kfoldMargin
交差検証済み ECOC モデルの分類マージン
説明
margin = kfoldMargin(CVMdl)ClassificationPartitionedECOC) CVMdl によって取得した分類マージンを返します。kfoldMargin は、すべての分割について、学習分割観測値に対して学習をさせた ECOC モデルを使用して、検証分割観測値の分類マージンを計算します。CVMdl.X には、両方の観測値のセットが含まれます。
margin = kfoldMargin(CVMdl,Name,Value)
例
フィッシャーのアヤメのデータ セットを読み込みます。予測子データ X、応答データ Y、および Y 内のクラスの順序を指定します。
load fisheriris X = meas; Y = categorical(species); classOrder = unique(Y); rng(1); % For reproducibility
サポート ベクター マシン (SVM) バイナリ分類器を使用して、ECOC モデルの学習と交差検証を行います。SVM テンプレートを使用して予測子データを標準化し、クラスの順序を指定します。
t = templateSVM('Standardize',1); CVMdl = fitcecoc(X,Y,'CrossVal','on','Learners',t,'ClassNames',classOrder);
CVMdl は ClassificationPartitionedECOC モデルです。既定では、10 分割交差検証が実行されます。名前と値のペアの引数 'KFold' を使用して異なる分割数を指定できます。
検証分割観測値のマージンを推定します。箱ひげ図を使用してマージンの分布を表示します。
margin = kfoldMargin(CVMdl);
boxplot(margin)
title('Distribution of Margins')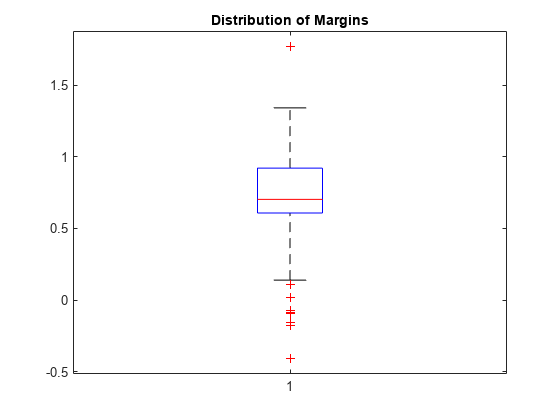
特徴選択を行う方法のひとつとして、複数のモデルからの交差検証マージンを比較します。この条件のみに基づくと、マージンが最大である分類器が最善の分類器となります。
フィッシャーのアヤメのデータ セットを読み込みます。予測子データ X、応答データ Y、および Y 内のクラスの順序を指定します。
load fisheriris X = meas; Y = categorical(species); classOrder = unique(Y); % Class order rng(1); % For reproducibility
次の 2 つのデータ セットを定義します。
fullXにはすべての予測子が含まれます。partXには花弁の寸法が含まれます。
fullX = X; partX = X(:,3:4);
各予測子セットについて、SVM バイナリ分類器を使用して ECOC モデルの学習と交差検証を行います。SVM テンプレートを使用して予測子を標準化し、クラスの順序を指定します。
t = templateSVM('Standardize',1); CVMdl = fitcecoc(fullX,Y,'CrossVal','on','Learners',t,... 'ClassNames',classOrder); PCVMdl = fitcecoc(partX,Y,'CrossVal','on','Learners',t,... 'ClassNames',classOrder);
CVMdl および PCVMdl は ClassificationPartitionedECOC モデルです。既定では、10 分割交差検証が実行されます。
各分類器のマージンを推定します。バイナリ学習器の結果の集約に、損失に基づく復号化を使用します。モデルごとに箱ひげ図を使用してマージンの分布を表示します。
fullMargins = kfoldMargin(CVMdl,'Decoding','lossbased'); partMargins = kfoldMargin(PCVMdl,'Decoding','lossbased'); boxplot([fullMargins partMargins],'Labels',{'All Predictors','Two Predictors'}) title('Distributions of Margins')
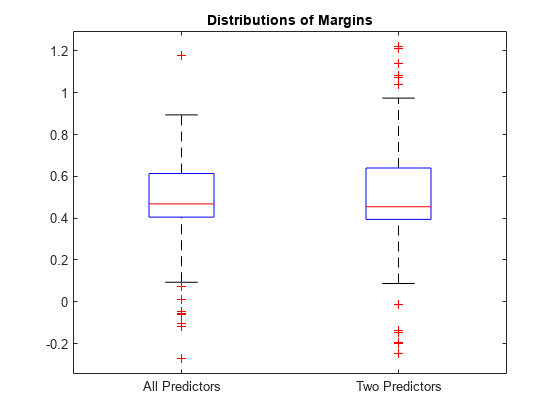
マージンの分布はほぼ同じです。
入力引数
名前と値の引数
出力引数
詳細
参照
拡張機能
バージョン履歴
R2014b で導入