oobPermutedPredictorImportance
回帰木のランダム フォレストについての並べ替えによる out-of-bag 予測子の重要度の推定
説明
Imp = oobPermutedPredictorImportance(Mdl)Mdl を使用して、並べ替えによる out-of-bag 予測子の重要度の推定を返します。Mdl は RegressionBaggedEnsemble モデル オブジェクトでなければなりません。Imp は 1 行 p 列の数値ベクトルで、p は学習データ内の予測子変数の個数 (size(Mdl.X,2)) です。Imp( は予測子 j)Mdl.PredictorNames( の重要度です。j)
Imp = oobPermutedPredictorImportance(Mdl,Name=Value)
例
予測子の重要度の推定
carsmall データ セットを読み込みます。与えられた加速、気筒数、エンジン排気量、馬力、製造業者、モデル年および重量に対して自動車の燃費の平均を予測するモデルを考えます。Cylinders、Mfg および Model_Year はカテゴリカル変数であるとします。
load carsmall Cylinders = categorical(Cylinders); Mfg = categorical(cellstr(Mfg)); Model_Year = categorical(Model_Year); X = table(Acceleration,Cylinders,Displacement,Horsepower,Mfg,... Model_Year,Weight,MPG);
データ セット全体を使用して、50 本の回帰木のランダム フォレストに学習をさせることができます。
Mdl = fitrensemble(X,'MPG','Method','Bag','NumLearningCycles',500);
'Method' が 'Bag' である場合、fitrensemble は既定の木テンプレート オブジェクト templateTree() を弱学習器として使用します。この例では、再現性を得るため、木テンプレート オブジェクトを作成するときに 'Reproducible',true を指定し、このオブジェクトを弱学習器として使用します。
rng('default') % For reproducibility t = templateTree('Reproducible',true); % For reproducibiliy of random predictor selections Mdl = fitrensemble(X,'MPG','Method','Bag','NumLearningCycles',500,'Learners',t);
Mdl は RegressionBaggedEnsemble モデルです。
out-of-bag 観測値を並べ替えることにより、予測子の重要度の尺度を推定します。棒グラフを使用して推定を比較します。
imp = oobPermutedPredictorImportance(Mdl); figure; bar(imp); title('Out-of-Bag Permuted Predictor Importance Estimates'); ylabel('Estimates'); xlabel('Predictors'); h = gca; h.XTickLabel = Mdl.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter = 'none';
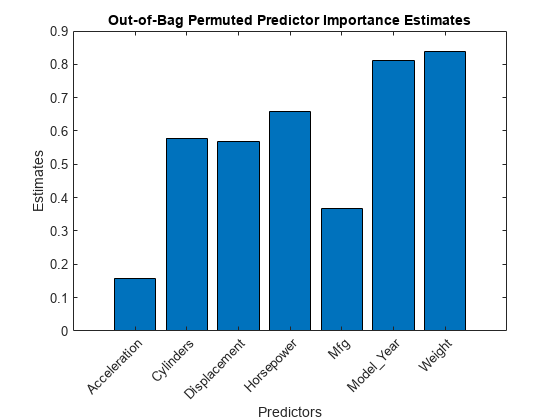
imp は、予測子の重要度の推定が含まれている 1 行 7 列のベクトルです。大きい値は、予測子が予測に与える影響が大きいことを示します。このケースでは、最も重要な予測子は Weight であり、次に重要なのは Model_Year です。
並列計算の使用による予測子の重要度の不偏推定
carsmall データ セットを読み込みます。与えられた加速、気筒数、エンジン排気量、馬力、製造業者、モデル年および重量に対して自動車の燃費の平均を予測するモデルを考えます。Cylinders、Mfg および Model_Year はカテゴリカル変数であるとします。
load carsmall Cylinders = categorical(Cylinders); Mfg = categorical(cellstr(Mfg)); Model_Year = categorical(Model_Year); X = table(Acceleration,Cylinders,Displacement,Horsepower,Mfg,... Model_Year,Weight,MPG);
カテゴリカル変数で表現されるカテゴリの個数を表示します。
numCylinders = numel(categories(Cylinders))
numCylinders = 3
numMfg = numel(categories(Mfg))
numMfg = 28
numModelYear = numel(categories(Model_Year))
numModelYear = 3
Cylinders と Model_Year には 3 つしかカテゴリがないので、予測子分割アルゴリズムの標準 CART ではこの 2 つの変数よりも連続予測子が分割されます。
データ セット全体を使用して、500 本の回帰木のランダム フォレストに学習をさせます。偏りの無い木を成長させるため、予測子の分割に曲率検定を使用するよう指定します。データには欠損値が含まれているので、代理分岐を使用するよう指定します。無作為な予測子の選択を再現するため、rng を使用して乱数発生器のシードを設定し、'Reproducible',true を指定します。
rng('default'); % For reproducibility t = templateTree('PredictorSelection','curvature','Surrogate','on', ... 'Reproducible',true); % For reproducibility of random predictor selections Mdl = fitrensemble(X,'MPG','Method','bag','NumLearningCycles',500, ... 'Learners',t);
out-of-bag 観測値を並べ替えることにより、予測子の重要度の尺度を推定します。並列計算を実行します。
options = statset('UseParallel',true); imp = oobPermutedPredictorImportance(Mdl,'Options',options);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
棒グラフを使用して推定を比較します。
figure; bar(imp); title('Out-of-Bag Permuted Predictor Importance Estimates'); ylabel('Estimates'); xlabel('Predictors'); h = gca; h.XTickLabel = Mdl.PredictorNames; h.XTickLabelRotation = 45; h.TickLabelInterpreter = 'none';

このケースでは、最も重要な予測子は Model_Year であり、次に重要なのは Cylinders です。これらの結果を予測子の重要度の推定の結果と比較します。
入力引数
詳細
ヒント
fitrensemble の使用によりランダム フォレストを成長させる場合、
標準 CART アルゴリズムには、相違する値が少ない分割予測子 (カテゴリカル変数など) よりも、相違する値が多い分割予測子 (連続変数など) を選択する傾向があります[3]。予測子データ セットが異種混合である場合や、一部の予測子が相違する値を他の変数よりも相対的に少なく含んでいる場合は、曲率検定または交互作用検定の指定を検討してください。
標準 CART を使用して成長させた木は、予測子変数の交互作用の影響を受けません。また、多くの無関係な予測子が存在する状況では、このような木によって重要な変数が特定される可能性は、交互作用検定を適用した場合より低くなります。このため、予測子の交互作用を考慮し、重要度変数の特定を多くの無関係な変数が存在する状況で行うには、交互作用検定を指定します[2]。
多数の予測子が学習データに含まれている場合に予測子の重要度を分析するには、アンサンブルの木学習器について関数
templateTreeのNumVariablesToSampleとして"all"を指定します。このようにしないと、重要度が過小評価されて一部の予測子が選択されない可能性があります。
詳細については、templateTree および分割予測子選択手法の選択を参照してください。
参照
[1] Breiman, L., J. Friedman, R. Olshen, and C. Stone. Classification and Regression Trees. Boca Raton, FL: CRC Press, 1984.
[2] Loh, W.Y. “Regression Trees with Unbiased Variable Selection and Interaction Detection.” Statistica Sinica, Vol. 12, 2002, pp. 361–386.
[3] Loh, W.Y. and Y.S. Shih. “Split Selection Methods for Classification Trees.” Statistica Sinica, Vol. 7, 1997, pp. 815–840.
拡張機能
バージョン履歴
R2016b で導入
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)