ClassificationNaiveBayes Predict ブロックの使用によるクラス ラベルの予測
この例では、ClassificationNaiveBayes Predictブロックを Simulink® のラベル予測に使用する方法を示します。このブロックは、観測値 (予測子データ) を受け入れて、学習済みの単純ベイズ分類モデルを使用することにより、その観測値の予測されたクラス ラベル、クラス スコア、および予測分類コストを返します。この例を完了するには、用意されている Simulink モデルを使用することも、新しいモデルを作成することもできます。
単純ベイズ分類器の学習
単純ベイズ分類器に学習させ、テスト セットで分類器の性能を評価します。
フィッシャーのアヤメのデータ セットを読み込みます。150 本のアヤメについて 4 つの測定値が含まれる数値行列 X を作成します。対応するアヤメの種類が含まれる文字ベクトルの cell 配列 Y を作成します。
load fisheriris
X = meas;
Y = species;分割の再現性を得るため、乱数発生器のシードを設定します。Y のクラス情報を使用して、観測値を階層的に学習セットとテスト セットに無作為に分割します。観測値の約 80% を単純ベイズ モデルの学習に使用し、観測値の約 20% を学習済みモデルの新しいデータでの性能のテストに使用します。
rng(0,"twister") cv = cvpartition(Y,"HoldOut",0.2);
学習インデックスとテスト インデックスを抽出します。
trainingInds = training(cv); testInds = test(cv);
学習データ セットとテスト データ セットを指定します。
Xtrain = X(trainingInds,:); Ytrain = Y(trainingInds); Xtest = X(testInds,:); Ytest = Y(testInds);
学習データ XTrain および YTrain を fitcnb 関数に渡して、単純ベイズ分類器に学習させます。カーネル分布をもつ予測子を標準化するように指定します。
nbMdl = fitcnb(Xtrain,Ytrain,Standardize=true, ... DistributionNames="kernel")
nbMdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 120
DistributionNames: {'kernel' 'kernel' 'kernel' 'kernel'}
DistributionParameters: {3×4 cell}
Kernel: {'normal' 'normal' 'normal' 'normal'}
Support: {'unbounded' 'unbounded' 'unbounded' 'unbounded'}
Width: [3×4 double]
Mu: [5.8008 3.0433 3.7283 1.1992]
Sigma: [0.8360 0.4284 1.7541 0.7684]
Properties, Methods
nbMdl は学習させたClassificationNaiveBayesモデルです。ドット表記を使用して nbMdl のプロパティにアクセスできます。たとえば、「nbMdl.ModelParameters」と入力すると、学習済みモデルのパラメーターについての詳細情報を取得できます。
テスト セットの分類精度を計算して、テスト セットで分類器の性能を評価します。
testError = loss(nbMdl,Xtest,Ytest,LossFun="classiferror");
testAccuracy = 1 - testErrortestAccuracy = 0.9333
用意されている Simulink モデルを開く
この例では、ClassificationNaiveBayes Predict ブロックを含む Simulink モデル slexClassificationNBPredictExample.slx が用意されています。この Simulink モデルを開くことも、次のセクションの説明に従って新しいモデルを作成することもできます。
Simulink モデル slexClassificationNBPredictExample.slx を開きます。
open_system("slexClassificationNBPredictExample")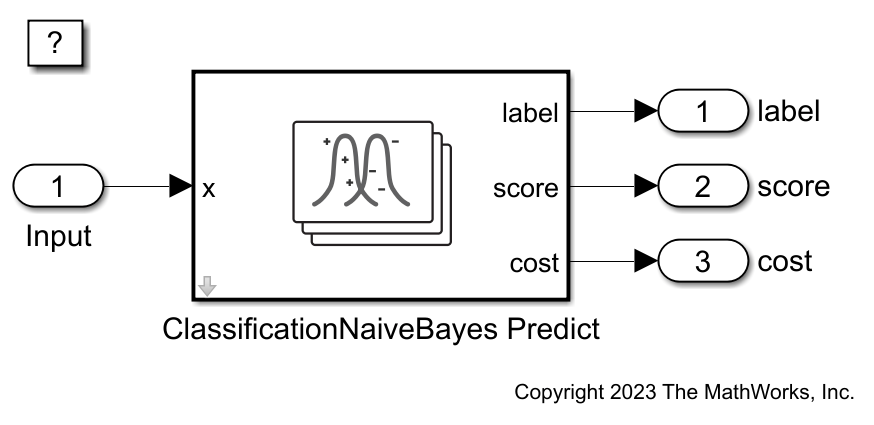
Simulink モデルを開くと、モデルを読み込む前に、ソフトウェアがコールバック関数 PreLoadFcn のコードを実行します。slexClassificationNBPredictExample の PreLoadFcn コールバック関数には、学習済みモデルの nbMdl 変数がワークスペースにあるかどうかをチェックするコードが含まれています。ワークスペースに変数がない場合、PreLoadFcn は標本データを読み込み、単純ベイズ モデルに学習させ、Simulink モデルの入力信号 (クエリ点) を作成します。コールバック関数を表示するには、[モデル化] タブの [設定] セクションで、[モデル設定] をクリックし、[モデル プロパティ] を選択します。次に、[コールバック] タブの [モデルのコールバック] ペインで PreLoadFcn コールバック関数を選択します。
Simulink モデルの作成
新しい Simulink モデルを作成するには、[空のモデル] テンプレートを開き、Statistics and Machine Learning Toolbox™ ライブラリの Classification セクションから ClassificationNaiveBayes Predict ブロックを追加します。
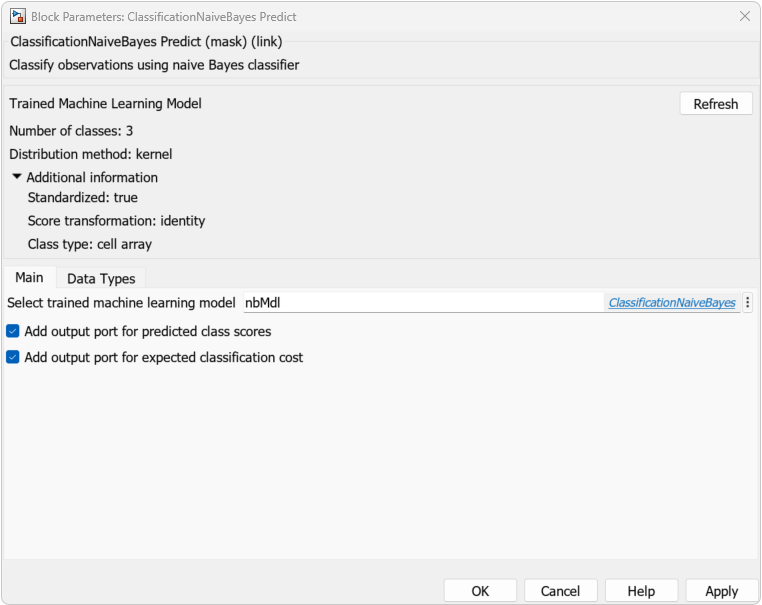
ClassificationNaiveBayes Predict ブロックをダブルクリックして、[ブロック パラメーター] ダイアログ ボックスを開きます。オブジェクトを含むワークスペース変数の名前を指定することにより、学習済みの ClassificationNaiveBayes モデルをブロックにインポートします。既定の変数名は nbMdl です。これは、コマンド ラインで作成したオブジェクトです。
[予測済みクラス スコア用の出力端子を追加] のチェック ボックスをオンにして 2 番目の出力端子 "score" を追加し、[予測される分類コストの出力端子を追加] のチェック ボックスをオンにして 3 番目の出力端子 "cost" を追加します。[OK] をクリックします。
[リフレッシュ] ボタンをクリックして、ダイアログ ボックス内の学習済みモデルの設定を更新します。ダイアログ ボックスの [学習済みの機械学習モデル] セクションに、モデル nbMdl の学習に使用されるオプションが表示されます。[分布方法] セクションに、学習済みの単純ベイズ モデルに関する情報が表示されます。
Inport ブロックを 1 つと Outport ブロックを 3 つ追加して、それらを ClassificationNaiveBayes Predict ブロックに接続します。
4 個の予測子変数をもつデータ セットを使用してモデルに学習させたため、ClassificationNaiveBayes Predict ブロックには 4 個の予測子の値を含む観測値が必要です。Inport ブロックをダブルクリックし、[信号属性] タブで [端子の次元] を 4 に設定します。出力信号を入力信号と同じ長さに指定するには、[Inport] ダイアログ ボックスの [実行] タブで [サンプル時間] を 1 に設定します。[OK] をクリックします。
コマンド ラインで、Simulink モデルの構造体配列の形式で入力信号を作成します。構造体配列には、次のフィールドが含まれていなければなりません。
time— 観測値がモデルに入力された時点。方向は予測子データ内の観測値に対応しなければなりません。この例の場合はtimeが列ベクトルでなければなりません。signals—valuesフィールドとdimensionsフィールドが含まれている、入力データを説明する 1 行 1 列の構造体配列。valuesは予測子データの行列、dimensionsは予測子変数の個数です。
将来の予測用に適切な構造体配列を作成します。
modelInput.time = (0:length(Ytest)-1)'; modelInput.signals(1).values = Xtest; modelInput.signals(1).dimensions = size(Xtest,2);
ワークスペースから信号データをインポートします。
Simulink で [コンフィギュレーション パラメーター] ダイアログ ボックスを開く。[モデル化] タブの [設定] セクションで、[モデル設定] ボタンの上半分をクリック。
[データのインポート/エクスポート] ペインで [入力] チェック ボックスをオンにし、隣のテキスト ボックスに「
modelInput」と入力。[ソルバー] ペインの [シミュレーション時間] で、[終了時間] を
modelInput.time(end)に設定。[ソルバーの選択] で、[タイプ] をFixed-stepに、[ソルバー] をdiscrete (no continuous states)に設定。これらの設定により、modelInputの各クエリ点についてのシミュレーションをモデルで実行できます。[OK] をクリックします。
詳細は、シミュレーションのための信号データの読み込み (Simulink)を参照してください。
モデルを Simulink で slexClassificationNBPredictExample.slx として保存します。
モデルをシミュレーション
Simulink モデルをシミュレートし、シミュレーション出力をワークスペースにエクスポートします。Inport ブロックでは、観測値を検出すると、その観測値を ClassificationNaiveBayes Predict ブロックに配置します。シミュレーション データ インスペクター (Simulink)を使用して、Outport ブロックのログ データを表示できます。
simOut = sim("slexClassificationNBPredictExample");シミュレートされた分類ラベルを調べます。
outputs = simOut.yout;
sim_label = outputs.get("label").Values.Data;真のラベル (Ytest) と Simulink モデルによって予測されたラベル (sim_label) から混同行列チャートを作成します。
confusionchart(string(Ytest),string(sim_label))

対角線上の値が大きい場合は、対応するクラスについての予測が正確であることを示します。
参考
ClassificationNaiveBayes Predict | ClassificationECOC Predict | ClassificationEnsemble Predict | ClassificationSVM Predict | ClassificationLinear Predict | ClassificationNaiveBayes | predict | fitcnb