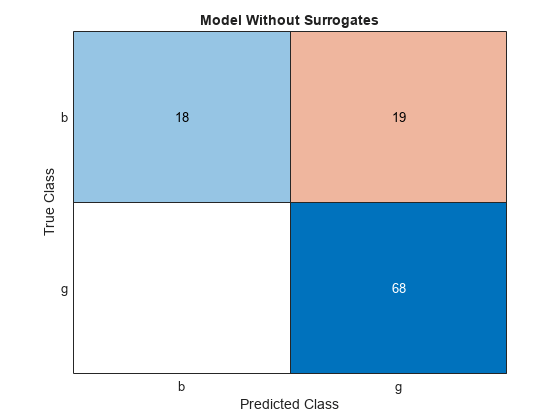
Ytest_preds = predict(Mdls,Xtest);
figure
cms = confusionchart(Ytest,Ytest_preds);
cms.Title = 'Model with Surrogates';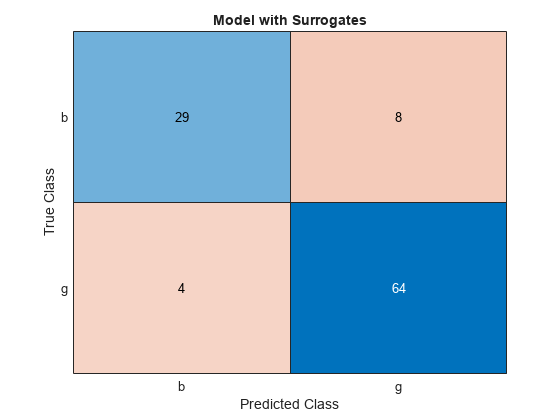
混同行列の非対角要素は、誤分類されたデータを表します。適切な分類器では、ほとんど対角行列のように見える混同行列が生成されます。このケースでは、代理分岐を使用して学習をさせたモデルの方が、分類誤差が小さくなっています。
累積分類誤差を推定します。関数 loss を使用して分類誤差を推定するときに 'Mode','Cumulative' を指定します。関数 loss は、最初の J 個の学習器を使用した場合の誤差を要素 J が示すベクトルを返します。
figure plot(loss(Mdl,Xtest,Ytest,'Mode','Cumulative')) hold on plot(loss(Mdls,Xtest,Ytest,'Mode','Cumulative'),'r--') legend('Trees without surrogate splits','Trees with surrogate splits') xlabel('Number of trees') ylabel('Test classification error')
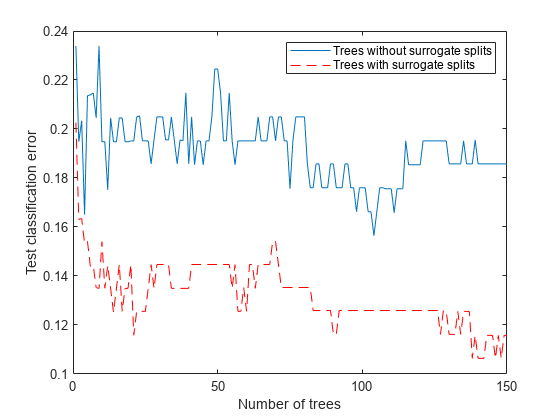
木の本数が増えると誤差の値が小さくなります。これは、優れた性能を示します。代理分岐を使用して学習をさせたモデルの方が、分類誤差が小さくなっています。
compareHoldout を使用して、結果の違いの統計的有意性をチェックします。この関数はマクネマー検定を使用します。
[~,p] = compareHoldout(Mdls,Mdl,Xtest,Xtest,Ytest,'Alternative','greater')
p = 0.0384
p 値が小さいので、代理分岐を使用したアンサンブルの方が統計的有意性という点で優れていることがわかります。
予測子の重要度の推定
予測子の重要度の推定は、木で代理分岐を使用するかどうかによって変化する可能性があります。out-of-bag 観測値を並べ替えることにより、予測子の重要度の尺度を推定します。次に、上位 5 つの重要な予測子を求めます。
imp = oobPermutedPredictorImportance(Mdl); [~,ind] = maxk(imp,5)
ind = 1×5
5 3 27 8 14
imps = oobPermutedPredictorImportance(Mdls); [~,inds] = maxk(imps,5)
inds = 1×5
3 5 8 27 7
予測子の重要度を推定した後で、重要ではない予測子を除外して、モデルに再学習をさせることができます。重要でない予測子を除外すると、予測のための時間とメモリが節約され、予測の理解が容易になります。
多数の予測子が学習データに含まれている場合に予測子の重要度を分析するには、アンサンブルの木学習器について関数 templateTree の 'NumVariablesToSample' として 'all' を指定します。このようにしないと、重要度が過小評価されて一部の予測子が選択されない可能性があります。たとえば、ランダム フォレストの予測子の選択を参照してください。
参考
compareHoldout | fitcensemble | fitrensemble