Train DQN Agent with LSTM Network to Control House Heating System
This example shows how to train a deep Q-learning network (DQN) agent with a Long Short-Term Memory (LSTM) network to control a house heating system modeled in Simscape™. For more information on DQN agents, see Deep Q-Network (DQN) Agent.
Fix Random Number Seed to Improve Reproducibility
The example code might involve computation of random numbers at several stages. Fixing the random number stream at the beginning of some sections in the example code preserves the random number sequence in the section every time you run it, which increases the likelihood of reproducing the results. For more information, see Results Reproducibility.
Fix the random number stream with seed 0 and random number algorithm Mersenne twister. For more information on controlling the seed used for random number generation, see rng.
previousRngState = rng(0, "twister");The output previousRngState is a structure that contains information about the previous state of the stream. You will restore the state at the end of the example.
House Heating Simulink Model
The reinforcement learning (RL) environment for this example uses the Simulink® model described in the House Heating System (Simscape) example. The model contains a heater block, a thermostat block (which contains an RL agent block and a reward block) and the House Thermal Network block (modeled in Simscape). Heat moves between the interior of the home and the outside environment through the walls, windows, and roof. You use weather station data between March 21 and April 15, 2022, to simulate the outside temperature.For more information about the data acquisition, see Compare Temperature Data from Three Different Days (ThingSpeak).
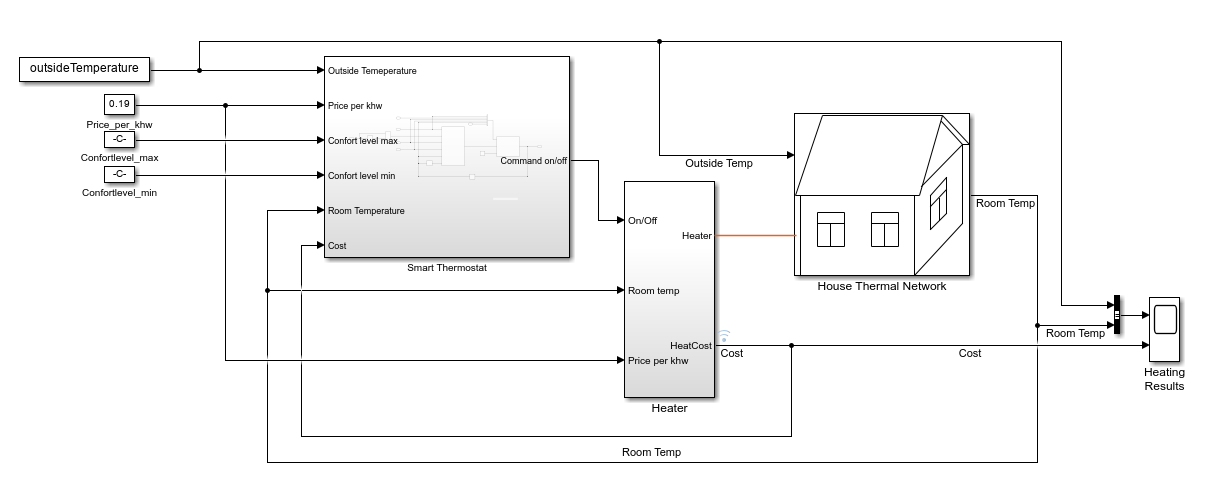
The training goal for the agent is to minimize the energy cost and maximize the amount of time the house is in the comfortable temperature range by turning on/off the heater. The house is comfortable when its interior temperature is between and .
The reinforcement learning problem is defined as follows:
The observation is a 6-dimensional column vector that consists of the room temperature (), outside temperature (), maximum comfort temperature (), minimum comfort temperature (), last action, and price per kWh (USD).
The action is discrete. Specifically, the action 0 represents turning the heater off, and the action 1 represents turning it on.
The reward block calculates the total reward as the sum of the comfort reward and a penalty for switching , from which an energy cost is subtracted: . These three components are defined as follows.
where , and .
The reward function is inspired by [1].
The Is-Done signal supplied to the RL Agent block is always
0, indicating that there is no early termination condition.
Define Simulink Environment
Open the model.
mdl = "rlHouseHeatingSystem";
open_system(mdl)Define the sample time and the maximum number of steps per episode. You need these variables for the script and reset functions.
sampleTime = 120; % seconds
maxStepsPerEpisode = 1000;Assign the agent block path information to the agentBlk variable, for later use.
agentBlk = mdl + "/Smart Thermostat/RL Agent";Load the outside temperature data to simulate the environment temperature.
data = load('temperatureMar21toApr15_2022.mat');
temperatureData = data.temperatureData;Extract validation data.
temperatureMarch21 = temperatureData(1:60*24,:); temperatureApril15 = temperatureData(end-60*24+1:end,:);
Extract training data.
temperatureData = temperatureData(60*24+1:end-60*24,:);
The Simulink model loads the outside temperature history, the maximum comfort temperature, and the minimum comfort temperature. These variables are part of the observation vector.
outsideTemperature = temperatureData; comfortMax = 23; comfortMin = 18;
Define the observation and action specifications.
obsInfo = rlNumericSpec([6,1]);
actInfo = rlFiniteSetSpec([0,1]); % (0=off,1=on)Create an environment object for the house heating environment.
env = rlSimulinkEnv(mdl,agentBlk,obsInfo,actInfo);
Use hRLHeatingSystemResetFcn to reset the environment at the beginning of each episode. This function randomly selects a time between March 22 and April 14 such that at least maxStepsPerEpisode samples are available. The environment uses this time as the initial time for the outside temperatures. For more information, see Reset Function for Simulink Environments.
env.ResetFcn = @(in) hRLHeatingSystemResetFcn(in);
Create DQN Agent with LSTM Network
DQN agents use a parameterized Q-value function approximator to estimate the value of the policy. Because DQN agents have a discrete action space, you have the option to create a vector (that is, multi-output) Q-value function critic, which is generally more efficient than a comparable single-output critic.
A vector Q-value function takes only the observation as input and returns as output a single vector with as many elements as the number of possible actions. The value of each output element represents the expected discounted cumulative long-term reward when an agent starts from the state corresponding to the given observation and executes the action corresponding to the element number (and follows a given policy afterwards).
Fix the random number stream.
rng(0, "twister");Specify training options for the critic and the actor using rlOptimizerOptions.
criticOpts = rlOptimizerOptions( ... LearnRate=0.001, ... GradientThreshold=1);
Specify the DQN agent options using rlDQNAgentOptions, include the training options for the critic.
agentOpts = rlDQNAgentOptions( ... UseDoubleDQN = false, ... TargetSmoothFactor = 1, ... TargetUpdateFrequency = 4, ... ExperienceBufferLength = 1e6, ... CriticOptimizerOptions = criticOpts, ... MiniBatchSize = 64);
You can also set or modify the agent options using dot notation.
agentOpts.EpsilonGreedyExploration.EpsilonDecay = 0.0001;
To model the parameterized Q-value function within the critic, use a recurrent neural network, which can capture the effect of previous observations. By setting the UseRNN option in rlAgentInitializationOptions, you can create a default DQN agent with an LSTM network. Alternatively, you can manually configure the LSTM network. See Water Distribution System Scheduling Using Reinforcement Learning to create an LSTM network for the DQN agent manually.
useRNN =true; initOpts = rlAgentInitializationOptions( ... UseRNN=useRNN, ... NumHiddenUnit=64);
When using a recurrent neural network, you must set SequenceLength to be greater than 1 in rlDQNAgentOptions. This option is used in training to determine the length of the mini-batch used to calculate the gradient. For more information about LSTM layers, see Long Short-Term Memory Neural Networks.
if useRNN agentOpts.SequenceLength = 20; end
Create a DQN agent with default critic network using rlDQNAgent, the agent initialization options object (which specify that a recurrent network is needed), and the agent options object.
agent = rlDQNAgent(obsInfo, actInfo, initOpts, agentOpts);
You can also modify the agent options, including the critic options, using dot notation. For example, specify the agent sample time.
agent.SampleTime = sampleTime;
Train Agent
To train the agent, first specify the training options. For this example, use the following options.
Run training for a maximum of 500 episodes, with each episode lasting 1000 time steps.
Set the
Plotsoption to"training-progress", which displays training progress in the Reinforcement Learning Training MonitorSet the
Verboseoption tofalseto disable the command line display.Stop the training when the agent receives a mean evaluation episode reward greater than 85.
For more information on training options, see rlTrainingOptions.
trainOpts = rlTrainingOptions( ... MaxEpisodes = 500, ... MaxStepsPerEpisode = maxStepsPerEpisode, ... ScoreAveragingWindowLength = 5, ... Verbose = false, ... Plots = "training-progress", ... StopTrainingCriteria = "EvaluationStatistic", ... StopTrainingValue = 85);
Fix the random number stream.
rng(0, "twister");Train the agent using the train function. Training this agent is a computationally-intensive process that takes several hours to complete. To save time while running this example, load a pretrained agent by setting doTraining to false. To train the agent yourself, set doTraining to true.
doTraining =false; if doTraining % Evaluate the agent every 25 training episodes. evl = rlEvaluator( ... EvaluationFrequency=25, ... NumEpisodes=3, ... RandomSeeds=[1:3]); % Train the agent. trainingStats = train(agent,env,trainOpts,Evaluator=evl); else % Load the pretrained agent for the example. load("HeatControlDQNAgent.mat","agent") end

Simulate DQN Agent
To validate the performance of the trained agent, simulate it within the house heating system. For more information on agent simulation, see rlSimulationOptions and sim.
Fix the random number stream.
rng(0, "twister");First, evaluate the agent's performance using the temperature data from March 21st, 2022. The agent did not use this temperature data for training.
maxSteps= 720; validationTemperature = temperatureMarch21; env.ResetFcn = @(in) hRLHeatingSystemValidateResetFcn(in); simOptions = rlSimulationOptions(MaxSteps = maxSteps); experience1 = sim(env,agent,simOptions);
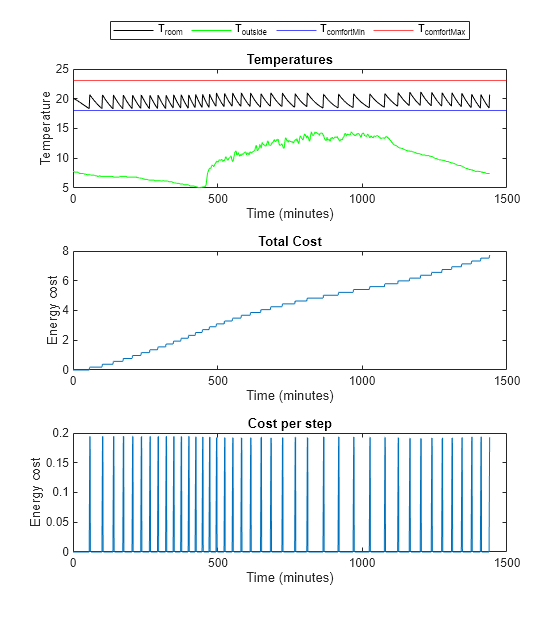
Use the localPlotResults function, provided at the end of the example, to analyze the performance.
localPlotResults(experience1, maxSteps, ...
comfortMax, comfortMin, sampleTime,1)
Comfort Temperature violation: 0/1440 minutes, cost: 7.717194 dollars
Next, evaluate the agent's performance using the temperature data from April 15th, 2022. The agent did not use this temperature data during training either.
% Validate agent using the data from April 15
validationTemperature = temperatureApril15;
experience2 = sim(env,agent,simOptions);
localPlotResults( ... experience2, ... maxSteps, ... comfortMax, ... comfortMin, ... sampleTime,2)

Comfort Temperature violation: 0/1440 minutes, cost: 8.259467 dollars
Evaluate the agent's performance when the temperature is mild. Add eight degrees to the temperature from April 15th to create data for mild temperatures.
% Validate agent using the data from April 15 + 8 degrees
validationTemperature = temperatureApril15;
validationTemperature(:,2) = validationTemperature(:,2) + 8;
experience3 = sim(env,agent,simOptions);
localPlotResults(experience3, ... maxSteps, ... comfortMax, ... comfortMin, ... sampleTime, ... 3)
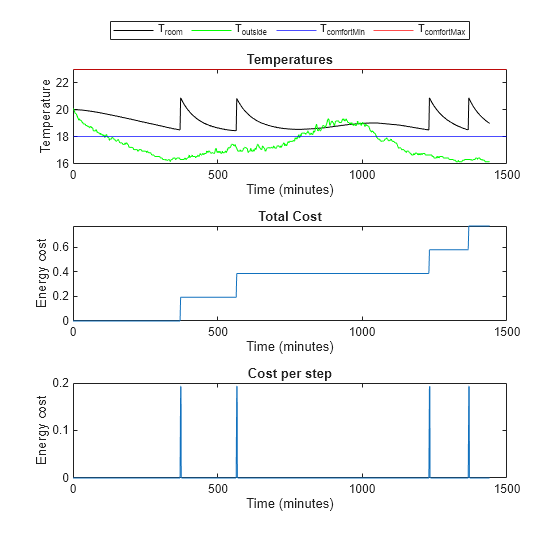
Comfort Temperature violation: 0/1440 minutes, cost: 0.771909 dollars
Restore the random number stream using the information stored in previousRngState.
rng(previousRngState)
Local Function
function localPlotResults( ... experience, maxSteps, comfortMax, comfortMin, sampleTime, figNum) % localPlotResults plots results of validation % Compute comfort temperature violation obsData = experience.Observation.obs1.Data(1,:,1:maxSteps); minutesViolateComfort = ... sum(obsData < comfortMin) ... + sum(obsData > comfortMax); % Cost of energy totalCosts = ... experience.SimulationInfo(1).househeat_output{1}.Values; totalCosts.Time = totalCosts.Time/60; totalCosts.TimeInfo.Units="minutes"; totalCosts.Name = "Total Energy Cost"; finalCost = totalCosts.Data(end); % Cost of energy per step costPerStep = ... experience.SimulationInfo(1).househeat_output{2}.Values; costPerStep.Time = costPerStep.Time/60; costPerStep.TimeInfo.Units="minutes"; costPerStep.Name = "Energy Cost per Step"; minutes = (0:maxSteps)*sampleTime/60; % Plot results fig = figure(figNum); % Change the size of the figure fig.Position = fig.Position + [0, 0, 0, 200]; % Temperatures layoutResult = tiledlayout(3,1); nexttile plot(minutes, ... reshape(experience.Observation.obs1.Data(1,:,:), ... [1,length(experience.Observation.obs1.Data)]),"k") hold on plot(minutes, ... reshape(experience.Observation.obs1.Data(2,:,:), ... [1,length(experience.Observation.obs1.Data)]),"g") yline(comfortMin,'b') yline(comfortMax,'r') lgd = legend("T_{room}", "T_{outside}","T_{comfortMin}", ... "T_{comfortMax}","location","northoutside"); lgd.NumColumns = 4; title("Temperatures") ylabel("Temperature") xlabel("Time (minutes)") hold off % Total cost nexttile plot(totalCosts) title("Total Cost") ylabel("Energy cost") % Cost per step nexttile plot(costPerStep) title("Cost per step") ylabel("Energy cost") fprintf("Comfort Temperature violation:" + ... " %d/1440 minutes, cost: %f dollars\n", ... minutesViolateComfort, finalCost); end
Reference
[1] Du, Yan, Fangxing Li, Kuldeep Kurte, Jeffrey Munk, and Helia Zandi. “Demonstration of Intelligent HVAC Load Management With Deep Reinforcement Learning: Real-World Experience of Machine Learning in Demand Control.” IEEE Power and Energy Magazine 20, no. 3 (May 2022): 42–53. https://doi.org/10.1109/MPE.2022.3150825.
See Also
Functions
train|sim|rlSimulinkEnv
Objects
Topics
- House Heating System (Simscape)
- Train Default DQN Agent to Balance Discrete Cart-Pole
- Water Distribution System Scheduling Using Reinforcement Learning
- Compare Temperature Data from Three Different Days (ThingSpeak)
- Deep Q-Network (DQN) Agent
- Train Reinforcement Learning Agents
- Long Short-Term Memory Neural Networks