このページの内容は最新ではありません。最新版の英語を参照するには、ここをクリックします。
滑走ロボットを制御するための DDPG エージェントの学習
この例では、Simulink® でモデル化された、2 次元平面上を摩擦なしで滑走するロボット用の軌跡を生成するために、深層決定論的方策勾配 (DDPG) エージェントに学習させる方法を説明します。DDPG エージェントの詳細については、深層決定論的方策勾配 (DDPG) エージェントを参照してください。
再現性のための乱数ストリームの固定
サンプル コードには、さまざまな段階で乱数の計算が含まれる場合があります。サンプル コード内のさまざまなセクションの先頭にある乱数ストリームを固定すると、実行するたびにセクション内の乱数シーケンスが維持されるため、結果が再現される可能性が高くなります。詳細については、Results Reproducibilityを参照してください。
シード 0 で乱数ストリームを固定し、メルセンヌ・ツイスター乱数アルゴリズムを使用します。乱数生成に使用されるシード制御の詳細については、rngを参照してください。
previousRngState = rng(0,"twister");出力 previousRngState は、ストリームの前の状態に関する情報が格納された構造体です。例の最後で、状態を復元します。
滑走ロボット モデル
この例の強化学習環境は、半径 15 m のリング上のランダムな位置を初期状態とする滑走ロボットです。ロボットの向きもランダム化されます。ロボットには、その推進と操縦に使用される 2 つの推進機が本体側面に取り付けられています。学習の目標は、ロボットをその初期状態から原点まで駆動して東を向かせることです。
モデルを開きます。
mdl = "rlSlidingRobotEnv";
open_system(mdl)モデルの初期状態の変数を設定します。
theta0 = 0; x0 = -15; y0 = 0;
サンプル時間 Ts とシミュレーション期間 Tf を定義します。
Ts = 0.4; Tf = 30;
このモデルでは、次のようにします。
目標の向きは
0rad とする (ロボットが東を向く)。各アクチュエータの推力は、-1 ~ 1 N の範囲に制限する
環境からの観測値は、ロボットの位置、向き (向きの正弦と余弦)、速度、および角速度とする。
各タイム ステップで与えられる報酬 は次のとおりとする。
ここで、
は、x 軸上のロボットの位置。
は、y 軸上のロボットの位置。
は、ロボットの向き。
は、左の推進機からの制御操作。
は、右の推進機からの制御操作。
は、ロボットが目標に近づいた時の報酬。
は、ロボットが x 方向または y 方向に 20 m を超えて移動したときのペナルティ。シミュレーションは となったときに終了。
は、目標からの距離と制御操作に課される QR のペナルティ。
統合されたモデルの作成
SlidingRobotEnv モデル用のエージェントに学習させるには、createIntegratedEnv 関数を使用して、学習用に準備された RL Agent ブロックを含む Simulink モデルを自動生成します。
integratedMdl = "IntegratedSlidingRobot"; [~,agentBlk,obsInfo,actInfo] = ... createIntegratedEnv(mdl,integratedMdl);
アクションと観測値
環境オブジェクトを作成する前に、観測値とアクションの仕様の名前を指定し、推進アクションの範囲を -1 ~ 1 に制限します。
この環境の観測ベクトルは です。環境の観測チャネルに名前を割り当てます。
obsInfo.Name = "observations";この環境のアクション ベクトルは です。環境のアクション チャネルに、名前および上限と下限を割り当てます。
actInfo.Name = "thrusts";
actInfo.LowerLimit = -ones(prod(actInfo.Dimension),1);
actInfo.UpperLimit = ones(prod(actInfo.Dimension),1);prod(obsInfo.Dimension) および prod(actInfo.Dimension) は、行ベクトル、列ベクトル、行列のいずれによって構成されているかにかかわらず、それぞれ観測値と行動空間の次元の数を返すことに注意してください。
環境オブジェクトの作成
統合された Simulink モデルを使用して環境オブジェクトを作成します。
env = rlSimulinkEnv( ... integratedMdl, ... agentBlk, ... obsInfo, ... actInfo);
リセット関数
半径 15 m のリングに沿ってロボットの初期の位置をランダム化し、初期の向きもランダム化する、カスタムのリセット関数を作成します。リセット関数の詳細については、slidingRobotResetFcn を参照してください。
env.ResetFcn = @(in) slidingRobotResetFcn(in);
DDPG エージェントの作成
DDPG エージェントは、パラメーター化された Q 値関数近似器を使用して方策の価値を推定します。Q 値関数クリティックは、現在の観測値とアクションを入力として取り、単一のスカラーを出力として返します (状態からのアクションが与えられた割引累積長期報酬の推定値は、現在の観測値に対応し、その後の方策に従います)。
エージェントを作成すると、クリティック ネットワークの初期パラメーターがランダムな値で初期化されます。エージェントが常に同じパラメーター値で初期化されるように、乱数ストリームを固定します。
rng(0,"twister");パラメーター化された Q 値関数をクリティック内でモデル化するには、2 つの入力層 (そのうち 1 つは obsInfo で指定された観測チャネル用で、もう 1 つは actInfo で指定されたアクション チャネル用) と 1 つの出力層 (これはスカラー値を返します) をもつニューラル ネットワークを使用します。
各ネットワーク パスを layer オブジェクトの配列として定義します。各パスの入力層と出力層に名前を割り当てます。これらの名前を使用すると、パスを接続してから、ネットワークの入力層と出力層に適切な環境チャネルを明示的に関連付けることができます。
% Specify the number of outputs for the hidden layers. hiddenLayerSize = 128; % Define observation path layers observationPath = [ featureInputLayer(prod(obsInfo.Dimension),Name="obsInLyr") concatenationLayer(1,2,Name="cat") fullyConnectedLayer(hiddenLayerSize) reluLayer fullyConnectedLayer(hiddenLayerSize) reluLayer fullyConnectedLayer(hiddenLayerSize) reluLayer fullyConnectedLayer(1,Name="fc4") ]; % Define action path layers actionPath = featureInputLayer( ... prod(actInfo.Dimension), ... Name="actInLyr");
dlnetwork オブジェクトを組み立てます。
criticNetwork = dlnetwork(); criticNetwork = addLayers(criticNetwork,observationPath); criticNetwork = addLayers(criticNetwork,actionPath);
actionPath を observationPath に接続します。
criticNetwork = connectLayers(criticNetwork,"actInLyr","cat/in2");
ネットワークを初期化し、パラメーターの数を表示します。
criticNetwork = initialize(criticNetwork); summary(criticNetwork)
Initialized: true
Number of learnables: 34.4k
Inputs:
1 'obsInLyr' 7 features
2 'actInLyr' 2 features
criticNetwork、環境仕様、および観測チャネルとアクション チャネルに接続するネットワーク入力層の名前を使用して、クリティックを作成します。詳細については、rlQValueFunctionを参照してください。
critic = rlQValueFunction(criticNetwork,obsInfo,actInfo,... ObservationInputNames="obsInLyr",ActionInputNames="actInLyr");
DDPG エージェントは、連続行動空間において、パラメーター化された決定論的方策を使用します。この方策は、連続決定論的アクターによって学習されます。このアクターは、現在の観測値を入力として取り、観測値の決定論的関数であるアクションを出力として返します。
パラメーター化された方策をアクター内でモデル化するには、1 つの入力層 (これは、obsInfo で指定された、環境観測チャネルのコンテンツを受け取ります) と 1 つの出力層 (これは、actInfo で指定された、環境アクション チャネルへのアクションを返します) をもつニューラル ネットワークを使用します。
ネットワークを layer オブジェクトの配列として定義します。
actorNetwork = [
featureInputLayer(prod(obsInfo.Dimension))
fullyConnectedLayer(hiddenLayerSize)
reluLayer
fullyConnectedLayer(hiddenLayerSize)
reluLayer
fullyConnectedLayer(hiddenLayerSize)
reluLayer
fullyConnectedLayer(prod(actInfo.Dimension))
tanhLayer
];layer オブジェクトの配列を dlnetwork オブジェクトに変換し、ネットワークを初期化し、パラメーターの数を表示します。
actorNetwork = dlnetwork(actorNetwork); actorNetwork = initialize(actorNetwork); summary(actorNetwork)
Initialized: true
Number of learnables: 34.3k
Inputs:
1 'input' 7 features
actorNetwork、およびアクション チャネルと観測チャネルの仕様を使用して、アクターを定義します。詳細については、rlContinuousDeterministicActorを参照してください。
actor = rlContinuousDeterministicActor(actorNetwork,obsInfo,actInfo);
rlOptimizerOptionsを使用して、クリティックとアクターのオプションを指定します。
criticOptions = rlOptimizerOptions( ... LearnRate=1e-03, ... GradientThreshold=5); actorOptions = rlOptimizerOptions( ... LearnRate=1e-03, ... GradientThreshold=5);
rlDDPGAgentOptionsを使用して、DDPG エージェントのオプション (アクターとクリティックの学習オプションなど) を指定します。
agentOptions = rlDDPGAgentOptions(... SampleTime=Ts,... ActorOptimizerOptions=actorOptions,... CriticOptimizerOptions=criticOptions,... ExperienceBufferLength=1e6 ,... TargetSmoothFactor=1e-3,... MiniBatchSize=512,... MaxMiniBatchPerEpoch=50); % Gaussian noise agentOptions.NoiseOptions.MeanAttractionConstant = 1/Ts; agentOptions.NoiseOptions.StandardDeviation = 1e-1; agentOptions.NoiseOptions.StandardDeviationMin = 1e-2; agentOptions.NoiseOptions.StandardDeviationDecayRate = 1e-6;
次に、アクター、クリティック、およびエージェントのオプションを使用して、エージェントを作成します。詳細については、rlDDPGAgentを参照してください。
agent = rlDDPGAgent(actor,critic,agentOptions);
または、最初にエージェントを作成してから、ドット表記を使用してそのオプション オブジェクトにアクセスしてオプションを変更することもできます。
エージェントの学習
エージェントに学習させるには、まず、学習オプションを指定します。この例では、次のオプションを使用します。
最大
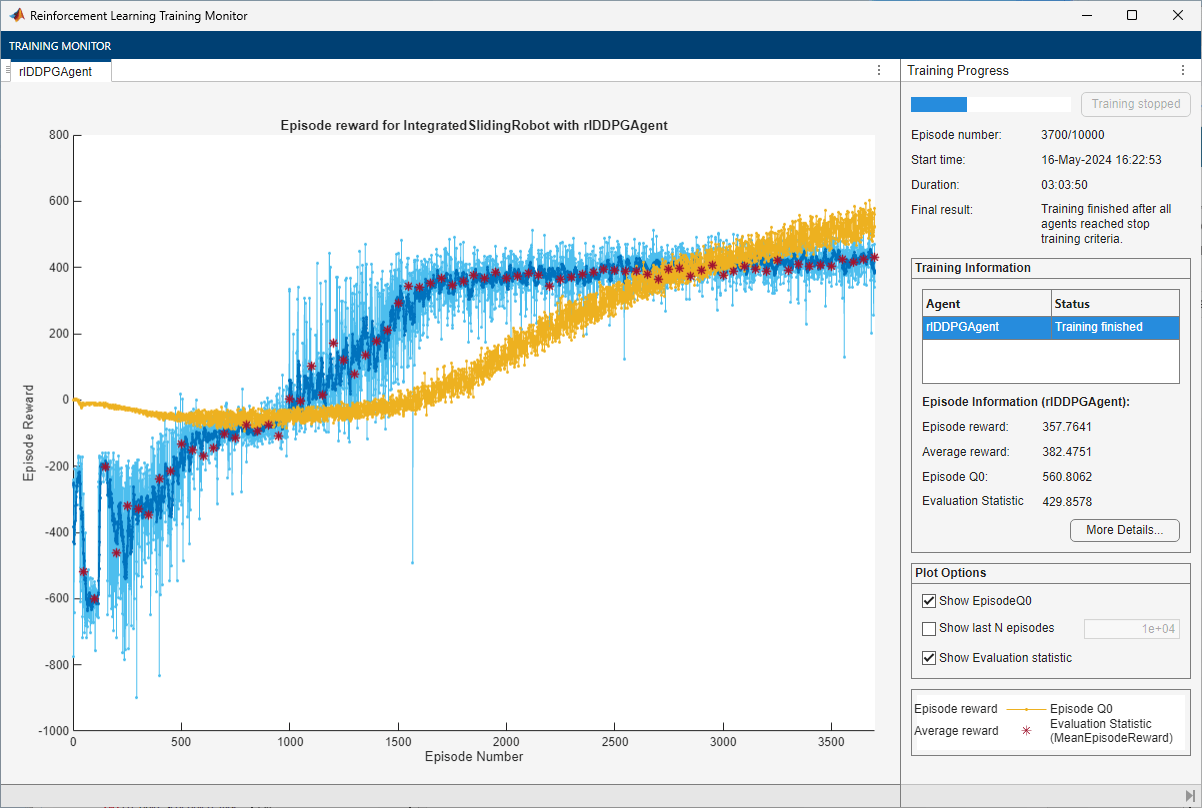
10000個のエピソードについて、各学習を実行 (各エピソードの持続時間は最大ceil(Tf/Ts)タイム ステップ)。強化学習の学習モニターで学習の進行状況を表示し (
Plotsオプションを設定)、コマンド ラインの表示を無効化 (Verboseオプションをfalseに設定)。5 回のシミュレーションの累積報酬を平均化し、50 回の学習エピソードごとに学習済みの貪欲方策を評価。
評価エピソード中に取得された平均累積報酬が
425を超えたときに、エージェントの学習を停止。この時点で、エージェントは滑走ロボットを目標位置に駆動できる。
学習オプションの詳細については、rlTrainingOptionsを参照してください。
maxepisodes = 10000; maxsteps = ceil(Tf/Ts); trainingOptions = rlTrainingOptions(... MaxEpisodes=maxepisodes,... MaxStepsPerEpisode=maxsteps,... StopOnError="on",... Verbose=false,... Plots="training-progress",... StopTrainingCriteria="EvaluationStatistic",... StopTrainingValue=425,... ScoreAveragingWindowLength=10); % agent evaluator evl = rlEvaluator(EvaluationFrequency=50,NumEpisodes=5);
再現性のために乱数ストリームを固定します。
rng(0,"twister");関数 train を使用して、エージェントに学習させます。学習は計算量が多いプロセスのため、完了するのに数時間かかります。この例の実行時間を節約するために、doTraining を false に設定して事前学習済みのエージェントを読み込みます。エージェントに学習させるには、doTraining を true に設定します。
doTraining =false; if doTraining % Train the agent. trainingStats = train(agent,env,trainingOptions,Evaluator=evl); else % Load the pretrained agent for the example. load("SlidingRobotDDPG.mat","agent") end
DDPG エージェントのシミュレーション
再現性のために乱数ストリームを固定します。
rng(0,"twister");学習済みエージェントの性能を検証するには、環境内でこのエージェントをシミュレートします。エージェントのシミュレーションの詳細については、rlSimulationOptions および sim を参照してください。
simOptions = rlSimulationOptions(MaxSteps=maxsteps); experience = sim(env,agent,simOptions);
previousRngState に保存されている情報を使用して、乱数ストリームを復元します。
rng(previousRngState);
参考
関数
オブジェクト
rlDDPGAgent|rlDDPGAgentOptions|rlQValueFunction|rlContinuousDeterministicActor|rlTrainingOptions|rlSimulationOptions|rlOptimizerOptions
ブロック
トピック
- 連続カートポールの振り上げと平衡化のための既定の DDPG エージェントの学習
- 振子の振り上げと平衡化のための、イメージ観測を使用した DDPG エージェントの学習
- Train Default PPO Agent for Discrete Lander Vehicle
- Trajectory Optimization and Control of Sliding Robot Using Nonlinear MPC (Model Predictive Control Toolbox)
- Create Custom Simulink Environments
- 深層決定論的方策勾配 (DDPG) エージェント
- Train Reinforcement Learning Agents