用途
強化学習を適用する方法の例
強化学習は、制御、ロボティクス、スケジューリング、最適化、金融など、幅広い分野のさまざまな問題に適用できます。こちらはその例です。
チュートリアル
- DDPG エージェントを使用したタンク内の水位の制御
Simulink® で学習環境としてモデル化されたプラントを使用し、強化学習を使ってコントローラーに学習させる。 - 強化学習を使用した複数の操作点における単一の PI コントローラー ゲインの調整
TD3 エージェントを使用して PI コントローラーのゲインを調整する。 - Train SAC Agent for Ball Balance Control
Train a SAC agent to balance a ball on a flat surface using a robot arm. - Train Default TD3 Agent to Control Quanser QUBE Pendulum
Train a TD3 agent to balance the Quanser QUBE rotational inverted pendulum. - Train Reinforcement Learning Agent Offline to Control Quanser QUBE Pendulum
Train TD3 agent offline to control a Quanser QUBE pendulum. - Train TD3 Agent for PMSM Control
Train a TD3 agent to control the currents in a permanent magnet synchronous motor. - 強化学習を使用した PMSM のベクトル制御 (Motor Control Blockset)
この例では、強化学習の制御設計法を使用して永久磁石同期モーター (PMSM) のベクトル制御 (FOC) を実装する方法を示します。 - Train DQN Agent with LSTM Network to Control House Heating System
Train a DQN agent with a recurrent network to control the temperature of an house. - 制約の適用を使用した強化学習エージェントの学習 (Simulink Control Design)
Constraint Enforcement ブロックを使用してアクションを制約して強化学習エージェントに学習させる。 - Create and Train Custom LQR Agent
Create a custom agent that solves an LQR problem and train it using the built-in train function. - 滑走ロボットを制御するための DDPG エージェントの学習
摩擦のない 2 次元平面上を滑走するロボットを制御するために DDPG エージェントに学習させる。 - Train Default PPO Agent for Discrete Lander Vehicle
Train a default PPO agent to land a discrete action space flying vehicle. - Train Soft Actor Critic Agent with Custom Networks for Discrete Lander Vehicle
Train a SAC agent to land a discrete action space flying vehicle. - 強化学習エージェントを使用した二足歩行ロボットの学習
Simscape™ Multibody™ でモデル化された二足歩行ロボットを制御するために、DDPG と TD3 エージェントを比較する。 - Add Safety Constraint to Simulate Two-Link Robot with SAC Agent
Add high-order barrier function to safely simulate a two-link robot model with a SAC agent. - Train Biped Robot to Walk Using Evolution Strategy-Reinforcement Learning Agents
Train TD3 agent using evolutionary strategy. - DDPG エージェントを使用した四足歩行ロボットの移動
Simscape Multibody でモデル化された四足歩行ロボットを制御するために DDPG エージェントに学習させる。 - Generate Reward Function from a Model Predictive Controller for a Servomotor
Generate a reward function from an MPC controller applied to a servomotor and use it to train a TD3 agent. - Generate Reward Function from a Model Verification Block for a Water Tank System
Generate a reward function from an model verification block applied to a water tank system and use it to train a TD3 agent. - Imitate MPC Controller for Lane Keeping Assist
Train a deep neural network to imitate the behavior of a model predictive controller within a lane keeping assist system. - Imitate Nonlinear MPC Controller for Sliding Robot
Train a deep neural network to imitate the behavior of a nonlinear model predictive controller for a robot siding on a 2-D frictionless plane. - Train DDPG Agent with Pretrained Actor Network
Train a DDPG agent using an actor network that has been previously trained using supervised learning. - 車線維持支援用 DQN エージェントの学習
車線維持支援アプリケーション用に DQN エージェントに学習させる。 - Train PPO Agent with Curriculum Learning for a Lane Keeping Application
Train a PPO agent for a lane keeping assist task by gradually increasing task complexity. - アダプティブ クルーズ コントロール用の DDPG エージェントの学習
アダプティブ クルーズ コントロール アプリケーション用の DDPG エージェントに学習させる。 - 経路追従制御用の DDPG エージェントの学習
車線追従制御用に DDPG エージェントに学習させる。 - Train Multiple Agents for Path Following Control
Train a DQN and a DDPG agent to collaboratively perform adaptive cruise control and lane keeping assist to follow a path. - Train Hybrid SAC Agent for Path-Following Control
Train a hybrid SAC agent for lane following control. - Train Hybrid-Action PPO Agent for Path-Following Control
Train a hybrid PPO agent for lane following control. - Train PPO Agent for Automatic Parking Valet
Train a discrete action space PPO agent to park a car in an open parking space. - Train Reinforcement Learning Agent for Simple Contextual Bandit Problem
Train Q and DQN agents to solve a contextual bandit problem. - Why Solving Regression Using Reinforcement Learning is Not Recommended
Using a reinforcement learning agent to solve a regression problem is possible but not recommended. - Why Solving Classification Using Reinforcement Learning Is Not Recommended
Using a reinforcement learning agent to solve a classification problem is possible but not recommended. - Train Agent to Play Turn-Based Game
Train a DQN agent to play a turn-based game. - Deep Reinforcement Learning for Optimal Trade Execution
This example shows how to use the Reinforcement Learning Toolbox™ and Deep Learning Toolbox™ to design agents for optimal trade execution. - Multiperiod Goal-Based Wealth Management Using Reinforcement Learning
This example shows a reinforcement learning (RL) approach to maximize the probability of obtaining an investor's wealth goal at the end of the investment horizon. - Train DQN Agent for Beam Selection (5G Toolbox)
Train a deep Q-network (DQN) reinforcement learning agent for beam selection in a 5G new radio communications system. (R2022b 以降) - Water Distribution System Scheduling Using Reinforcement Learning
Train a DQN agent to optimally activate pumps in a water distribution system.
制御タスクの実行のためのエージェントの学習
ロボットの制御のためのエージェントの学習
制御仕様からの報酬の生成
模倣学習
自動車用途向けのエージェントの学習
コンテキスト バンディット問題
その他の用途
注目の例

Identify Vulnerabilities in DC Microgrids
Train a TD3 agent to attack a cyber-physical system to identify vulnerabilities.
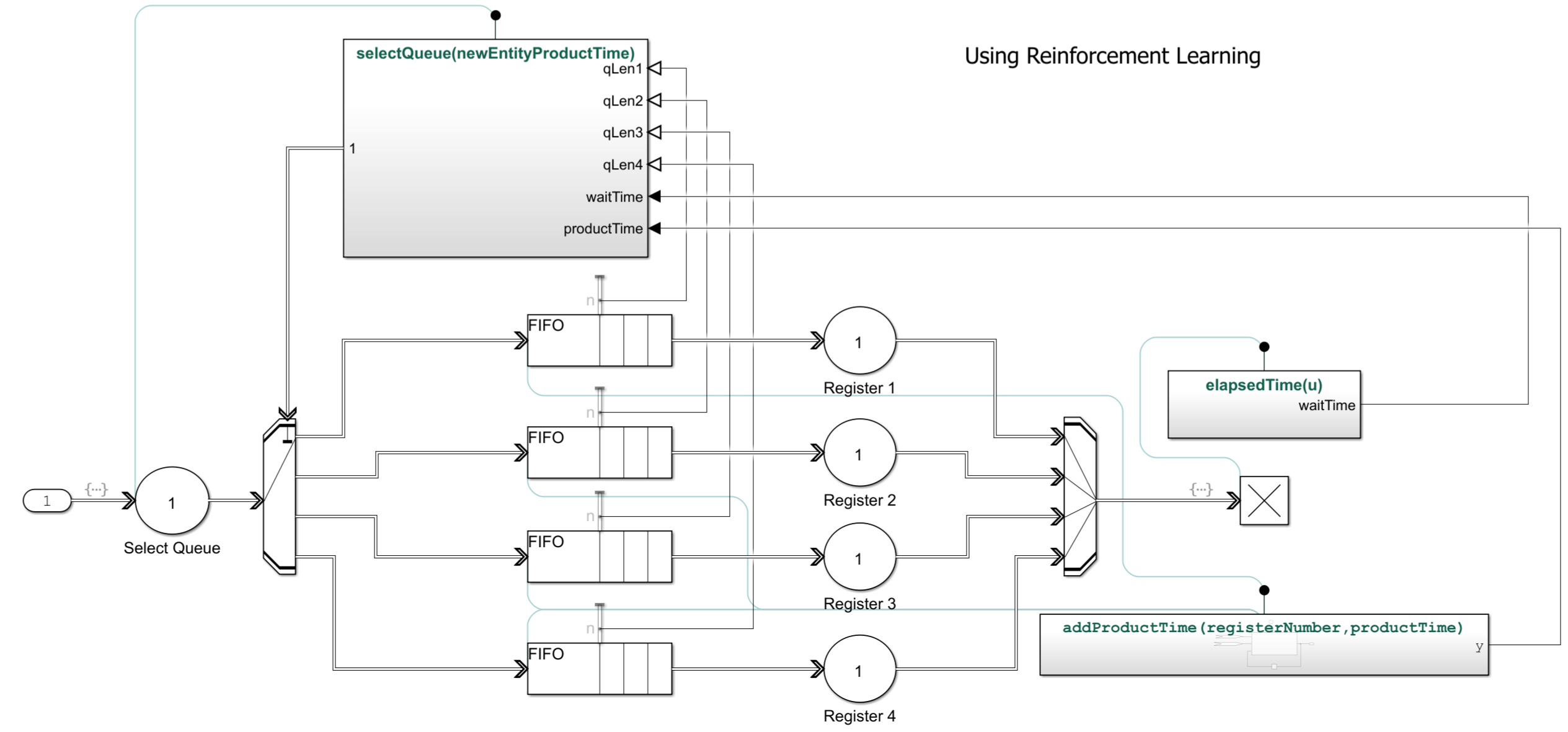
Optimizing Queue Selection Strategies Using Reinforcement Learning
Train a DQN agent to optimally route customers through a multi-queue checkout system.

Automatic Parking Valet with Unreal Engine Simulation
Use a TD3 agent with an MPC controller to perform a parking maneuver.

DDPG エージェントを使用した四足歩行ロボットの移動
Simscape Multibody でモデル化された四足歩行ロボットを制御するために DDPG エージェントに学習させる。