マルチコア プログラミングの概念
マルチコア プログラミングの基礎
マルチコア プログラミングは、マルチコア プロセッサとマルチプロセッサ システムへの展開用に同時実行システムを作成するのに役立ちます。"マルチコア プロセッサ システム" は、1 つのチップ内に複数の実行コアをもつ単一プロセッサです。それとは対照的に、"マルチプロセッサ システム" はマザーボードまたはチップ上に複数のプロセッサをもちます。マルチプロセッサ システムにはフィールド プログラマブル ゲート アレイ (FPGA) が含まれる場合もあります。FPGA はプログラム可能な論理ブロックの配列と再構成可能な相互接続の階層が格納された集積回路です。"処理ノード" は入力データを処理して出力を生成します。これは、マルチコア内のプロセッサまたはマルチプロセッサ システム、または FPGA になります。
マルチコア プログラミング アプローチは、次の場合に役立ちます。
マルチコアと FPGA 処理を利用して組み込みシステムのパフォーマンスを向上する場合。
展開されたシステムが、時間の経過に伴って増加するコアの数や FPGA 処理能力を活用できるようにスケーラビリティを実現する場合。
マルチコア プログラミングを使用して作成する同時実行システムには、並列で実行される複数のタスクがあります。これは、"同時実行" と呼ばれています。プロセッサが複数の並列タスクを実行する場合は、"マルチタスキング" と呼ばれます。CPU には並列で実行されるタスクを処理するスケジューラと呼ばれるファームウェアがあります。CPU はオペレーティング システムのスレッドを使用してタスクを実装します。タスクは独立して実行できますが、たとえばデータ収集モジュールとシステムのコントローラー間でのデータ転送など、一部のデータをタスク間で転送します。つまり、タスク間のデータ転送には "データ依存性" があることになります。
マルチコア プログラミングは、一般的に信号処理とプラント制御システムで使われます。信号処理の場合、複数のフレームを並列で処理する同時実行システムとすることができます。プラント制御システムの場合、コントローラーとプラントは 2 つの個別タスクとして実行できます。マルチコア プログラミングを使用することにより、システムを複数の並列タスクに分割して各タスクを同時に実行できます。
Simulink® は使用されているモデル化方法に関係なくホスト コンピューターのパフォーマンスを最適化しようとします。Simulink でのパフォーマンスの向上方法の詳細については、パフォーマンスの最適化を参照してください。
同時実行システムをモデル化する場合、分割のガイドラインを参照してください。
パラレル化のタイプ
マルチコア プログラミングの概念は、複数のシステム タスクを並列実行させることです。パラレル化には次のタイプがあります。
データのパラレル化
タスクのパラレル化
パイプライン
データのパラレル化
データのパラレル化では、複数の独立したデータを並列に処理します。プロセッサは各データに対して同じ演算を実行します。パラレル化は、データを並列に提供することで実現します。
次の図に、パラレル化のタイミング図を示します。入力を A、B、C および D の 4 つのチャンクに分割します。同じ演算 F() が各チャンクに適用され、出力はそれぞれ OA、OB、OC および OD になります。4 つのタスクはすべて同じであり、これらは並列に実行されます。


プロセッサのサイクルごとにかかる時間 (サイクル時間と呼ばれる) は t = tF になります。
4 つのタスクはすべて同時に実行されるため、合計処理時間も tF になります。パラレル化を使用しない場合、4 つのデータはすべて 1 つの処理ノードで処理されます。各タスクのサイクル時間は tF ですが、各データは連続して処理されるため、合計処理時間は 4*tF になります。
データのパラレル化は、入力データをそれぞれ独立して処理できるシナリオで使用できます。たとえば、処理用に独立したデータセットをもつ Web データベースや、ビデオのフレームを独立して処理する場合などは、パラレル化の候補として適切です。
タスクのパラレル化
データのパラレル化とは対照的に、タスクのパラレル化は入力データを分割しません。その代わりに、アプリケーションを複数のタスクに分割することによってパラレル化を実現します。タスクのパラレル化では、1 つのアプリケーション内のタスクを複数の処理ノードに分散します。一部のタスクが他のタスクにデータ依存性をもつ場合があるため、すべてのタスクが厳密に同時実行されるわけではありません。
4 つの関数が含まれるシステムについて考えます。関数 F2a() と F2b() は並列であり、同時に実行できます。タスクのパラレル化では、計算を 2 つのタスクに分割できます。関数 F2b() は、Task 1 からデータ Out1 を取得した後に別の処理ノードで実行され、Task 1 の F3() に出力を返します。
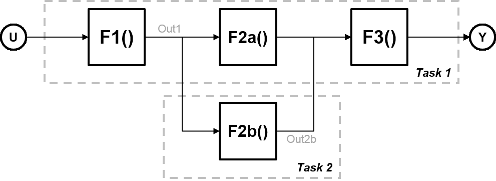
次の図に、パラレル化のタイミング図を示します。Task 2 は、Task 1 からデータ Out1 を取得するまでは実行されません。このため、これらのタスクは完全に並列実行されるわけではありません。プロセッサのサイクルごとにかかる時間 (サイクル時間と呼ばれる) は以下となります。
t = tF1 + max(tF2a, tF2b) + tF3

タスクのパラレル化は、プラントとコントローラーを並列して実行する工場などのシナリオで使用できます。
モデルのパイプライン実行 (パイプライン方式)
モデルのパイプライン実行、またはパイプライン方式を使用して、スレッドが完全には並列実行されないタスクのパラレル化における問題を回避します。このアプローチでは、システム モデルを変更してデータ依存性のあるタスク間に遅延を導入します。
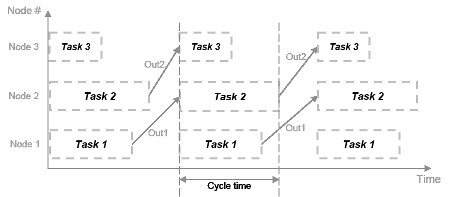
次の図では、システムは 3 つの異なる処理ノードで実行される 3 つのタスクに分割され、関数の間に遅延が導入されています。タイム ステップごとに、各タスクは遅延を使用して前回のタイム ステップから値を取ります。

このタイミング図に示すとおり、各ステップは同時に処理を開始できます。これらのタスクは真に並列であり、1 つのプロセッサのサイクルで直列に相互依存することはなくなります。サイクル時間には追加はありませんが、すべてのタスクの最大処理時間になります。
t = max(Task1, Task2, Task3) = max(tF1, tF2a, tF2b, tF3)
同時実行システムに人為的に遅延を導入できる場合であれば、パイプライン方式を使用できます。この導入に起因するオーバーヘッドは、パイプライン方式によって節約された時間を超過することはできません。
パラレル化のためのシステム分割
分割手法は、同時実行用のシステム領域の指定に役立ちます。分割することで、アプリケーションが展開されるターゲット システムの詳細なタスクを個別に作成できます。
次のシステムについて考えます。F1 ~ F6 は独立して実行可能なシステムの関数です。2 つの関数の間にある矢印はデータ依存性を表します。たとえば、F5 の実行には F3 とのデータ依存性があります。
これらの関数の実行は、ターゲット システム内の異なるプロセッサ ノードに割り当てられます。灰色の矢印は、CPU または FPGA に展開される関数の割り当てを示します。CPU スケジューラは、個々のタスクが実行されるタイミングを決定します。CPU と FPGA は共通の通信バスを介して通信します。

この図は、分割の構成として考えられる一例を示します。アプリケーションに対するタスクの分散が最適化されるまで、さまざまな構成をテストし、繰り返し改善するのが一般的です。
マルチコア プログラミングにおける課題
アプリケーションをマルチコア プロセッサまたは FPGA に手動でコーディングするには、手動コーディングによって生じる問題以上の課題が伴います。同時実行においては、次を追跡しなければなりません。
組み込み処理システムのマルチコア プロセッサで実行されるタスクのスケジュール
さまざまな処理ノード間のデータ転送
Simulink は、タスクの実装およびタスク間のデータ転送を管理します。また、アプリケーションに展開されるコードを生成します。詳細については、Simulink によるマルチコア プログラミングを参照してください。
これらの課題に加え、アプリケーションをさまざまなアーキテクチャに展開する場合や、展開されたアプリケーションのパフォーマンスを改善する場合にも課題が伴います。
移植性: 異なるアーキテクチャへの展開
展開済みアプリケーションを実行するハードウェア構成は、アーキテクチャと呼ばれます。これにはマルチコア プロセッサ、マルチプロセッサ システム、FPGA、あるいはこれらの組み合わせが含まれます。同じアプリケーションを異なるアーキテクチャに展開するには、次の理由から作業が必要になります。
アーキテクチャ上の異なる数とタイプのプロセッサ ノード
アーキテクチャの通信とデータ転送の標準
各アーキテクチャにおける特定のイベント、同期、データ保護の標準
アプリケーションを手動で展開するには、各アーキテクチャの異なる処理ノードにタスクを再度割り当てなければなりません。アーキテクチャごとに異なる標準を使用する場合は、アプリケーションを再実装しなければならない場合もあります。
Simulink は、これらの問題を克服するために、アーキテクチャ間の移植性を提供します。詳細については、Simulink を使用してマルチコア プログラミングにおける課題を克服する方法を参照してください。
展開の効率性
マルチコア処理環境における複数の処理ノードの負荷を均衡化することで、展開済みアプリケーションのパフォーマンスを向上できます。パラレル化のためのシステム分割で説明するとおり、分割中にタスクの分散を繰り返して、改善しなければなりません。このプロセスでは、異なる処理ノード間でのタスクの移動と、結果として得られるパフォーマンスのテストを行います。繰り返し行われるプロセスになるため、最も効率的な分散が見つかるまでには時間がかかります。
Simulink では、プロファイリングを使用してこれらの問題を克服できます。詳細については、Simulink を使用してマルチコア プログラミングにおける課題を克服する方法を参照してください。
周期的なデータ依存性
システムの一部のタスクはその他のタスクの出力に依存します。タスク間のデータ依存性により、処理の順序が決まります。1 つのサイクルにデータ依存性がある 2 つ以上の分割が含まれている場合、"代数ループ" とも呼ばれるデータ依存ループが発生します。
Simulink は、展開前にシステムのループを特定します。詳細については、Simulink を使用してマルチコア プログラミングにおける課題を克服する方法を参照してください。