強化学習を使用した複数の操作点における単一の PI コントローラー ゲインの調整
この例では、強化学習 (RL) アルゴリズムを使用してコントローラーのパラメーターを調整する方法を示します。具体的に言うと、この例は、RL を使用して比例-積分-微分 (PID) のパラメーターを調整する次の 3 つの一般的な方法のうち、最初の方法について説明しています。
1) 複数の操作点における固定された単一の (PI) ゲイン (この例)
2) シミュレーションごとのゲインのスケジューリング
3) オンラインでの適応型 PI ゲイン調整
RL を使用した PI ゲインの調整: 3 つの方法
調整可能なパラメーターの数が少ない比較的単純な制御タスクの場合、モデルベースの調整手法は、モデルフリーの RL ベースの手法と比較して、より高速な調整プロセスで良好な結果を得ることができます。詳細については、制御システムの設計と調整 (Control System Toolbox)およびGet Started with Simulink Design Optimization (Simulink Design Optimization)を参照してください。一方、RL 手法は、非線形性の高いシステムや適応コントローラーの調整により適しています。この例では、単純なシステムにおける PI コントローラーの調整に焦点を当てていますが、より複雑な制御システムにおける一般的なパラメーターの調整やキャリブレーションにもこの例を応用できます。
1. 複数の操作点における単一のゲインの組み合わせ (この例)

- 目標: さまざまなコンテキスト (さまざまな操作条件) において優れた性能を発揮するゲインの組み合わせを 1 つ見つけます。この方法は、プラントの操作条件がわかっており、かつそれらが大幅に変化しないことがわかっている場合にも推奨されます。
- 方法: 重みと PI ゲインが直接対応する線形 RL 方策として PI コントローラーを扱います。方策の重みを学習することは、PI ゲインを調整することと同等です。この方策は、誤差信号に基づいて制御コマンドを出力します。この方法は、パラメーターの調整やキャリブレーションの用途にも応用できます。
- 代替方法: 多くの PI 調整問題では、モデルベースの調整アルゴリズム (制御システム調整器を使用した制御システムの調整 (Simulink Control Design)を参照)、粒子群最適化 (Field-Oriented Control of PMSM Using Fuzzy PI Controller (Fuzzy Logic Toolbox)を参照)、またはベイズ最適化の方が、よりシンプルでサンプル効率が良い場合があります。
2. シミュレーションごとのゲインのスケジューリング

- 目標: プラントの運転中に操作条件 (ここではコンテキストとも言います) が変化しないことを前提として、考えられるコンテキストからその PI ゲインへのマッピングを学習します。ここでは、RL 方策を使用して、指定された操作条件を特定の PI ゲインの組み合わせに関連付けます。
- 方法: コンテキスト バンディット法 (シングルステップ RL とも呼ばれます) を使用し、現在の操作条件に基づいて PI ゲインを選択します。各 RL 環境のステップが 1 回のシミュレーション実行に対応し、シミュレーションが実行されている間 PI ゲインは固定されます。効果的な学習のためには、アクションの範囲 (PI ゲイン) を指定することが推奨されます。コンテキスト バンディット法の例については、Train Reinforcement Learning Agent for Simple Contextual Bandit Problemを参照してください。
- 代替方法: コンテキスト空間が小さい場合、または PI ゲインの範囲がわからない場合は、最初の方法または従来の方法を使用して複数の方策を準備すると、より良好な結果が得られる可能性があります (systune (Simulink Control Design)の例を参照)。エピソード中にコンテキストが変化する場合は、3 番目の方法 (オンラインでの適応型 PI ゲイン調整) を試してください。
3. オンラインでの適応型 PI ゲイン調整

- 目標: ゲインを継続的に調整してパフォーマンスを改善します。これは、プラントの運転中に操作条件や PI ゲインが変化することを許容するため、上記の方法よりも汎用的なアプローチであると言えます。
- 方法: 各タイム ステップにおいて、現在の誤差に基づいて PI ゲインを更新する RL 方策を使用します。追加の観察値としてコンテキストを使用することもできます。
- 代替方法: ダイナミクスがあらかじめ十分にわかっているプラントの場合、RL エージェントの出力が PI ゲインではなく u である RL ベースのコントローラー、またはゲイン スケジューリング (Control System Toolbox)を使用すると、より良好な結果が得られる可能性があります。RL ベースのコントローラーを実装する方法の例については、DDPG エージェントを使用したタンク内の水位の制御を参照してください。
環境モデル
この例では、貯水タンクの環境モデルを使用します。この制御システムの目的は、タンク内の水位を基準値に維持することです。
WaterTankModel = 'watertankLQG';
open_system(WaterTankModel)
モデルには、分散が のプロセス ノイズが含まれています。このモデルで使用されている PID コントローラー ブロックは、離散時間 PID コントローラーです。simout は水位を格納する To Workspace ブロック、cost はシミュレーション中に記録されたコストを格納する To Workspace ブロックです。モデルには、分散が のプロセス ノイズが含まれています。
この例のコントローラーは、制御操作 u を最小限に抑えながら水位 を維持するため、離散時間 PID コントローラーに次の線形 2 次ガウシアン (LQG) 基準を使用します。
ここで、 は目標水位、 はタイム ステップ数、 はサンプル時間です。この LQG 目標には、定常状態の誤差を 0 に近づけるための積分誤差項が含まれています。このモデルでコントローラーをシミュレーションするには、シミュレーション時間 Tf とコントローラーのサンプル時間 Ts を秒単位で指定しなければなりません。
Ts = 1; Tf = 100;
貯水タンク モデルの詳細については、watertank Simulink モデル (Simulink Control Design)を参照してください。
再現性のための乱数ストリームの固定
サンプル コードには、いくつかの段階で乱数の計算が含まれる場合があります。サンプル コード内の複数のセクションの先頭にある乱数ストリームを固定すると、実行するたびにセクション内の乱数シーケンスが維持されるため、結果が再現される可能性が高くなります。詳細については、Results Reproducibilityを参照してください。
シード 0 で乱数ストリームを固定し、メルセンヌ・ツイスター乱数アルゴリズムを使用します。乱数生成に使用されるシード制御の詳細については、rngを参照してください。
previousRngState = rng(0,"twister");出力 previousRngState は、ストリームの前の状態に関する情報が格納された構造体です。例の最後で、状態を復元します。
環境オブジェクトの作成
この例では、観測値に対して線形な強化学習方策として PI コントローラーを実装します。学習セッションは 3000 個のエピソードで構成されています。各エピソードは、100 タイム ステップ持続する Simulink 閉ループ モデルのシミュレーションです。この強化学習エージェントは、シミュレーションが実行されている間、ポンプを操作し、水位とそれに対応する報酬を観察します。そして、期待される累積報酬が最大化されるように、これらの観察結果に基づいてアクター モデルの重み (PI ゲイン) を調整します。
RL エージェントに学習させるためのモデルを定義するには、次の手順を使用して貯水タンク モデルを変更します。
PID Controller を削除します。
RL Agent ブロックを挿入します。
観測値ベクトル を作成します。ここで、 であり、 はタンク内の水位、 は基準水位です。観測信号を RL Agent ブロックに接続します。
RL エージェントの報酬関数をスケーリングされた LQG コストの "負"、つまり として定義します。RL エージェントはこの報酬を最大化することによって LQG コストを最小化します。各ステップの報酬にスケーリング係数
0.01が適用され、期待される報酬の範囲が概ね -1 から 0 の間になるように調整されます。これにより、全体的な最適化の効果が高まります。LQG コストの積分誤差項は強化学習に必須ではありませんが、この例では、後述する制御システム調整器の手法と同じ条件で比較できるように強化学習に含めています。
結果のモデルは rlWatertankPITuningUseCase1.slx です。

rlWatertankPITuningUseCase1 の Water-Tank System を以下に示します。
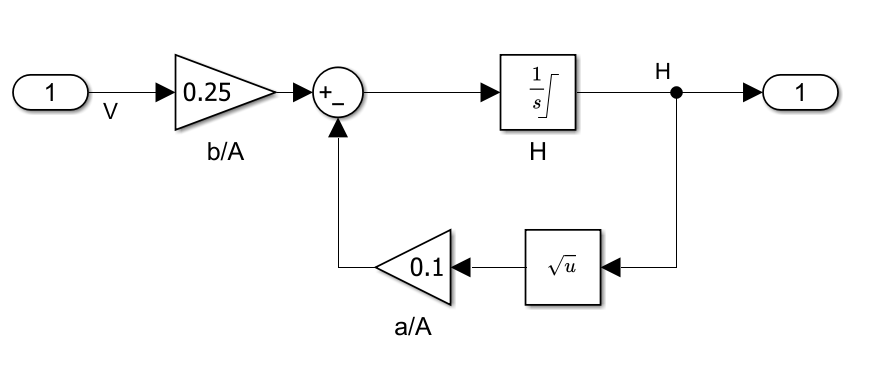
ここで、 はポンプに印加される電圧、 はタンク内の水位です。貯水タンク モデルの詳細については、watertank Simulink モデル (Simulink Control Design)を参照してください。
観測仕様 obsInfo とアクション仕様 actInfo を定義します。
obsInfo = rlNumericSpec([2 1]); obsInfo.Name = 'observations'; obsInfo.Description = 'integrated error and error'; actInfo = rlNumericSpec([1 1]); actInfo.Name = 'PID output'; actInfo.LowerLimit = 0; actInfo.UpperLimit = 12;
rlSimulinkEnv を使用して、貯水タンクの RL 環境オブジェクトを作成します。
mdl = 'rlWatertankPITuningUseCase1'; env = rlSimulinkEnv(mdl,[mdl '/RL Agent'],obsInfo,actInfo);
モデルの基準値と初期水位をランダム化するカスタム リセット関数を設定します。リセット関数を設定するには、この例の終わりで定義されている localResetFcn を使用します。
env.ResetFcn = @(in)localResetFcn(in,mdl);
この環境の観測値およびアクションの次元を抽出します。prod(obsInfo.Dimension) と prod(actInfo.Dimension) を使用して、それぞれ観測空間と行動空間の次元の数 (行ベクトル、列ベクトル、行列のいずれによって構成されているかにかかわらず) を取得します。
numObs = prod(obsInfo.Dimension); numAct = prod(actInfo.Dimension);
RL エージェントの作成
再現性のために乱数ストリームを固定します。
rng(0,"twister");PI コントローラーをアクターとしてモデル化できます。このアクターは、誤差の積分と誤差の両方を入力として使用し、制御信号を出力します。
ここで、以下となります。
uはアクターの出力。KiとKpはアクターの重み。。ここで、 はタンク内の水位、 は基準水位。
アクターを作成するには、例のフォルダーに別個のファイルとして用意されている基底関数 myBasisFcn と共に、rlContinuousDeterministicActorを使用します。
基底関数を実装するファイルを表示します。
type("myBasisFcn.m")function feature = myBasisFcn(obs)
% A basis function for Tune PI Controller Using Reinforcement Learning example
% Copyright 2024 The MathWorks Inc.
feature = obs;
end
コントローラーの初期ゲイン (それぞれ Ki と Kp) を定義します。
initialGain = single([1e-3 2]);
アクターを作成します。詳細については、rlContinuousDeterministicActorを参照してください。
actor = rlContinuousDeterministicActor( ...
{@myBasisFcn,initialGain'},obsInfo, actInfo);この例のエージェントは、双生遅延深層決定論的方策勾配 (TD3) エージェントです。TD3 エージェントは、アクター近似器オブジェクトとクリティック近似器オブジェクトによって最適な方策を学習します。TD3 エージェントは、2 つのクリティック価値関数表現を使用し、観測値とアクションに基づいて長期報酬を近似します。
次のコード セクションで定義されている関数 createCriticNet を使用して、クリティック ネットワークを作成します。両方のクリティック表現に同じネットワーク構造を使用します。
obsInputName = 'stateInLyr'; actInputName = 'actionInLyr'; criticNet1 = createCriticNet(numObs,numAct,obsInputName,actInputName); criticNet2 = createCriticNet(numObs,numAct,obsInputName,actInputName); function criticNet ... = createCriticNet(numObs,numAct,obsInputName,actInputName) statePath = [ featureInputLayer(numObs,Name=obsInputName) fullyConnectedLayer(64,Name='fc1') ]; actionPath = [ featureInputLayer(numAct,Name=actInputName) fullyConnectedLayer(64,Name='fc2') ]; commonPath = [ concatenationLayer(1,2,Name='concat') reluLayer fullyConnectedLayer(64) reluLayer fullyConnectedLayer(1,Name='qvalOutLyr') ]; criticNet = dlnetwork(); criticNet = addLayers(criticNet,statePath); criticNet = addLayers(criticNet,actionPath); criticNet = addLayers(criticNet,commonPath); criticNet = connectLayers(criticNet,'fc1','concat/in1'); criticNet = connectLayers(criticNet,'fc2','concat/in2'); end
指定されたニューラル ネットワーク、環境のアクション仕様と観測仕様、および観測値とアクションのチャネルに接続するネットワーク層の名前を使用して、クリティック オブジェクトを作成します。
critic1 = rlQValueFunction(criticNet1, ... obsInfo,actInfo, ... ObservationInputNames=obsInputName, ... ActionInputNames=actInputName); critic2 = rlQValueFunction(criticNet2, ... obsInfo,actInfo, ... ObservationInputNames=obsInputName,... ActionInputNames=actInputName);
クリティック オブジェクトから成るベクトルを定義します。
critic = [critic1 critic2];
アクターとクリティックの学習オプションを指定します。
actorOpts = rlOptimizerOptions( ... LearnRate=5e-4, ... GradientThreshold=0.5); criticOpts = rlOptimizerOptions( ... LearnRate=5e-4, ... GradientThreshold=0.5);
rlTD3AgentOptionsを使用して TD3 エージェントのオプションを指定します。アクターとクリティックの学習オプションを含めます。
コントローラーのサンプル時間
Tsを使用するようにエージェントを設定。ミニバッチ サイズを
256経験サンプルに設定。経験バッファーの長さを
1e6に設定。各エピソードの最後でエージェントが更新されるように、学習頻度を
-1に設定 (既定値)。エポックあたりのミニバッチの最大数を
20に設定。
agentOpts = rlTD3AgentOptions( ... SampleTime=Ts, ... MiniBatchSize=256, ... DiscountFactor=0.99,... ExperienceBufferLength = 1e6, ... MaxMiniBatchPerEpoch = 20,... LearningFrequency = -1,... ActorOptimizerOptions=actorOpts, ... CriticOptimizerOptions=criticOpts);
探索モデルを変更するには、ドット表記を使用します。
agentOpts.ExplorationModel.StandardDeviation = 0.5; agentOpts.ExplorationModel.StandardDeviationDecayRate = 5e-5; agentOpts.TargetPolicySmoothModel.StandardDeviation = sqrt(0.1);
指定したアクター表現、クリティック表現、およびエージェントのオプションを使用して TD3 エージェントを作成します。詳細については、rlTD3AgentOptionsを参照してください。
agent1 = rlTD3Agent(actor,critic,agentOpts);
RL エージェントの学習
再現性のために乱数ストリームを固定します。
rng(0,"twister");1 ~ 10 の乱数シードを使用して、50 エピソードごとに 10 回のシミュレーションを行ってエージェントのパフォーマンスを評価する evaluator オブジェクトを作成します。乱数シードを変えることで、異なるランダムな初期条件を設定できます。評価スコアは、10 回の評価エピソードにおける平均累積報酬です。
evaluatorObj = rlEvaluator("NumEpisodes",10,... "EvaluationFrequency",50,... "RandomSeeds",1:10);
エージェントに学習させるには、まず次の学習オプションを指定します。
最大
3000個のエピソードについて、各学習を実行 (各エピソードの持続時間は最大100タイム ステップ)。強化学習の学習モニターに学習の進行状況を表示 (
Plotsオプションを "training-progress" として設定)。コマンドラインの表示を無効化 (
Verboseオプションをtrueに設定)。評価スコアが
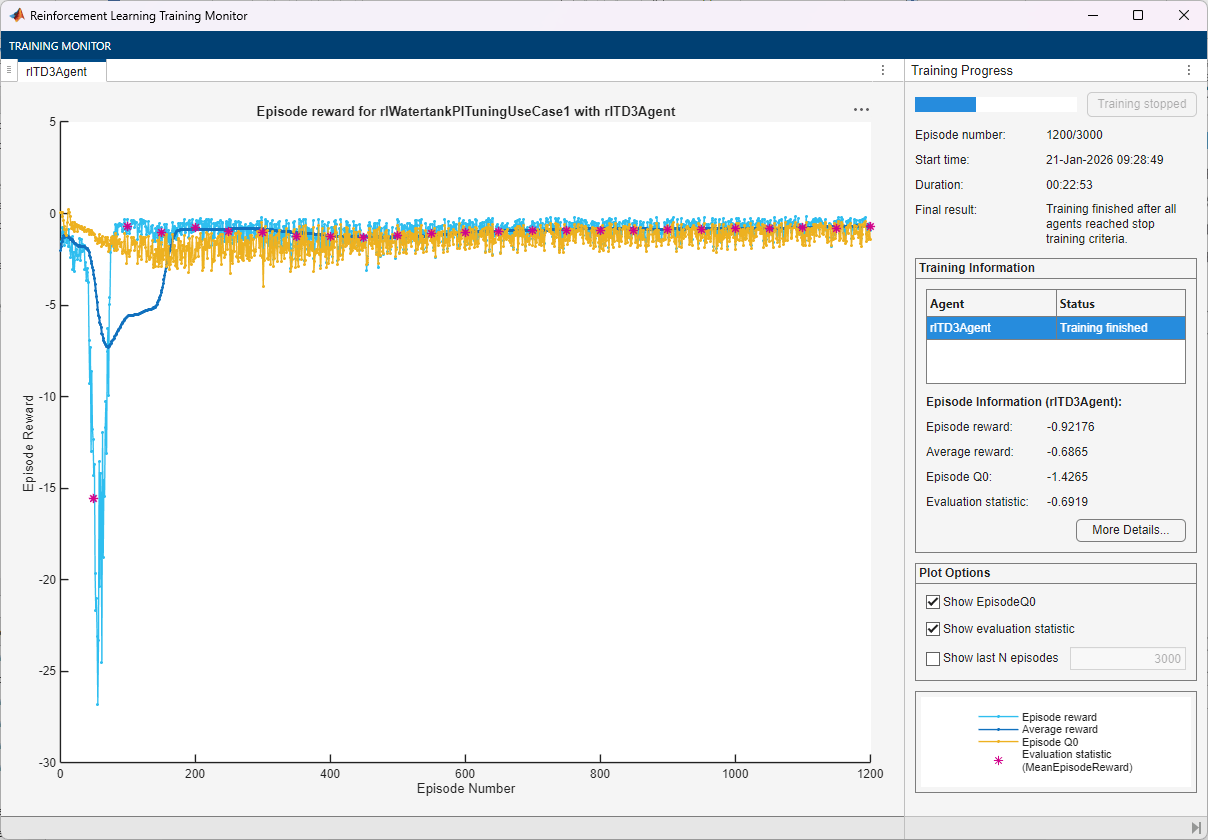
-0.7に達したら学習を停止。この時点で、エージェントはタンクの水位を制御できます。
学習オプションの詳細については、rlTrainingOptionsを参照してください。
maxepisodes = 3000; maxsteps = ceil(Tf/Ts); trainOpts = rlTrainingOptions( ... MaxEpisodes=maxepisodes, ... MaxStepsPerEpisode=maxsteps, ... ScoreAveragingWindowLength=100, ... Verbose=false, ... Plots="training-progress", ... StopTrainingCriteria="EvaluationStatistic", ... StopTrainingValue=-0.7);
関数 train を使用して、エージェントに学習させます。このエージェントの学習は計算量が多いプロセスです。この例の実行時間を節約するために、doTraining を false に設定して事前学習済みのエージェントを読み込みます。エージェントに学習させるには、doTraining を true に設定します。
doTraining =false; if doTraining % Train the agent. trainingStats = train(agent1,env,trainOpts,Evaluator=evaluatorObj); save("WaterTankPITuningTD3AgentUseCase1.mat","agent1") else % Load pretrained agent for the example. load("WaterTankPITuningTD3AgentUseCase1.mat","agent1") end
学習済みエージェントの検証
再現性のために乱数ストリームを固定します。
rng(0,"twister");既定では、エージェントはシミュレーション時に貪欲 (したがって決定的) 方策を使用します。代わりに探索方策を使用するには、UseExplorationPolicy エージェントのプロパティを true に設定します。学習済みエージェントを検証するには、環境内でエージェントのシミュレーションを maxsteps ステップ実行します。エージェントのシミュレーションの詳細については、simを参照してください。
simOpts = rlSimulationOptions(MaxSteps=maxsteps); experiences = sim(env,agent1,simOpts);
RL と制御システム調整器のゲインの性能比較
Simulink では、制御システム調整器 (CST) を使用してコントローラーを調整できます。これを行うには、コントローラー ブロックを調整済みブロックとして指定し、調整プロセスの目標を定義してから、[調整] タブで [調整] をクリックしなければなりません。"制御システム調整器" の使用の詳細については、制御システム調整器を使用した制御システムの調整 (Simulink Control Design)を参照してください。
CST を使用して得られた PI ゲインの値を以下に示します。
Kp_CST = 3.43726595858363; Ki_CST = 0.0357784909005128;
RL コントローラーの PI ゲインは、アクター近似モデルの重みです。重みを取得するには、まずアクターから学習可能なパラメーターを抽出します。
actor = getActor(agent1); parameters = getLearnableParameters(actor);
コントローラーのゲインを取得します。
Ki = parameters{1}(1)Ki = single
0.1130
Kp = parameters{1}(2)Kp = single
3.8090
学習済みの RL エージェントから取得したゲインを元の PI コントローラー ブロックに適用し、ステップ応答シミュレーションを実行します。
open_system(WaterTankModel); set_param(WaterTankModel,"FastRestart","off")
Simulink.SimulationInput (Simulink)オブジェクト simIn を使用して、それぞれのブロック内のノイズ、基準値、および初期水位の乱数シードを一時的に設定します。
refWaterLevel = 10; initialWaterLevel = 1; randomSeed = 1; simIn = Simulink.SimulationInput(WaterTankModel); noiseBlk = sprintf([WaterTankModel '/Band-Limited\nWhite Noise/']); simIn = setBlockParameter(simIn,noiseBlk,'Seed',num2str(randomSeed)); refBlk = sprintf([WaterTankModel '/Desired \nWater Level']); simIn = setBlockParameter(simIn,refBlk,'Value',num2str(refWaterLevel)); initBlk = [WaterTankModel '/Water-Tank System/H']; simIn = setBlockParameter(simIn,initBlk,'InitialCondition',num2str(initialWaterLevel));
PID コントローラー ブロックで、学習済みの RL エージェントから取得した PI ゲインを設定します。
PIBlk = [WaterTankModel '/PID Controller']; set_param([WaterTankModel '/PID Controller'],'P',num2str(Kp)) set_param([WaterTankModel '/PID Controller'],'I',num2str(Ki))
Simulink のsim関数を使用して、一時的な変更が適用された貯水タンク モデルをシミュレーションします。シミュレーション中に記録された水位とコストを simResult に収集します。これらの値は、モデル内の To Workspace ブロック (simout および cost) を使用して取得されたものです。
simResults = sim(simIn); rlStep1 = simResults.simout; rlCost1 = simResults.cost;
開ループ システムの安定余裕を計算します。安定余裕を計算するには、この例の終わりで定義されている localStabilityAnalysis 関数を使用します。この関数は、指定された時点におけるシステムのスナップショットに対する複数の安定余裕が格納された構造体を返します。ここでは、50 秒の時間が選択されています。100 秒間のシミュレーションの中間点であり、システムが定常状態になる、または定常状態に近くなると予想される時間であるためです。
blockIn = [WaterTankModel '/Sum1']; blockOut = [WaterTankModel '/Water-Tank System']; stabilityAnalysisTime = 50; rlStabilityMargin = localStabilityAnalysis(WaterTankModel,... blockIn,... blockOut,... stabilityAnalysisTime);
"制御システム調整器" を使用して取得したゲインを元の PI コントローラー ブロックに適用し、ステップ応答シミュレーションを実行します。
set_param([WaterTankModel '/PID Controller'],'P',num2str(Kp_CST)) set_param([WaterTankModel '/PID Controller'],'I',num2str(Ki_CST))
Simulink のsim関数を使用して、一時的な変更が適用された貯水タンク モデルをシミュレーションします。シミュレーション結果を simResult に収集します。
simResults = sim(simIn); cstStep = simResults.simout; cstCost = simResults.cost;
localStabilityAnalysis を使用して、開ループ システムの安定余裕を計算します。RL コントローラーと同じ stabilityAnalysisTime の値である 50 秒を使用します。
cstStabilityMargin = localStabilityAnalysis(WaterTankModel,... blockIn,... blockOut,... stabilityAnalysisTime);
stepinfo (Control System Toolbox)関数を使用して、両方のシミュレーションのステップ応答を解析します。
rlStepInfo = stepinfo(rlStep1.Data,rlStep1.Time); cstStepInfo = stepinfo(cstStep.Data,cstStep.Time);
stepinfo (Control System Toolbox)から返される構造体を table 変数に変換します。table データ型の詳細については、tableを参照してください。
stepInfoTable = struct2table([cstStepInfo rlStepInfo]);
stepInfoTable = removevars(stepInfoTable,{'SettlingMin', ...
'TransientTime','SettlingMax','Undershoot','PeakTime'});
stepInfoTable.Properties.RowNames = {'CST','RL1'};table を表示します。
stepInfoTable
stepInfoTable=2×4 table
RiseTime SettlingTime Overshoot Peak
________ ____________ _________ ______
CST 2.8482 3.896 0.75978 9.9904
RL1 2.8737 12.582 2.7717 10.269
安定余裕構造体を table 変数に変換します。
stabilityMarginTable = struct2table( ...
[cstStabilityMargin rlStabilityMargin]);不要な変数を削除し、行名を追加します。
stabilityMarginTable = removevars(stabilityMarginTable,{...
'GMFrequency','PMFrequency','DelayMargin','DMFrequency'});
stabilityMarginTable.Properties.RowNames = {'CST','RL1'};安定余裕の table を表示します。
stabilityMarginTable
stabilityMarginTable=2×3 table
GainMargin PhaseMargin Stable
__________ ___________ ______
CST 2.3401 67.134 true
RL1 2.1324 63.126 true
どちらのコントローラーも安定した応答を示しています。
2 つのコントローラーの累積 LQG コストを計算します。
rlCumulativeCost = sum(rlCost1.Data)
rlCumulativeCost = -155.3710
cstCumulativeCost = sum(cstCost.Data)
cstCumulativeCost = -155.7214
ステップ応答、安定余裕、および LQG コストの結果は、2 つの調整方法で同程度となっています。
ローカル関数
localResetFcn 関数は、基準信号と初期水位をランダム化します。
function in = localResetFcn(in,mdl) % Randomize disturbance signal. randomSeed = randi(10000); noiseBlk = sprintf([mdl '/Band-Limited\nWhite Noise/']); in = setBlockParameter(in,noiseBlk,'Seed',num2str(randomSeed)); % Randomize reference signal. hRef = 10 + 4*(rand-0.5); hRefBlk = sprintf([mdl '/Desired \nWater Level']); in = setBlockParameter(in,hRefBlk,'Value',num2str(hRef)); % Randomize initial water level. hInit = 2*rand; hInitBlk = [mdl '/Water-Tank System/H']; in = setBlockParameter(in,hInitBlk,'InitialCondition',num2str(hInit)); end
localStabilityAnalysis 関数は、ループ開始点の解析ポイントを使用して、指定された時間における閉ループ モデルを線形化することにより、安定余裕を計算します。
function margin = localStabilityAnalysis(mdl,blockIn,blockOut,time) set_param(mdl,"FastRestart","off") io(1) = linio(blockIn,1,'input'); io(2) = linio(blockOut,1,'openoutput'); op = operpoint(mdl); op.Time = time; linsys = linearize(mdl,io,op); margin = allmargin(linsys); end
参考
関数
train|sim|rlSimulinkEnv