fit
Local Interpretable Model-agnostic Explanations (LIME) の単純モデルの当てはめ
構文
説明
newresults = fit(results,queryPoint,numImportantPredictors)numImportantPredictors) の重要な予測子を使用して、指定されたクエリ点 (queryPoint) に新しい単純モデルを当てはめます。この関数は、新しい単純モデルを含む lime オブジェクト newresults を返します。
fit は、いつ lime オブジェクト results を作成するかを指定する、単純モデル オプションを使用します。このオプションは、関数 fit の名前と値のペアの引数を使用して変更できます。
newresults = fit(results,queryPoint,numImportantPredictors,Name,Value)'SimpleModelType','tree' を指定して、決定木モデルを当てはめることができます。
例
回帰モデルの学習を行い、線形単純モデルを使用する lime オブジェクトを作成します。lime オブジェクトを作成するときに、クエリ点と重要な予測子の数を指定しなかった場合、ソフトウェアは合成データ セットの標本を生成しますが、単純モデルの当てはめは行いません。オブジェクト関数 fit を使用して、クエリ点に単純モデルを当てはめます。次に、オブジェクト関数 plot を使用して、当てはめた線形単純モデルの係数を表示します。
carbig データ セットを読み込みます。このデータ セットには、1970 年代と 1980 年代初期に製造された自動車の測定値が格納されています。
load carbigAcceleration、Cylinders などの予測子変数と応答変数 MPG が格納された table を作成します。
tbl = table(Acceleration,Cylinders,Displacement,Horsepower,Model_Year,Weight,MPG);
学習セットの欠損値を削除すると、メモリ消費量を減らして関数 fitrkernel の学習速度を向上させることができます。tbl の欠損値を削除します。
tbl = rmmissing(tbl);
tbl から応答変数を削除して、予測子変数のテーブルを作成します。
tblX = removevars(tbl,'MPG');関数fitrkernelを使用して MPG の blackbox モデルの学習を行います。
rng('default') % For reproducibility mdl = fitrkernel(tblX,tbl.MPG,'CategoricalPredictors',[2 5]);
lime オブジェクトを作成します。mdl には予測子データが含まれないため、予測子データ セットを指定します。
results = lime(mdl,tblX)
results =
lime with properties:
BlackboxModel: [1×1 RegressionKernel]
DataLocality: 'global'
CategoricalPredictors: [2 5]
Type: 'regression'
X: [392×6 table]
QueryPoint: []
NumImportantPredictors: []
NumSyntheticData: 5000
SyntheticData: [5000×6 table]
Fitted: [5000×1 double]
SimpleModel: []
ImportantPredictors: []
BlackboxFitted: []
SimpleModelFitted: []
results には、生成された合成データ セットが含まれます。SimpleModel プロパティは空 ([]) です。
tblX の最初の観測値に線形単純モデルを当てはめます。検出する重要な予測子の数を 3 に指定します。
queryPoint = tblX(1,:)
queryPoint=1×6 table
Acceleration Cylinders Displacement Horsepower Model_Year Weight
____________ _________ ____________ __________ __________ ______
12 8 307 130 70 3504
results = fit(results,queryPoint,3);
オブジェクト関数 plot を使用して、lime オブジェクト results をプロットします。
plot(results)

プロットには、クエリ点についての 2 つの予測値が示されています。この予測値は、results のBlackboxFittedプロパティとSimpleModelFittedプロパティに対応します。
横棒グラフは、絶対値で並べ替えられた、単純モデルの係数値を示します。LIME は、クエリ点の重要な予測子として、Horsepower、Model_Year、および Cylinders を見つけます。
Model_Year および Cylinders は複数のカテゴリをもつカテゴリカル予測子です。線形単純モデルの場合、各カテゴリカル予測子について、カテゴリの数よりも 1 つ少ないダミー変数が作成されます。棒グラフには最も重要なダミー変数のみが表示されます。他のダミー変数の係数は results の SimpleModel プロパティを使用して確認できます。すべてのカテゴリカル ダミー変数を含む並べ替えられた係数の値を表示します。
[~,I] = sort(abs(results.SimpleModel.Beta),'descend'); table(results.SimpleModel.ExpandedPredictorNames(I)',results.SimpleModel.Beta(I), ... 'VariableNames',{'Expanded Predictor Name','Coefficient'})
ans=17×2 table
Expanded Predictor Name Coefficient
__________________________ ___________
{'Horsepower' } -3.5035e-05
{'Model_Year (74 vs. 70)'} -6.1591e-07
{'Model_Year (80 vs. 70)'} -3.9803e-07
{'Model_Year (81 vs. 70)'} 3.4186e-07
{'Model_Year (82 vs. 70)'} -2.2331e-07
{'Cylinders (6 vs. 8)' } -1.9807e-07
{'Model_Year (76 vs. 70)'} 1.816e-07
{'Cylinders (5 vs. 8)' } 1.7318e-07
{'Model_Year (71 vs. 70)'} 1.5694e-07
{'Model_Year (75 vs. 70)'} 1.5486e-07
{'Model_Year (77 vs. 70)'} 1.5151e-07
{'Model_Year (78 vs. 70)'} 1.3864e-07
{'Model_Year (72 vs. 70)'} 6.8949e-08
{'Cylinders (4 vs. 8)' } 6.3098e-08
{'Model_Year (73 vs. 70)'} 4.9696e-08
{'Model_Year (79 vs. 70)'} -2.4822e-08
⋮
分類モデルの学習を行い、単純な決定木モデルを使用する lime オブジェクトを作成します。複数のクエリ点に複数のモデルを当てはめます。
CreditRating_Historical データ セットを読み込みます。データ セットには、顧客 ID、顧客の財務比率、業種ラベル、および信用格付けが格納されています。
tbl = readtable('CreditRating_Historical.dat');tbl から顧客 ID と信用格付けの列を削除して、予測子変数の table を作成します。
tblX = removevars(tbl,["ID","Rating"]);
関数fitcecocを使用して、信用格付けの blackbox モデルに学習させます。
blackbox = fitcecoc(tblX,tbl.Rating,'CategoricalPredictors','Industry')
blackbox =
ClassificationECOC
PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'}
ResponseName: 'Y'
CategoricalPredictors: 6
ClassNames: {'A' 'AA' 'AAA' 'B' 'BB' 'BBB' 'CCC'}
ScoreTransform: 'none'
BinaryLearners: {21×1 cell}
CodingName: 'onevsone'
Properties, Methods
blackbox モデルを使用して、lime オブジェクトを作成します。
rng('default') % For reproducibility results = lime(blackbox);
真の信用格付け値がそれぞれ AAA および B となる 2 つのクエリ点を見つけます。
queryPoint(1,:) = tblX(find(strcmp(tbl.Rating,'AAA'),1),:); queryPoint(2,:) = tblX(find(strcmp(tbl.Rating,'B'),1),:)
queryPoint=2×6 table
WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry
_____ _____ _______ ________ _____ ________
0.121 0.413 0.057 3.647 0.466 12
0.019 0.009 0.042 0.257 0.119 1
最初のクエリ点に線形単純モデルを当てはめます。重要な予測子の数を 4 に設定します。
newresults1 = fit(results,queryPoint(1,:),4);
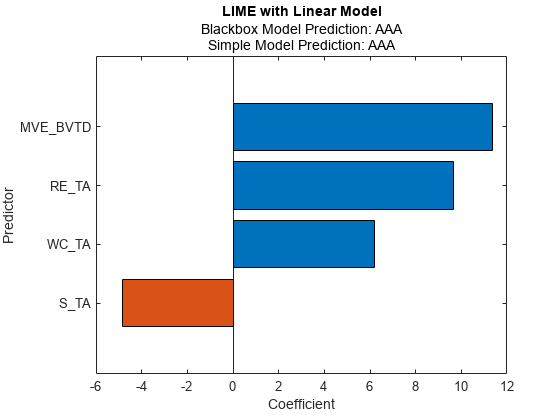
最初のクエリ点についての LIME の結果 newresults1 をプロットします。
plot(newresults1)
最初のクエリ点に線形決定木モデルを当てはめます。
newresults2 = fit(results,queryPoint(1,:),6,'SimpleModelType','tree'); plot(newresults2)

newresults1 および newresults2 の単純モデルはどちらも、重要な予測子として MVE_BVTD および RE_TA を見つけます。
2 番目のクエリ点に線形単純モデルを当てはめ、2 番目のクエリ点についての LIME の結果をプロットします。
newresults3 = fit(results,queryPoint(2,:),4); plot(newresults3)
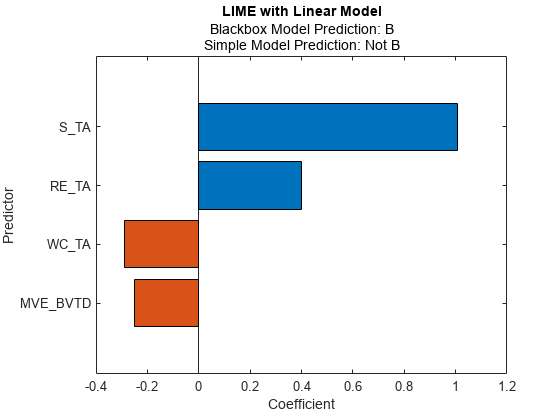
blackbox モデルからの予測値は B ですが、単純モデルからの予測値は B ではありません。2 つの予測値が同じでなければ、小さい方の 'KernelWidth' 値を指定することができます。ソフトウェアは、クエリ点に近い標本に比重を置く重みを使用して、単純モデルを当てはめます。クエリ点が外れ値であるか、判定境界の近くに位置する場合、小さい 'KernelWidth' 値を指定したとしても、2 つの予測値は異なる可能性があります。そのような場合、他の名前と値のペアの引数を変更することができます。たとえば、クエリ点についてのローカルな合成データ セットを生成 (lime の 'DataLocality' を 'local' として指定) し、合成データ セット内の標本数 (lime または fit の 'NumSyntheticData') を増やすことができます。異なる距離計量 (lime または fit の 'Distance') を使用することもできます。
小さな 'KernelWidth' 値で線形単純モデルを当てはめます。
newresults4 = fit(results,queryPoint(2,:),4,'KernelWidth',0.01);
plot(newresults4)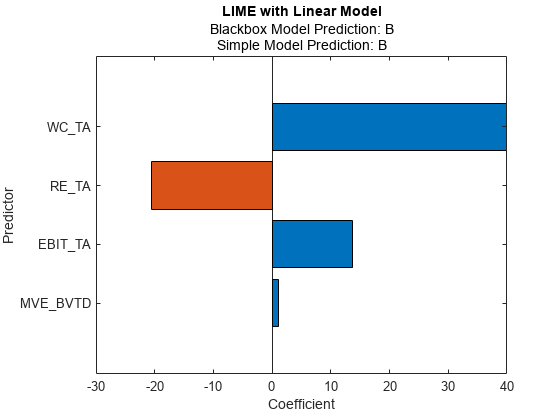
最初のクエリ点と 2 番目のクエリ点の格付けは、それぞれ AAA と B です。newresults1 および newresults4 の単純モデルはどちらも、重要な予測子として MVE_BVTD、RE_TA、および WC_TA を見つけます。ただし、これらの係数値は異なります。プロットは、これらの予測子が信用格付けに応じて異なる動作をすることを示しています。